在人类的创造性语言表达中,越来越多的人工智能技术开始扮演重要的角色。在中文语言领域,中文GPT2作为一种基于深度学习的生成式模型,为我们带来了新的希望。
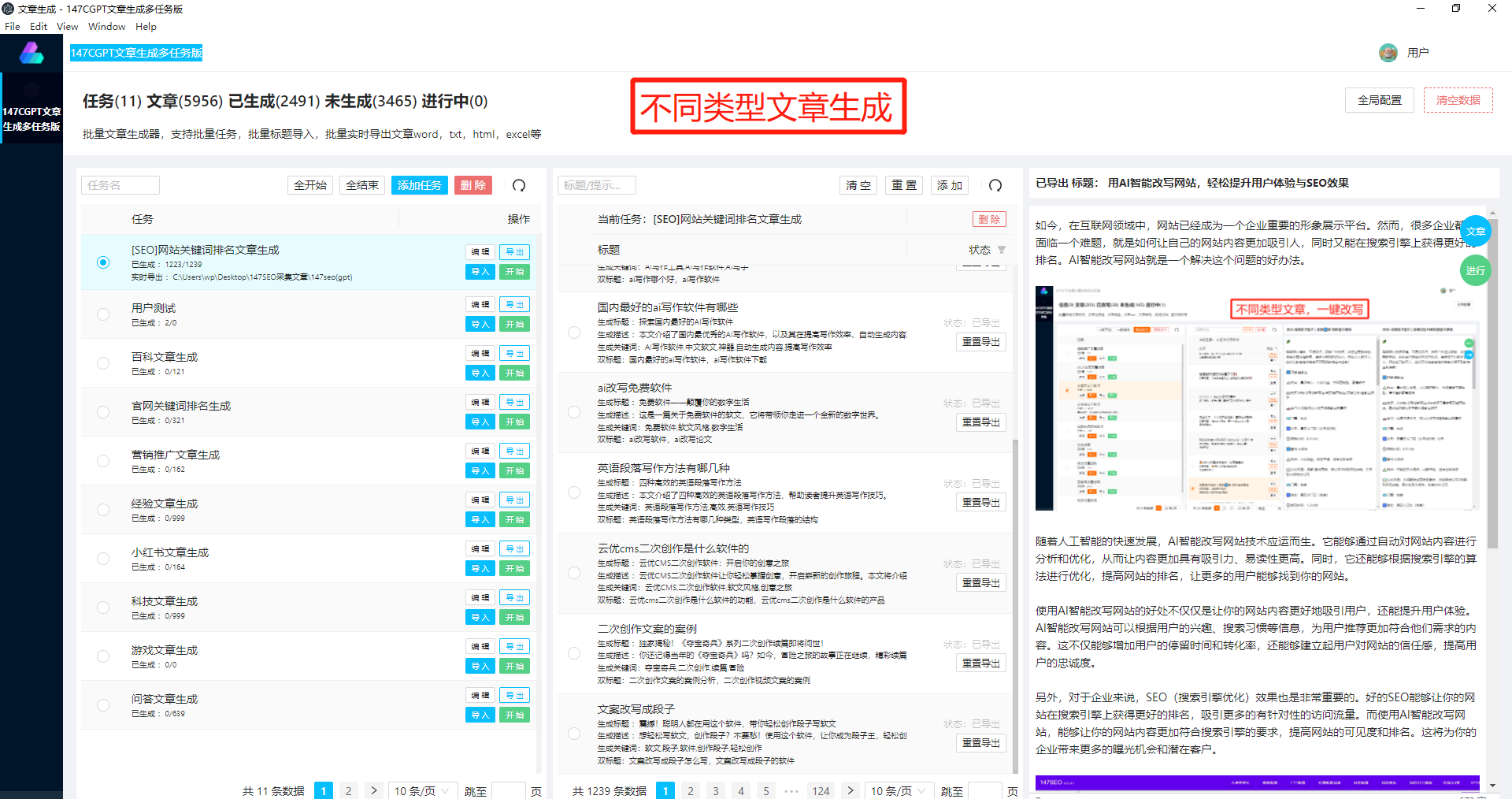
作为一种训练出的人工智能模型,中文GPT2的训练方法非常重要。需要大量的中文语料库作为训练数据。这些语料库可以包括维基百科、新闻文章、小说等各种各样的文本。通过对这些文本进行预处理、分词等操作,可以将原始文本转化为机器可以理解的格式。经过处理后,这些文本数据将作为训练数据输入到中文GPT2模型中进行训练。
中文GPT2的训练过程包括两个主要步骤:预训练和微调。预训练阶段,模型通过大规模的无监督学习来学会语言的基本结构和规律。在这个阶段,中文GPT2模型对大量的中文语料进行预测任务,预测下一个字、下一个词等。这使得模型可以理解并学习中文句子的上下文和语义关系。
预训练后,中文GPT2进入微调阶段,以进一步提高模型的生成能力和表达准确性。微调阶段使用特定任务的有监督学习方式,通过为模型提供正确的输入和输出对,来训练模型生成更加准确和合理的中文文本。微调的任务可以是机器翻译、自动摘要、对话生成等等。
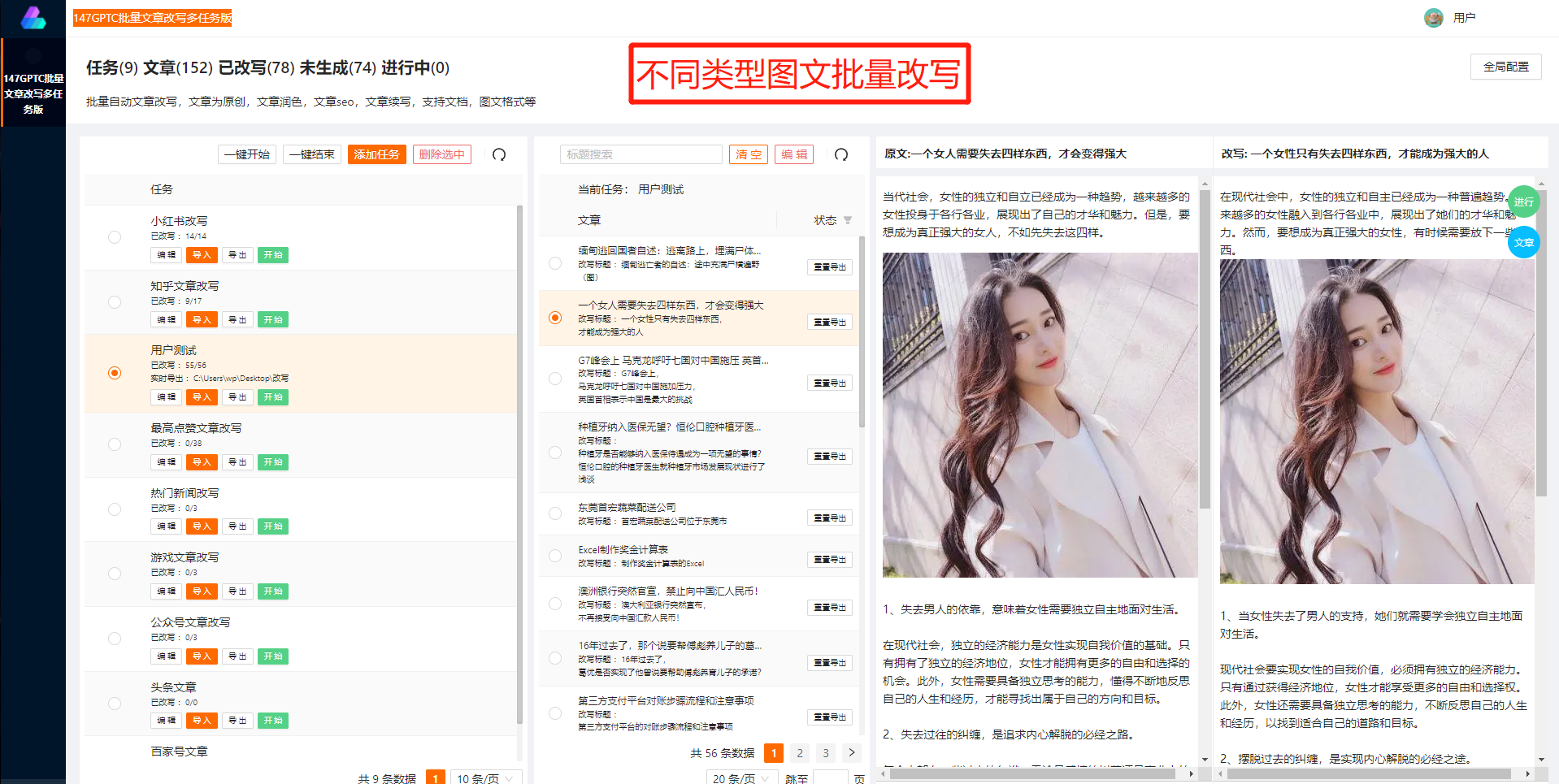
中文GPT2训练的关键在于使用大规模的中文语料,这样的训练数据可以让模型学习到更丰富多样的中文语言模式,并具备更好的语言创作能力。中文GPT2能够根据给定的前缀生成连贯、语义丰富的中文文本,从而在语言创作中发挥积极作用。
中文GPT2的训练方法不仅在机器翻译、智能问答等领域有很好的应用,还可以为创意写作、文学创作等领域的人工智能应用带来新的可能。在人工智能的辅助下,我们可以更快速、更高效地进行各种语言创作活动,拥有更多的创作灵感和可能性。
中文GPT2的训练方法为人工智能融入语言创作带来了新的时代。通过大规模的中文语料库和深度学习技术,中文GPT2实现了在中文语境下的理解、生成和创作,为我们提供了一个强大的工具。在中文GPT2的发展将为语言创作带来更多创新和突破,推动人工智能与语言表达的融合。