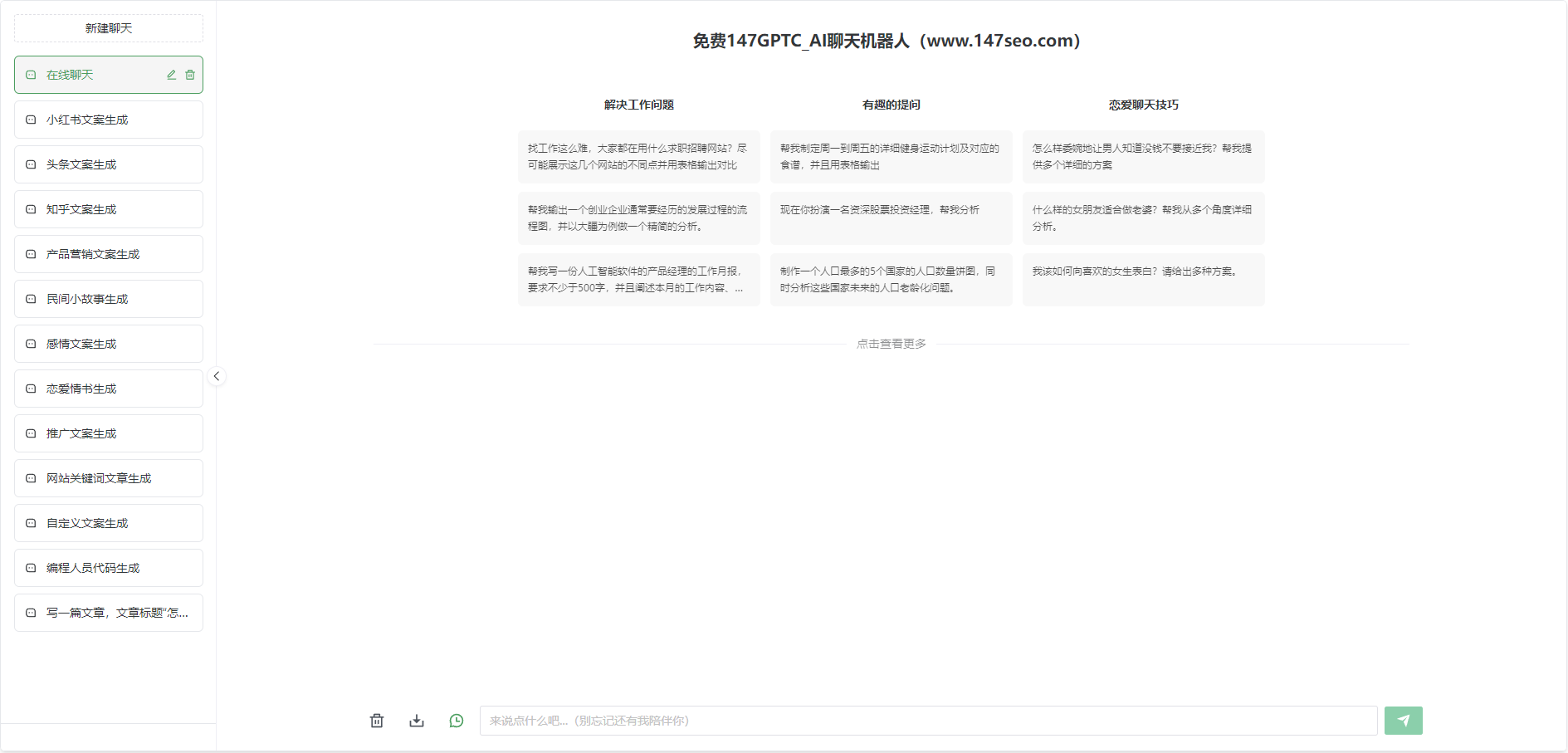
在当今数字化快速发展的时代,人工智能(AI)已成为引领科技创新的重要驱动力。近年来,GPT2中文训练模型的出现引起了广泛的关注和讨论。GPT2(Generative Pre-trained Transformer 2,即生成式预训练转换器2)是由OpenAI(人工智能研究机构)开发的一种基于深度学习的自然语言处理模型。它采用了前沿的深度学习技术,通过大量的中文语料进行训练,能够生成高质量的中文文本,并具备理解和回答问题的能力。
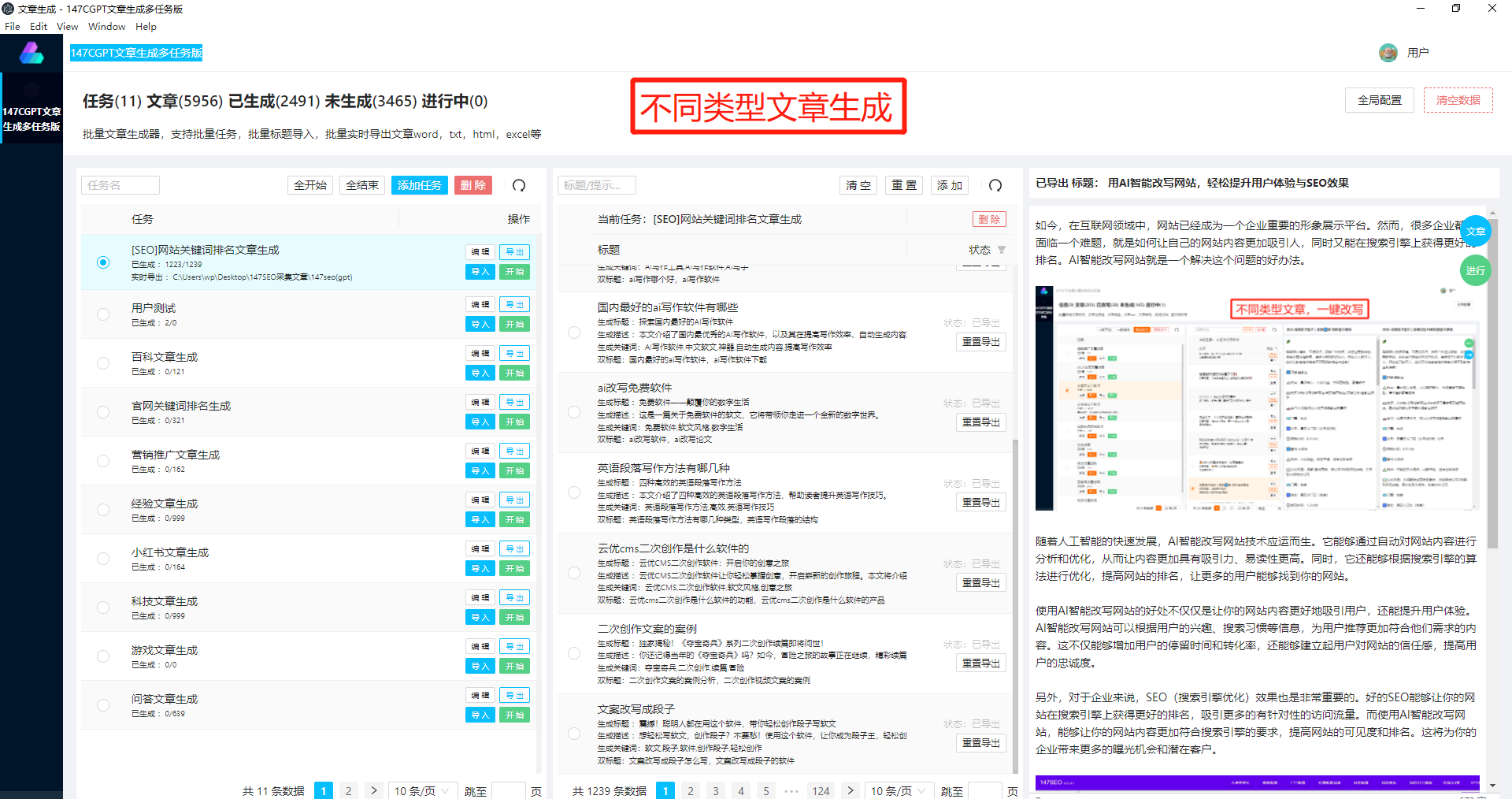
GPT2中文训练模型的突出特点之一是其出色的生成能力。通过深度学习的模型训练,GPT2可以生成连贯、流畅并且内容准确的中文文本。这为各个领域的应用带来了广泛的可能性。无论是自然语言生成、机器翻译、智能对话系统还是内容创作等,GPT2都能够提供高质量的中文文本,满足不同应用场景的需求。
除了生成能力,GPT2还具备强大的理解和回答问题的能力。它能够理解输入的问题,并基于丰富的语料库提供准确的答案。这使得GPT2在智能问答系统、客服机器人等领域有着广泛的应用前景。不仅如此,GPT2还可以进行文本的摘要和分类,帮助用户快速提取和归纳信息,极大地提高工作效率。
GPT2中文训练模型也面临一些挑战和问题。由于其训练模型的复杂性,GPT2在处理上下文混乱和多义词等问题上仍有一定局限性。对于敏感话题和不当信息的处理也需要加强,以确保生成的文本准确性和合规性。
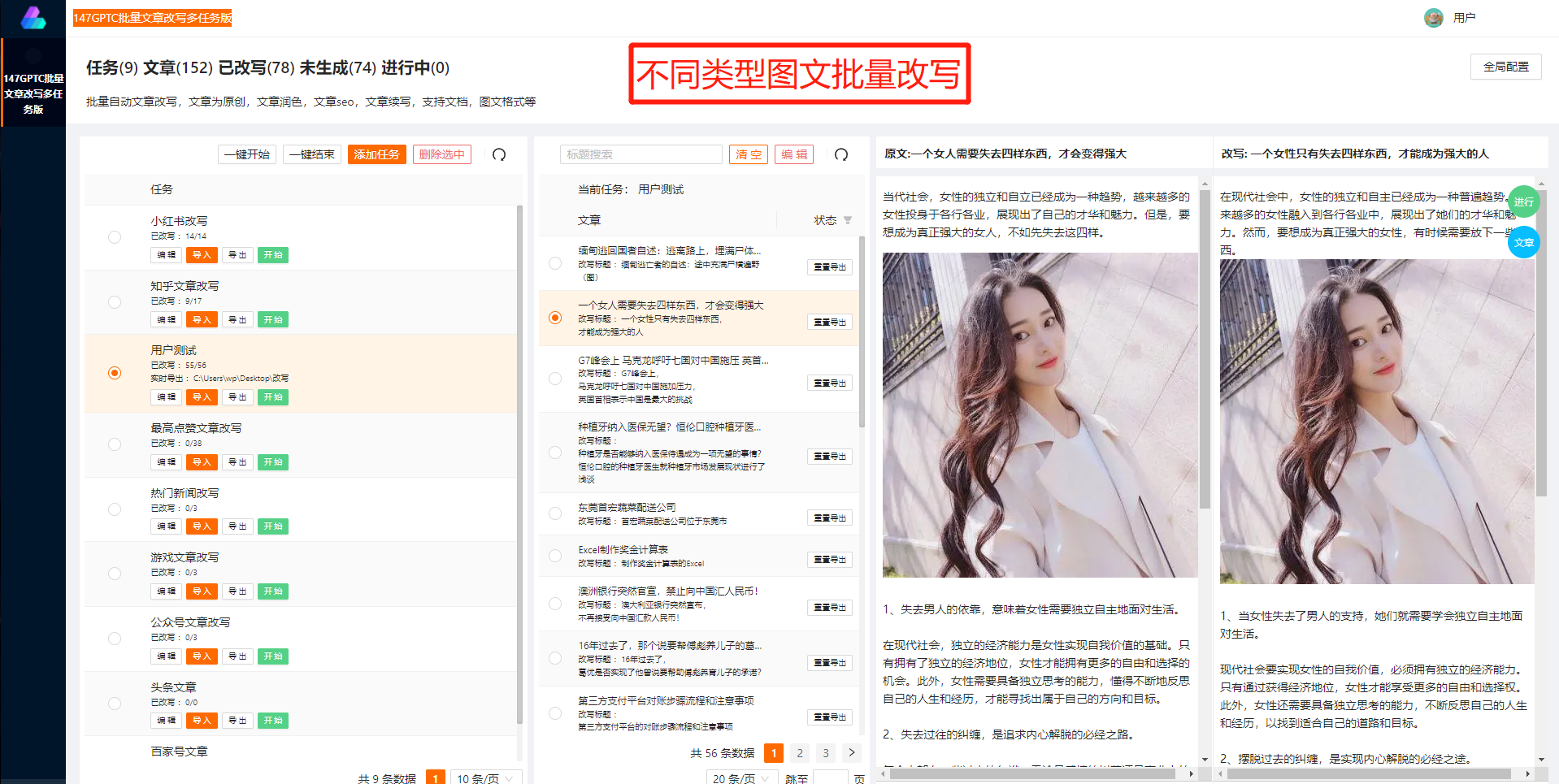
尽管如此,GPT2中文训练模型依然展现出巨大的潜力和价值。它已经在多个领域取得了令人瞩目的成果。文学创作、广告文案、新闻报道等领域都可以受益于GPT2的生成能力和理解能力。GPT2还能够辅助人工智能研究人员进行模型开发和优化,加快科研进程。
在人工智能技术日新月异的今天,GPT2中文训练模型的问世不仅推动了中文自然语言处理技术的发展,也为各行业的应用提供了新的方向。它的出现标志着人工智能时代的新篇章的开启,必将为人类社会带来更多的便利和进步。
GPT2中文训练模型凭借其出色的生成能力和强大的理解能力,推动着人工智能的发展。它将为各个领域的应用带来新的机遇与突破。在不断创新和进步的道路上,我们将继续探索和拓展GPT2中文训练模型的潜力,开创人工智能时代的新篇章。