
网络成为了人们获取信息、交流思想的主要平台。随着网络的普及和便利,原创文章的抄袭、剽窃问题也愈发严重。这不仅侵犯了原作者的知识产权,也扰乱了网络生态的健康发展。为了解决这一问题,原创文章检测应运而生,成为了维护网络秩序、保护知识产权的重要工具。
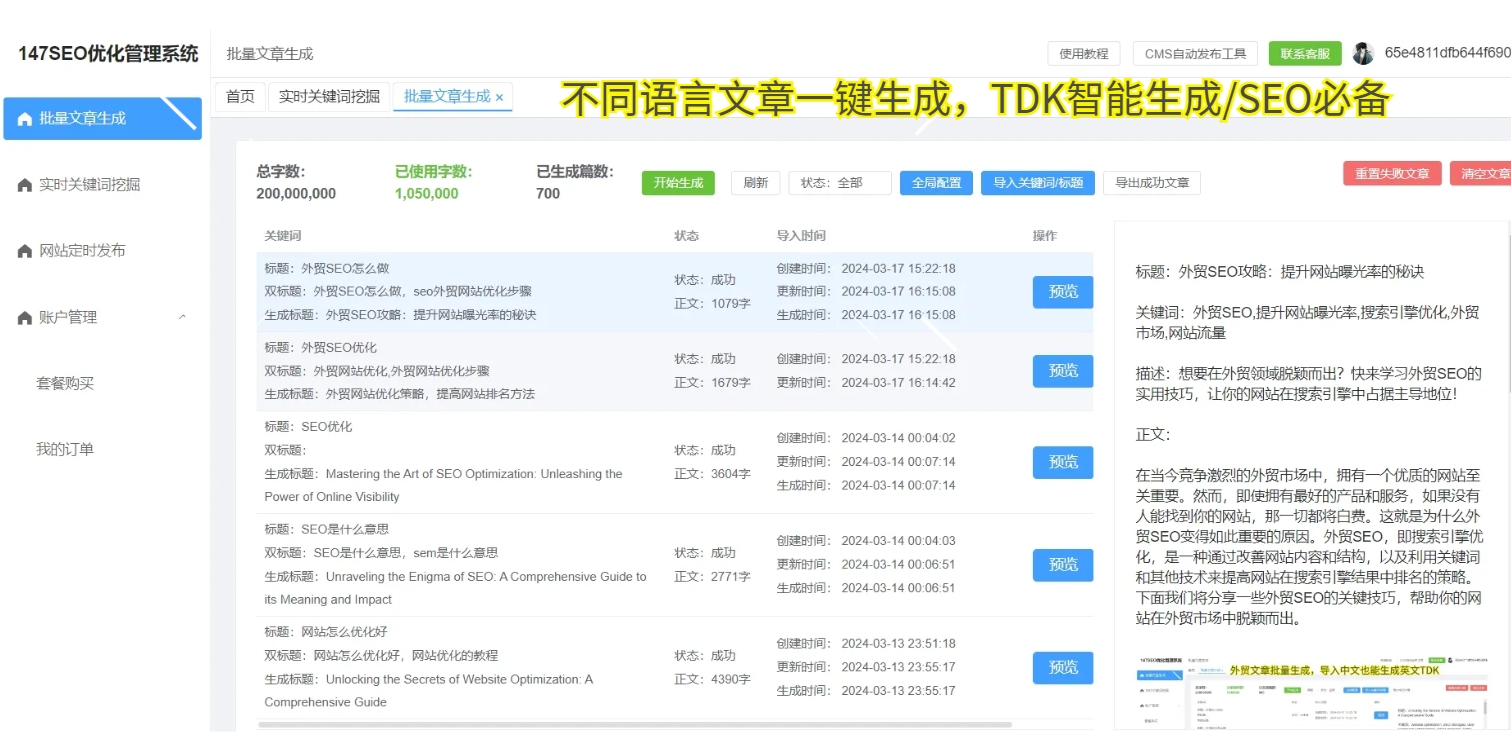
原创文章检测是指利用先进的技术手段对网络上的文章进行比对和识别,判断其是否为原创内容。其核心技术包括文本相似度比对、数据挖掘和机器学习等。通过这些技术手段,可以有效识别出抄袭、剽窃行为,保护原作者的合法权益。而在实际应用中,原创文章检测不仅可以应用于学术领域的论文查重,也可以用于互联网平台的内容审核和知识产权保护。
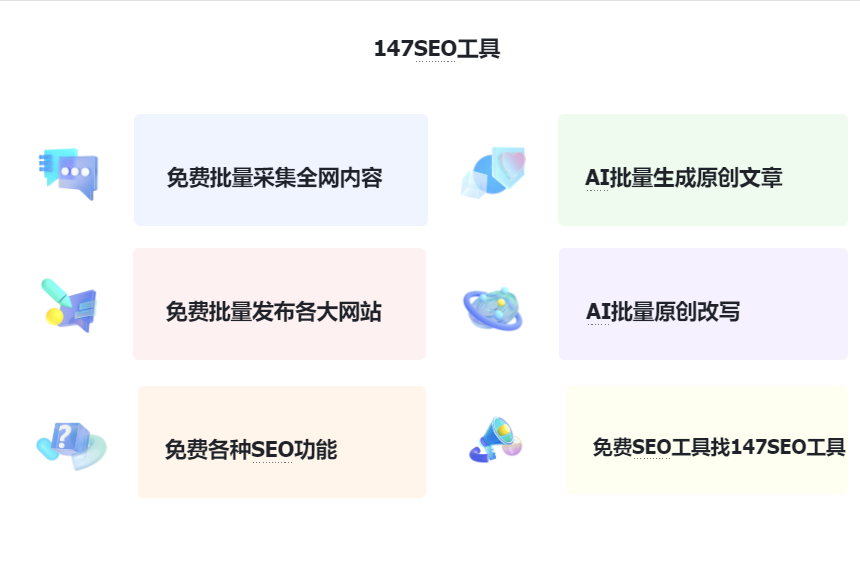
在原创文章检测的实施过程中,常用的方法包括基于规则的检测和基于模型的检测。基于规则的检测主要是通过设定一系列规则和阈值,对文章进行匹配和比对。这种方法简单直观,但受限于规则的设定和匹配精度,容易漏检或误判。而基于模型的检测则是利用机器学习等技术构建文章相似度模型,通过训练和优化来提高检测的准确性和效率。这种方法适用于大规模数据的处理,并且具有较高的智能化程度。
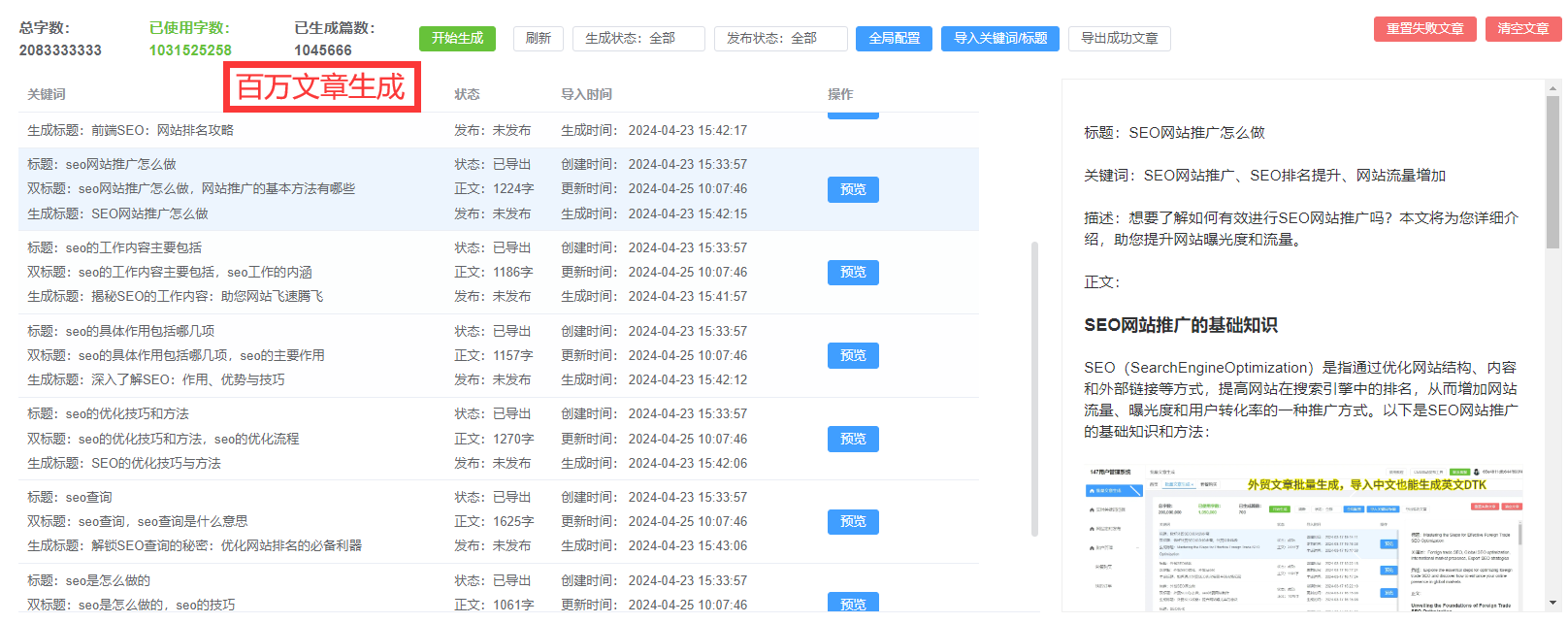
除了技术手段,原创文章检测还需要规则制度和社会监督的支持。在规则层面,各国都建立了知识产权保护的规则框架和相关法规,对侵权行为进行惩处和打击。社会各界也积极倡导原创意识,加强对知识产权的尊重和保护。这些举措共同构成了原创文章检测的基础和保障,推动了其在实践中的应用和发展。
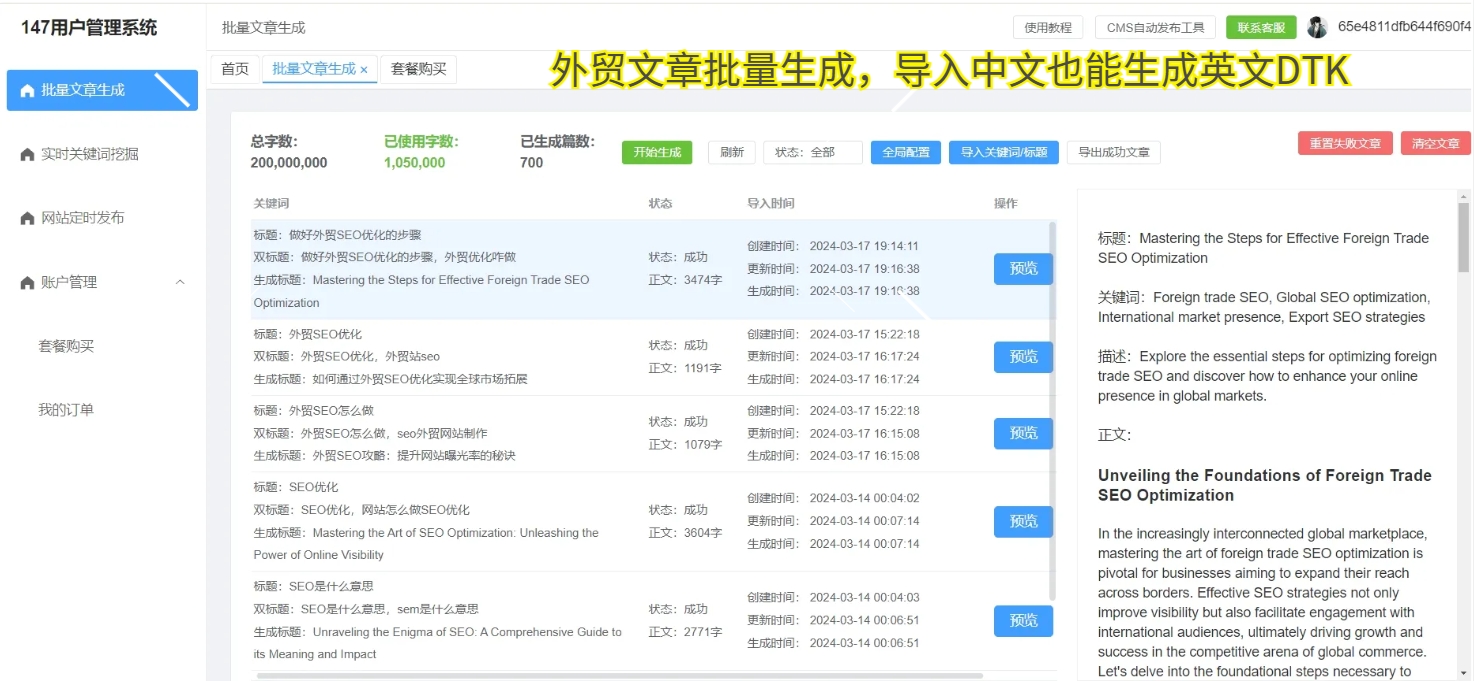
原创文章检测也面临着一些挑战和困难。首先是技术手段的限制,虽然目前已经有了较为成熟的检测技术,但仍然存在着一定的局限性,如对抄袭手段的不断变化和规避。其次是人工成本的增加,尤其是在大规模数据处理和复杂情境下,需要投入大量的人力物力。再次是隐私和安全问题,原创文章检测涉及到大量的用户信息和数据,如何保护用户隐私和数据安全成为了亟待解决的问题。
原创文章检测作为维护网络健康、保护知识产权的重要手段,发挥着不可替代的作用。在技术、规则和社会的共同努力下,相信原创文章检测会越来越完善,为构建和谐、健康的网络环境做出更大的贡献。



