
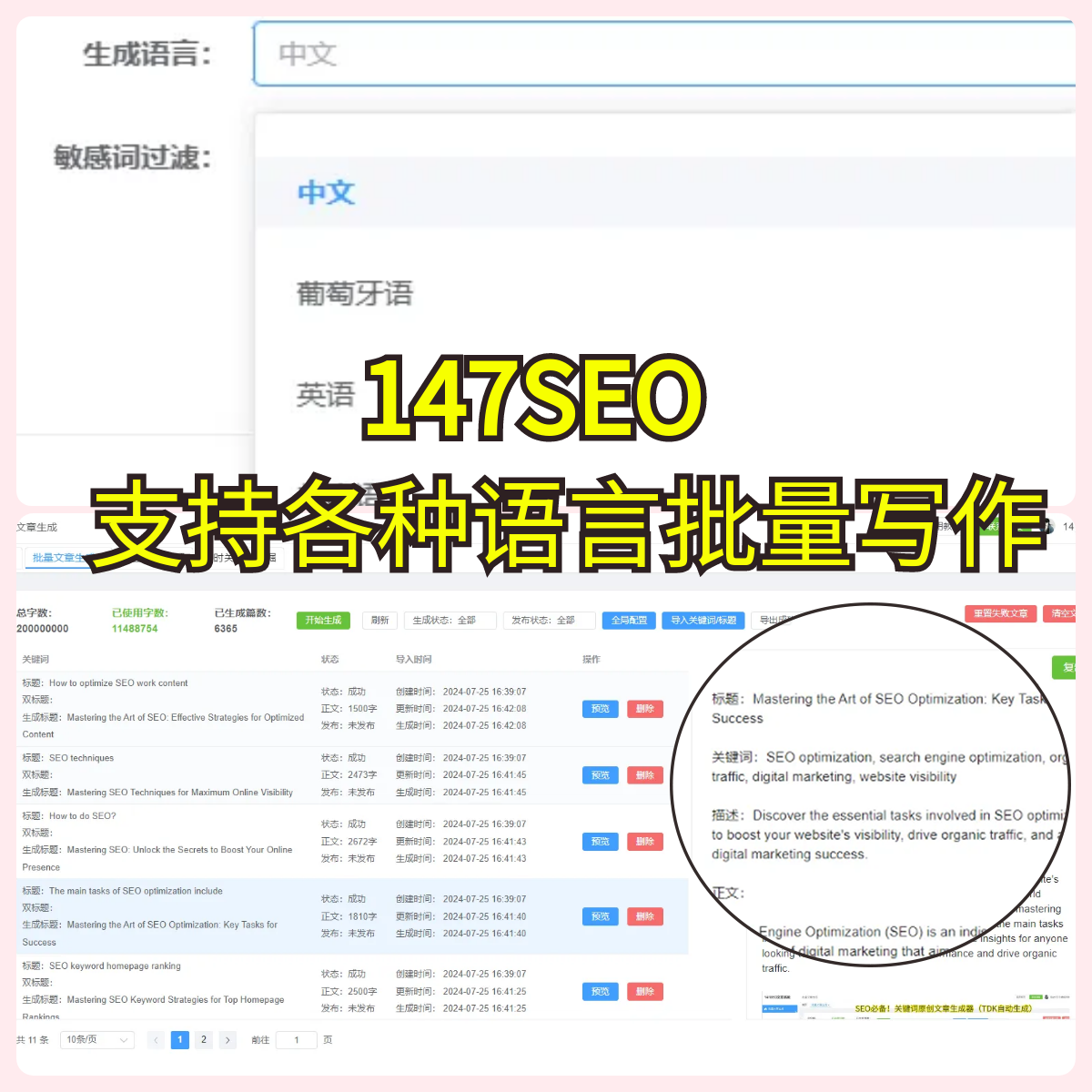
你是否曾经遇到过这样一个情况:某个网站的IP数量远远超过了它的访客数?比如,一个网站的独立访客数只有100人,而它的IP访问量却达到了10000多次。大家一定会感到困惑:“这个差距怎么回事?是网站遭遇了什么攻击,还是有其他原因?”其实,这种现象并不罕见,背后隐藏着一系列的技术原因。今天,我们就来一竟,看看网站IP与访客数量之间的巨大差距背后,究竟暗藏了哪些“玄机”。

1. 同一访客的多次访问
很多网站的访问量看似很高,实际上是因为同一个访客在短时间内多次访问了网站。这种情况特别常见于一些内容更新频繁、用户互动较多的网站。比如,某些用户可能因为好奇或需要频繁刷新页面,导致他们的每一次刷新都会被记录为一次新的访问。这时,虽然独立访客数保持不变,但IP访问量却因为频繁刷新而剧增。

解决方案:如果你发现自己的网站存在这种情况,可以考虑引入“访客识别”技术。通过这一技术,系统能够识别同一个用户的多次访问,从而精准统计独立访客数,而不会被重复的访问行为误导。
2. 爬虫和机器人访问
在互联网的世界里,爬虫和机器人是非常常见的存在。这些自动化的程序会定期访问网站,抓取页面内容或者执行一些特定任务。这些爬虫和机器人的访问量往往会非常高,甚至超过了正常的用户访问量。尽管这些程序并没有实际的人类访问背后,仍然会被统计为IP访问,导致IP数量远超独立访客。
解决方案:为了应对这种情况,可以通过设置防爬虫机制来减少这些机器人的访问。例如,通过机器人协议文件(robots.txt)来告知搜索引擎哪些页面不允许爬虫抓取,或者通过验证码、IP限制等方式来有效屏蔽非人工访问。

3. CDN(内容分发网络)的影响
如果你的网站使用了CDN加速服务,那么它的访问量可能会出现失真现象。CDN的作用是将网站内容缓存到全球多个节点,用户访问时,数据从离他们最近的服务器提供,而非直接从原始服务器获取。这种机制虽然大大加速了网站的加载速度,但也可能导致同一个用户访问时,产生多个不同的IP记录,从而大大增加了网站的IP访问量。

解决方案:如果你的网站使用CDN,可以通过调整访问日志的记录方式,来过滤掉CDN节点的影响,确保统计数据更准确。也可以定期监控CDN节点的访问情况,避免异常流量的影响。
4. 网站防护机制与缓存机制
很多网站都使用了反向代理服务器、负载均衡、或者其他防护系统来提高安全性和稳定性。这些机制会缓存用户的请求,减少对源服务器的直接访问。这种缓存可能会导致不同的请求被记录为不同的IP访问,而实际上它们可能来自同一个用户。
解决方案:可以根据需求调整缓存策略,或者通过增强网站的防护能力,确保这些缓存不会影响到真实访客的统计结果。
5. 误报与统计工具的差异
有时候,网站使用的分析工具或统计平台可能存在一些误报的情况。这些工具在记录访客的IP时,可能没有准确区分真实用户与机器访问,导致统计结果偏高。例如,某些工具在分析时将一个网络内的大量访问归类为同一个IP,或者错误地记录了某些内网的访问。
解决方案:选择可靠的流量分析工具,并定期检查这些工具的配置和准确性。如果可能的话,可以使用多个不同的数据源来交叉验证网站的真实流量情况。
总结
一个网站IP数量比访客数量多得多的情况,其实是一个非常常见的问题,通常由多种因素叠加造成。在面对这种情况时,网站运营者需要认真分析,找出背后的原因,并采取相应的措施来改进数据统计的准确性。最终,精准的数据统计对于网站运营和优化来说是至关重要的,它可以帮助你更好地了解用户行为,进而做出更有针对性的调整。
正如一句名言所说:“数据不会说谎,只有人类误读数据。”每一份数据背后,都藏着深刻的故事,我们需要用心去解读,才能获得真正的价值。
相关问答推荐:
问:为什么同一个访客会被统计为多个IP? 答:同一个访客在访问网站时,可能因为刷新页面、使用CDN等原因,造成访问记录中出现多个IP。通过合理的访客识别和数据过滤,可以避免这种情况对统计结果的影响。
问:如何判断网站的流量是不是正常的? 答:可以通过对比独立访客数和IP访问量的比例,结合访问来源、页面加载速度等多种因素,来判断流量是否正常。如果发现异常,及时检查爬虫、缓存等因素是否影响了数据。


