
在互联网时代,数据是无处不在的。然而,有些网站使用动态网页技术,使得数据无法通过传统的静态页面爬取方式获取。那么如何爬取动态网页数据呢?本文将为大家介绍几种常用的方法和技巧。
一、使用爬虫工具 爬虫工具是获取网页数据的有效助手。有许多强大的爬虫工具可供选择,如Scrapy、BeautifulSoup等。这些工具使用Python编写,并提供了丰富的功能和插件。通过这些工具,我们可以灵活地爬取动态网页数据,并进行数据处理和分析。
二、分析Ajax请求 动态网页常常使用Ajax技术来加载数据,通过分析Ajax请求,我们可以获取到所需的数据。打开浏览器的开发者工具,切换到网络(Network)选项卡,找到对应的Ajax请求,复制其URL和请求参数。然后可以使用爬虫工具发送HTTP请求获取数据,再根据需要进行解析和处理。
三、使用Selenium模拟浏览器行为 有些动态网页使用JavaScript生成数据,此时可以使用Selenium模拟浏览器行为。Selenium是一个自动化测试工具,可以模拟用户在浏览器中的操作。通过Selenium,我们可以加载并执行页面JavaScript,获取到数据。但需要注意的是,Selenium的运行速度较慢,适用于数据量较少的情况。
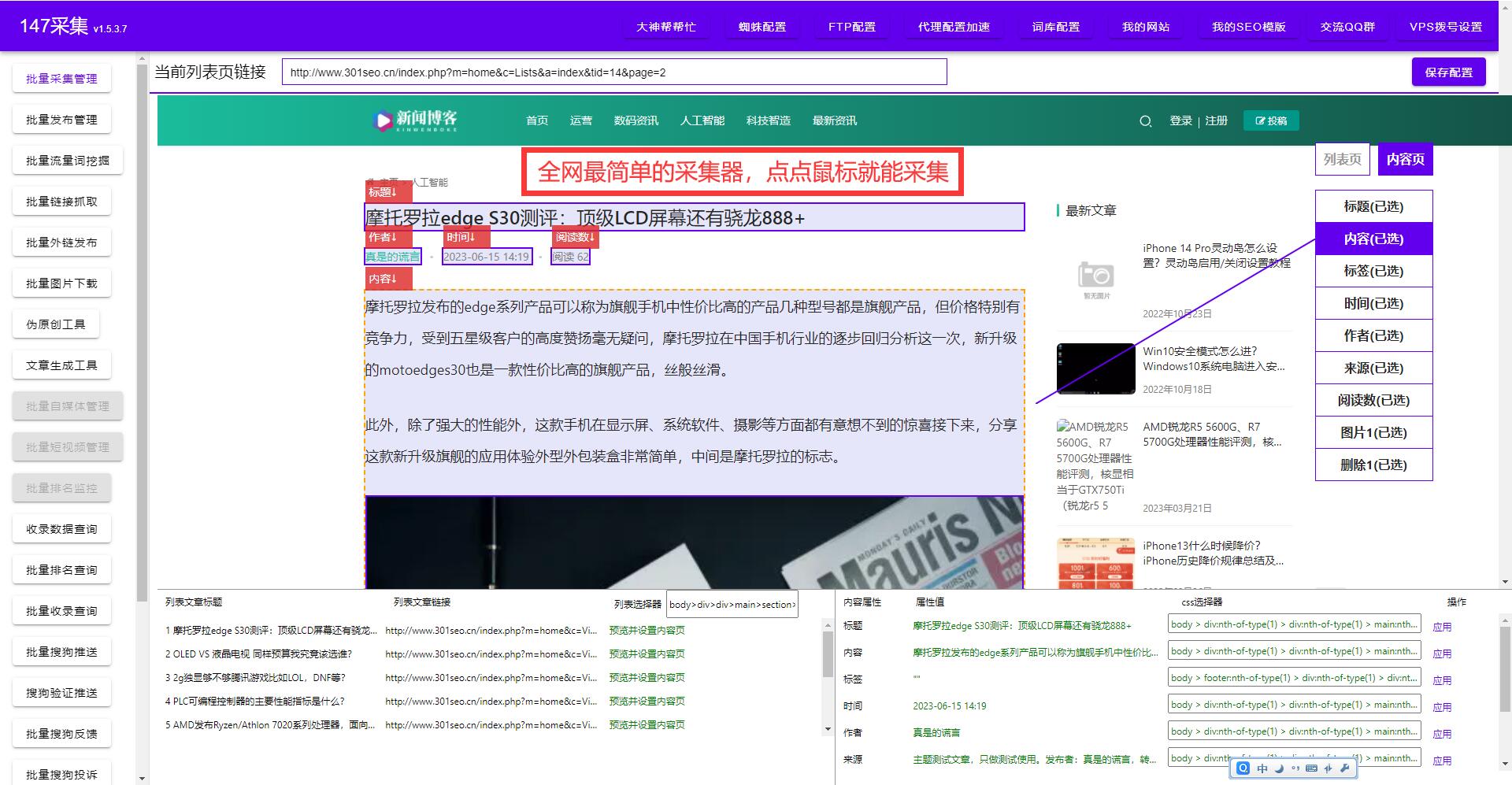
四、解析页面源代码 动态网页的数据通常都会在返回的页面源代码中。可以利用正则表达式或者XPath来提取需要的数据。正则表达式适用于简单的数据提取,而XPath则更为强大灵活。通过解析页面源代码,我们可以快速获取到所需的数据。
总结: 通过爬虫工具、分析Ajax请求、使用Selenium模拟浏览器行为以及解析页面源代码等方法,我们可以有效地爬取动态网页数据。在实际操作过程中,需要根据具体情况选择适当的方法和技巧。同时,需要注意合法获取数据的问题,遵循相关规则法规和网站的规定。希望本文对大家在动态网页数据爬取方面有所帮助。



