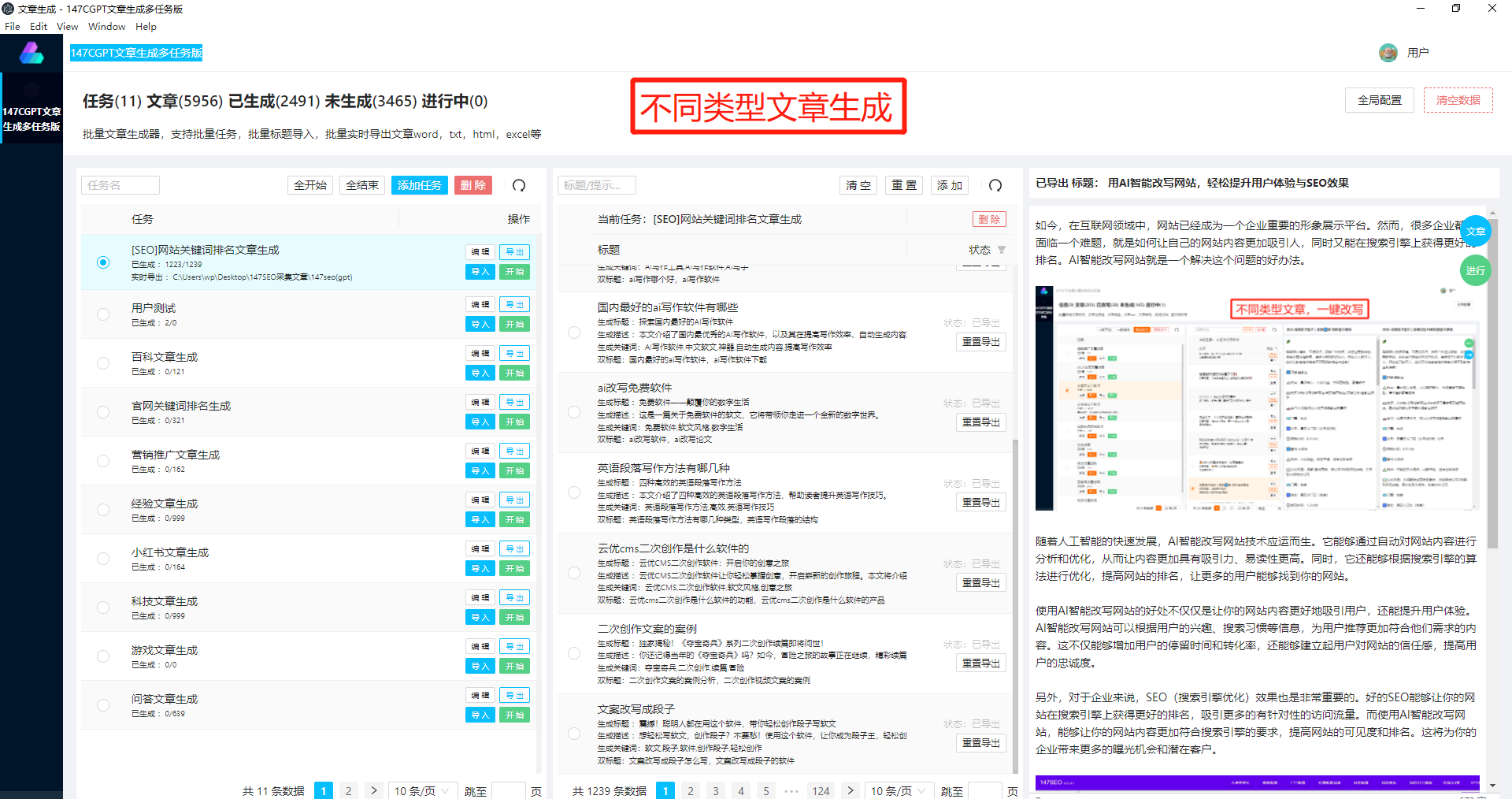
近年来,人工智能技术取得了飞速的发展,其中自然语言处理领域的研究也日新月异。GPT-2(Generative Pre-trained Transformer 2)作为最近备受瞩目的文本生成模型,是否支持中文成为了不少人关注的焦点。
GPT-2是由OpenAI机构所开发的一种基于Transformer结构的预训练模型。它在大规模无监督语料上进行预训练,然后可以通过微调的方式适应特定任务,如文本生成、翻译和摘要等。尽管GPT-2最初是为英文设计的,但经过一系列的研究与改进,如今已经能够支持中文语言的处理。
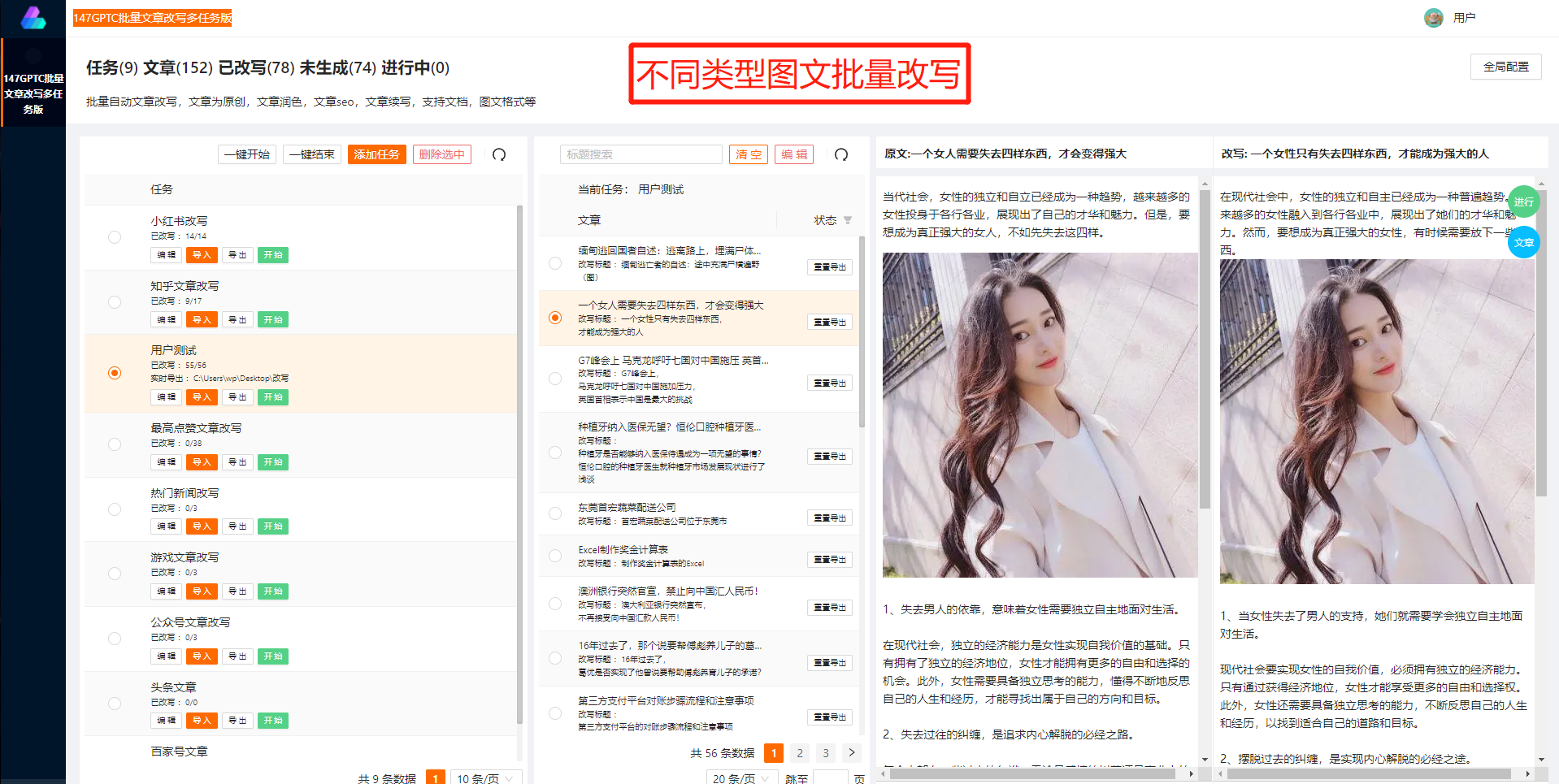
在中文环境中,GPT-2模型能够实现多种自然语言处理任务。一方面,它可以用于文本生成,例如自动摘要、新闻生成和对话系统。通过使用大规模中文语料进行预训练,GPT-2可以生成通顺、连贯且语法正确的中文文本。不仅如此,GPT-2还能够根据上下文的语境生成合理的答案,使得对话更加流畅自然。
另一方面,GPT-2还可以用于中文文本的情感分析和文本分类。借助于预训练得到的语言模型,GPT-2可以对中文文本进行情感极性的判断,帮助用户了解一段文本背后蕴含的情感色彩。GPT-2还可以通过微调的方式,将其用于中文文本的分类任务,例如新闻分类和评论分析等。这使得GPT-2在中文环境中得到了广泛的应用。
除此之外,GPT-2还可以被用于中英文之间的翻译。通过在中文和英文平行语料上进行预训练,GPT-2能够理解中英文之间的对应关系,并且在两种语言之间进行准确的翻译。这对于跨文化交流和信息传递具有重要意义,为中文用户提供了更好的翻译工具。
GPT-2模型在中文环境中应用也面临一些挑战和局限。相比于英文,中文的语法结构更加复杂,词汇编码难度更大,这给模型的训练和推理带来了一定的困难。由于GPT-2是基于大规模无监督语料进行预训练的,如果缺乏领域特定的微调数据,其性能可能会有所下降。GPT-2模型在处理长文本时,可能会出现信息遗忘或信息重复的问题,这也是需要进一步改进的方向。
GPT-2的发展为中文自然语言处理和文本生成带来了新的机遇。借助于GPT-2,在中文环境中的文本生成、情感分析、文本分类和机器翻译等任务上取得了初步的成功。随着对GPT-2模型的深入研究和改进,相信它在中文领域的应用将会越来越广泛,为人们带来更多便利与创新。