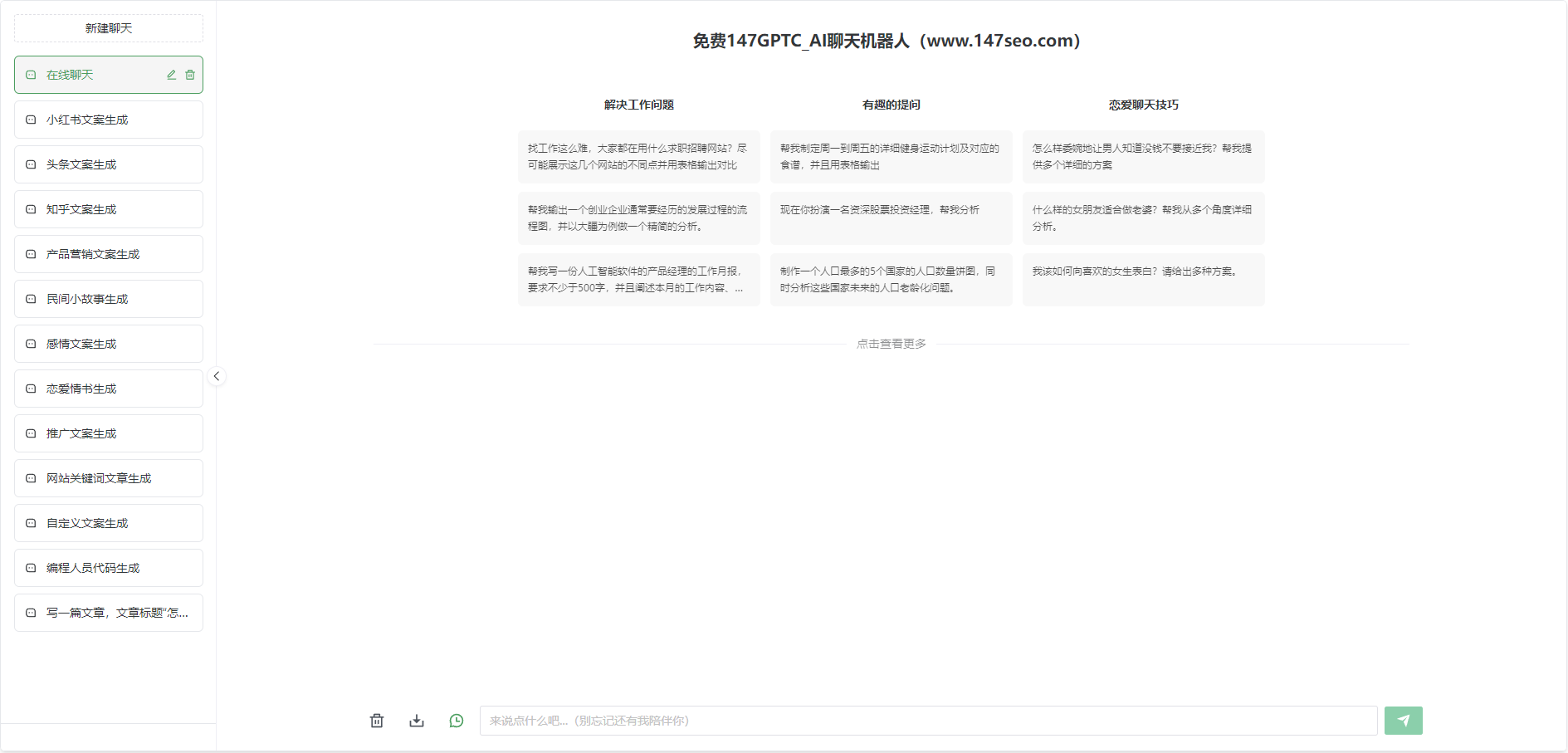
随着人工智能技术的不断发展,文本生成技术在近年来取得了令人瞩目的进展。在这一领域中,中文GPT-2作为最具代表性和突破性的模型之一,引起了广泛关注。本文将深入揭秘中文GPT-2的训练方法,带您了解这一技术的背后奥秘。
中文GPT-2,即中文生成对抗网络(Chinese Generative Pre-trained Transformer 2),是由深度学习与自然语言处理领域的专家共同研发的一种文本生成模型。与传统的基于规则或模板的方法相比,中文GPT-2利用深度学习的方法进行训练,可以自动学习文本背后的模式和规律,实现更加灵活和自然的文本生成。由于其出色的性能和广泛的应用前景,中文GPT-2在学术界和工业界都得到了高度评价。
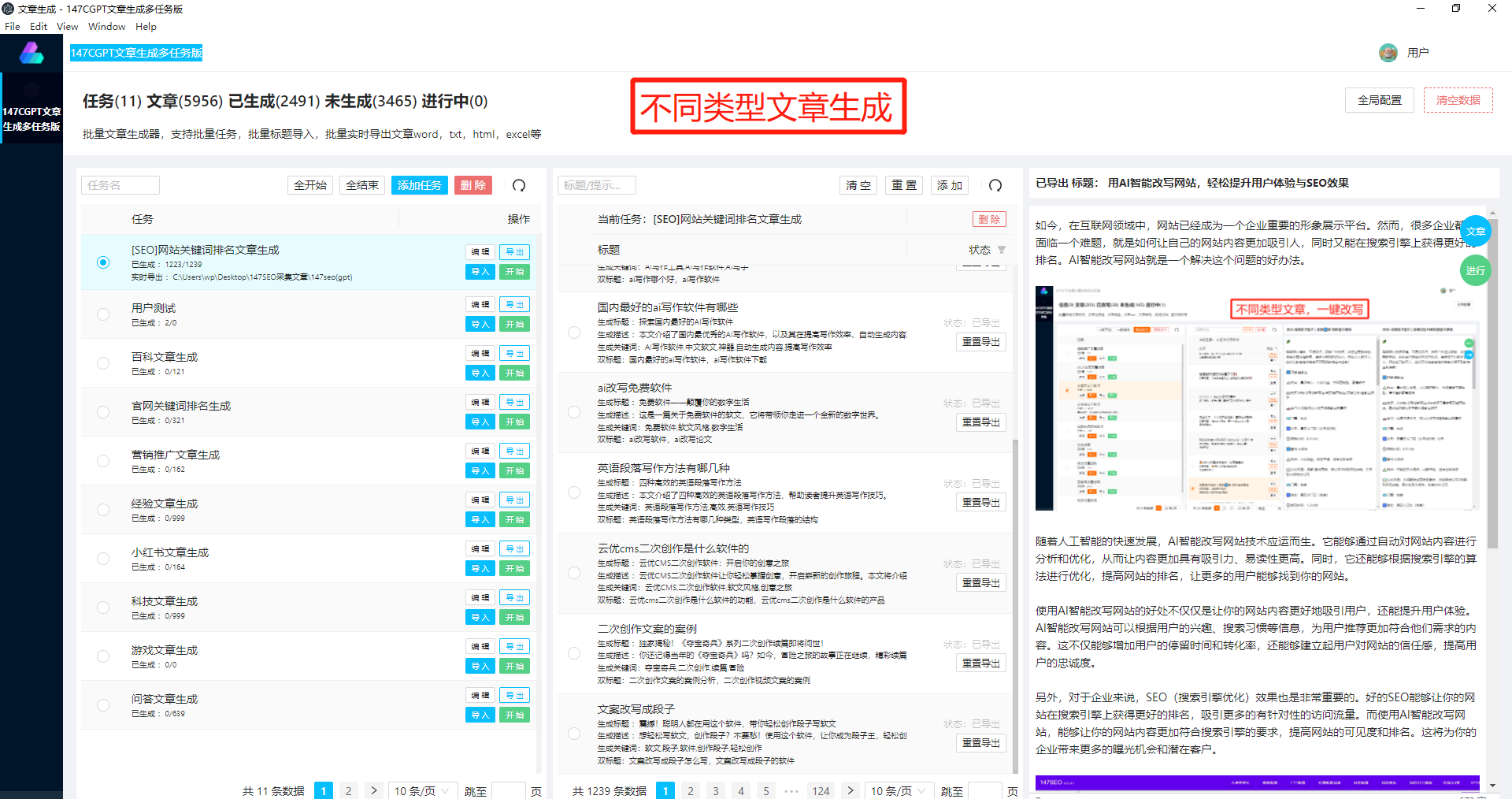
中文GPT-2的训练方法包括两个核心环节:预训练和微调。在预训练阶段,模型利用大规模的文本数据进行深度学习,提取文字特征并学习词、句子和文档之间的语义关系。这一过程相当于给模型提供了一个庞大的中文知识库,使其能够更好地理解和生成中文文本。在预训练之后,模型还需要通过微调的方式进行进一步优化,以适应特定的应用场景和任务需求。
为了训练中文GPT-2模型,研究人员需要收集大规模的中文文本数据,并进行数据清洗和预处理。这些数据可以包括新闻、论坛帖子、小说、博客文章等各种类型的中文文本。在预处理阶段,研究人员还需要对文本进行分词、去除停用词和标点符号等操作,以便模型更好地理解和处理中文文本。对于一些特定领域的应用,如医学、金融或规则等,还可以引入领域相关的专业文本进行训练,以提高模型在这些领域的应用性能。
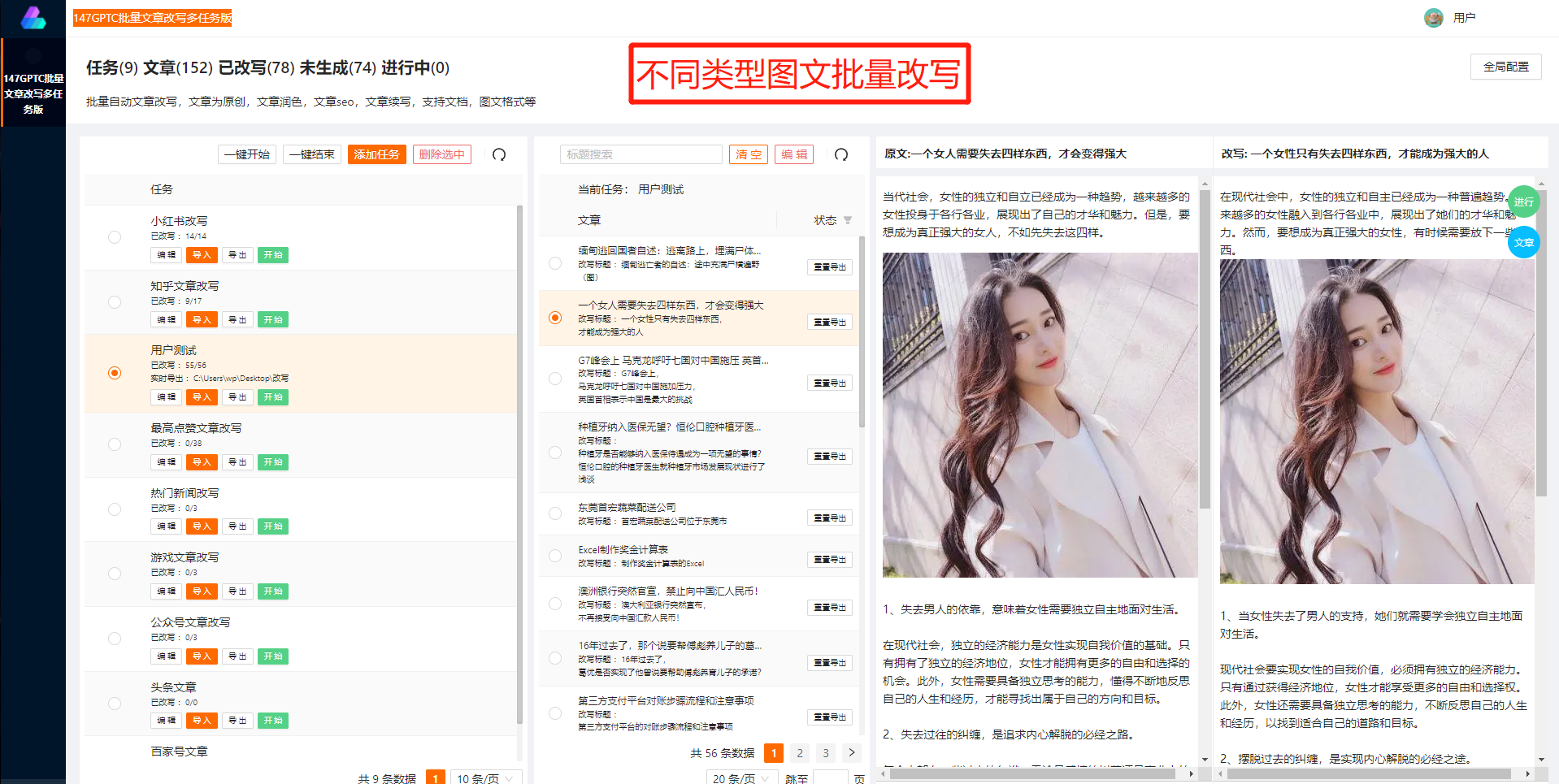
随着训练数据的准备完成,研究人员可以利用深度学习框架(如TensorFlow或PyTorch)来训练中文GPT-2模型。训练过程通常需要大量的计算资源和时间,因为模型参数非常庞大,需要进行大量的迭代和调优。为了提高训练效果,研究人员还可以采用一些技巧,如使用更大的模型、调整超参数或应用迁移学习等方法。
中文GPT-2的训练方法不仅仅是一种技术手段,更是文本生成领域的重要里程碑。它为我们开启了深度学习与人工智能在文本生成领域的新纪元。中文GPT-2的成功应用不仅提升了研究人员在文本生成领域的技术水平,也为广大用户带来了更好的文本生成工具和体验。
中文GPT-2的训练方法为我们展示了人工智能技术的巨大潜力和应用前景。通过深度学习的训练方法,我们可以实现更加智能、自然和高效的中文文本生成。相信在不久的将来,中文GPT-2将在各个领域发挥更加重要的作用,为人们的生活带来更多便利和创新。