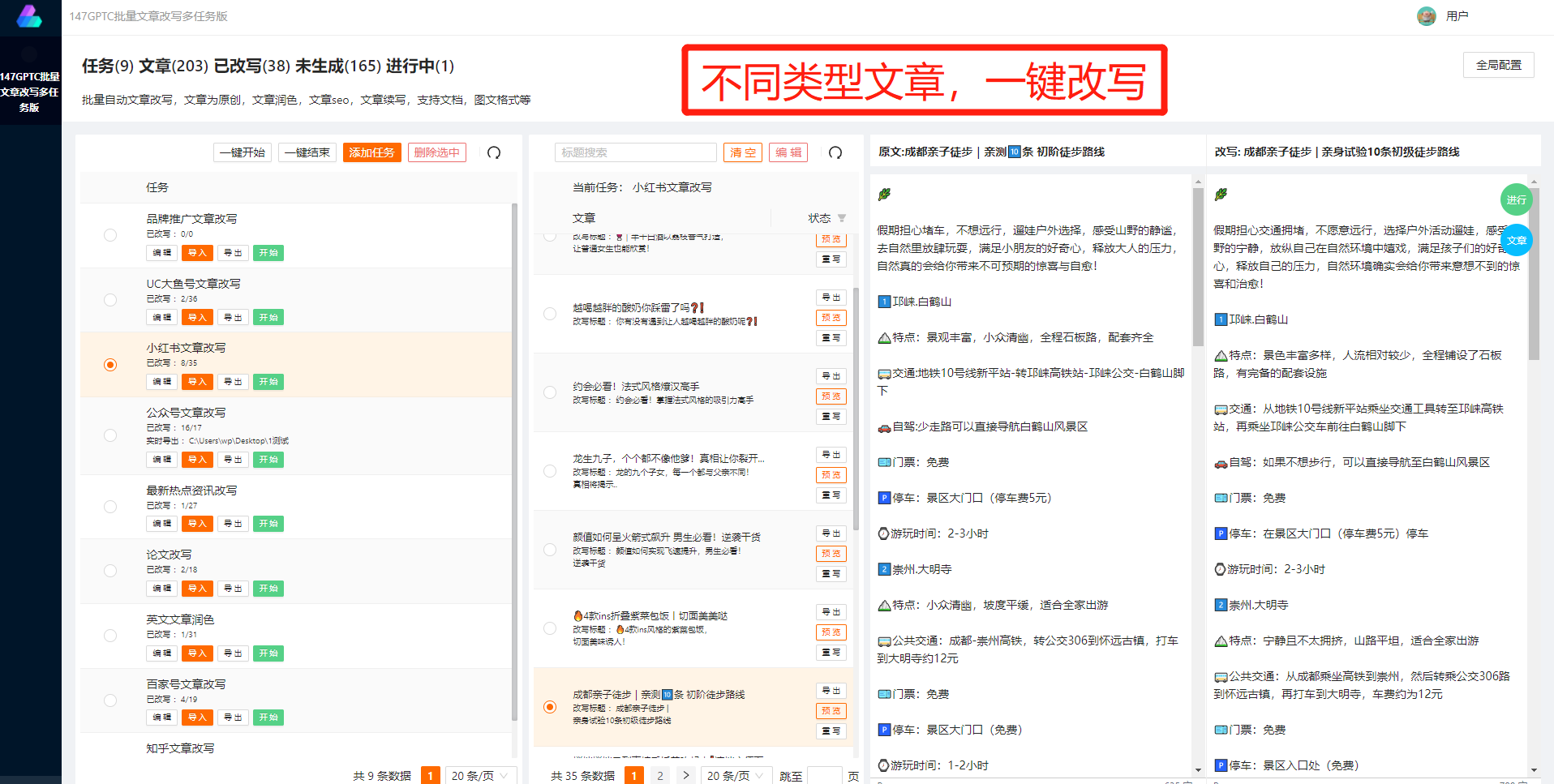
在当今信息时代,海量数据的获取对于许多企业和个人非常重要。而网页是一个丰富的数据来源,通过爬虫技术可以快速地爬取所需的网页数据。本文将介绍如何使用Python编程语言来实现高效的网页数据爬取,并通过邮件发送获取到的数据。
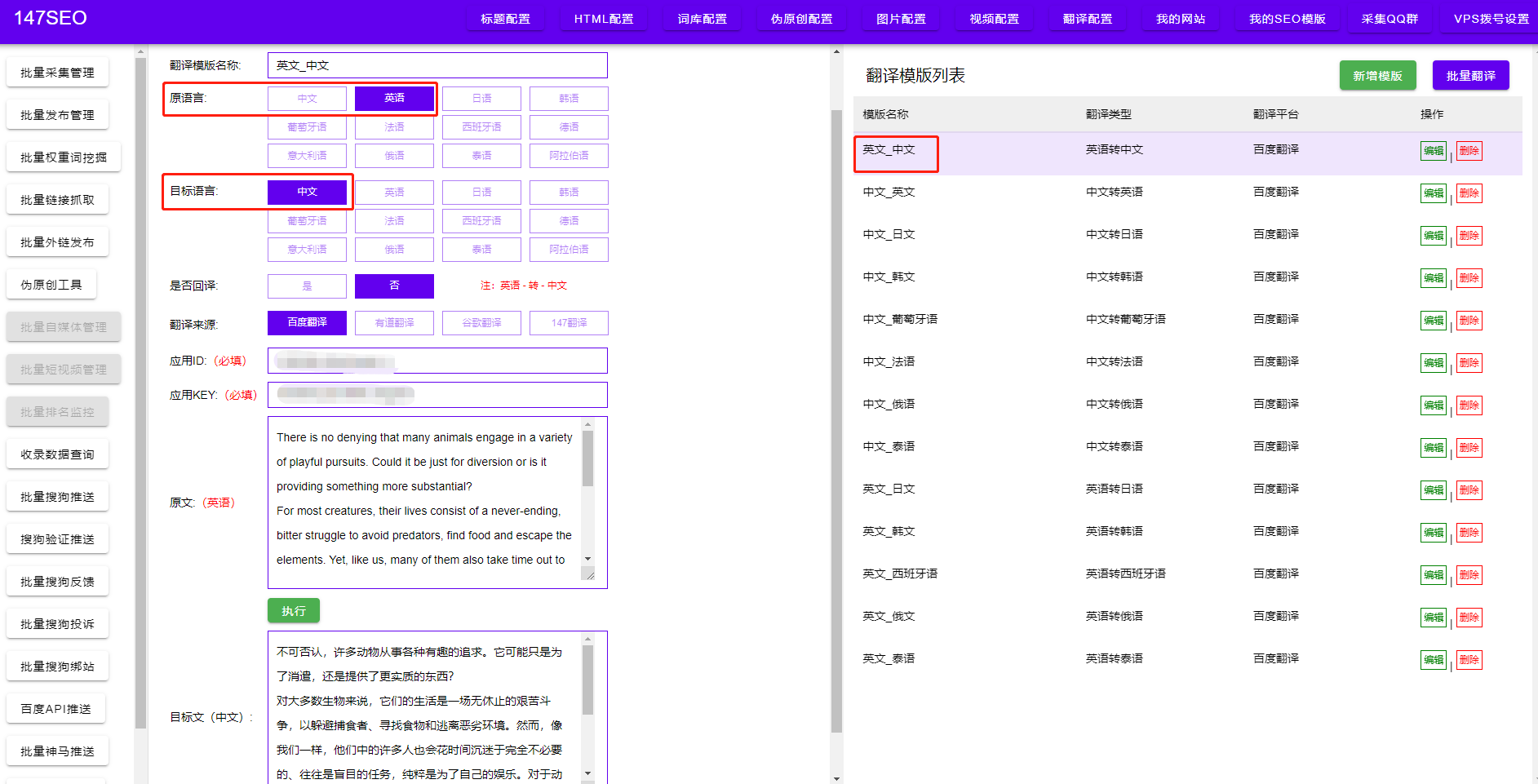
首先,我们需要明确爬取的目标是什么样的网页数据。根据需求,我们可以选择使用Python中的一些开源的爬虫框架,例如Scrapy或BeautifulSoup。这些框架提供了丰富的功能和工具,可以帮助我们快速地爬取网页数据。
其次,我们需要分析目标网页的结构和规律,以确定如何编写爬虫代码。通常,我们可以通过查看网页的HTML源代码来找到所需数据的标签和属性。然后,使用Python的爬虫框架来解析HTML,并提取目标数据。
一旦我们成功爬取到所需的网页数据,就可以使用Python的邮件库来发送这些数据。可以通过设置邮件的发送者、接收者、主题和正文等信息,将数据以邮件形式发送出去。这对于需要定时获取网页数据并及时送达的应用非常有用。
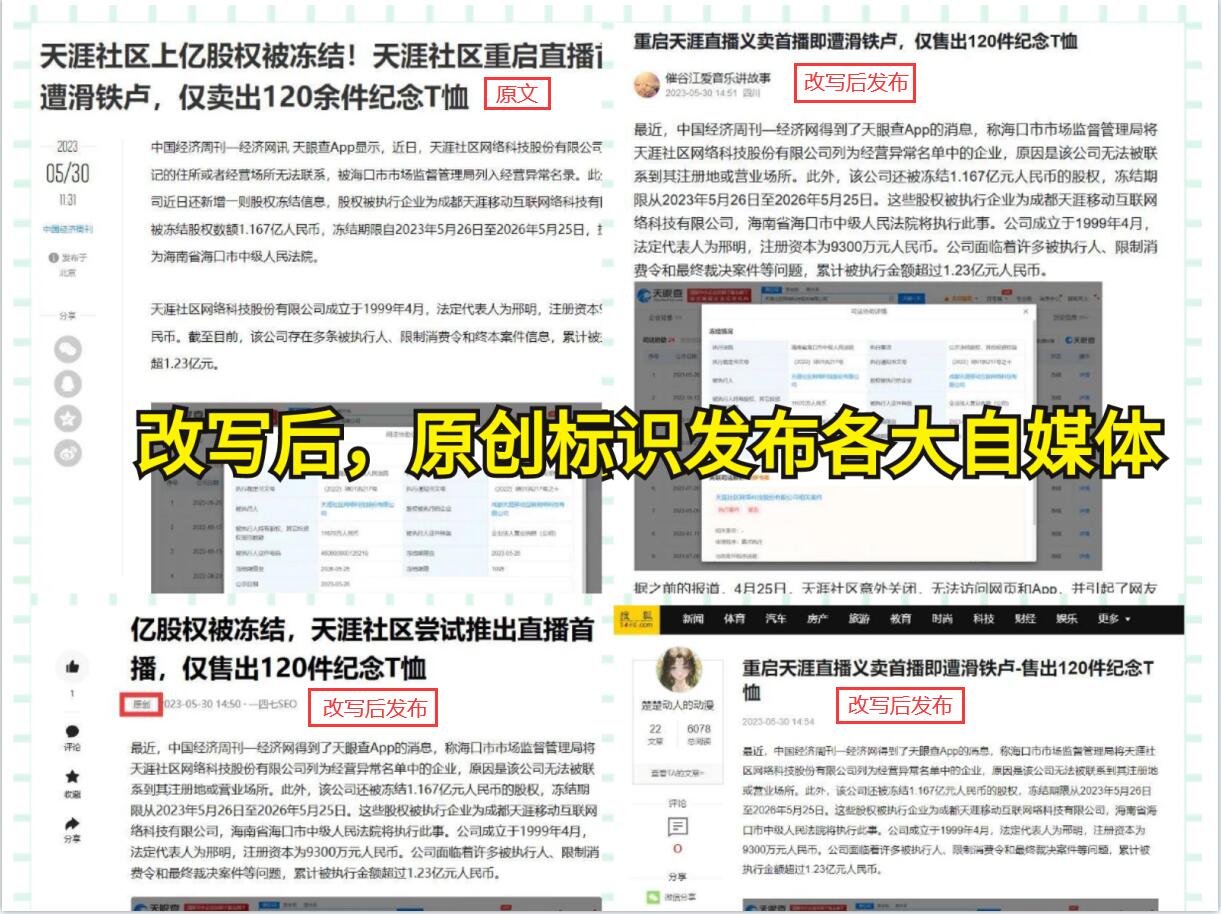
Python的邮件库还可以实现附件的发送,这意味着我们不仅可以将数据以文本的形式发送,也可以将数据以文件的形式作为附件发送。这对于大量的数据或者需要特殊处理的数据非常方便。
在实际应用中,我们可以结合定时任务、定时爬取和定时发送邮件的方式,来实现自动化的数据获取和发送。这样,我们就能够高效地获取网页数据,并及时将其发送给需要的人员。
综上所述,通过使用Python爬虫技术,我们能够以高效的方式爬取网页数据,并通过邮件发送给需要的人员。这为企业和个人提供了一个方便快捷的数据获取和共享方式。希望本文对大家了解Python爬虫和邮件发送的使用有所帮助。