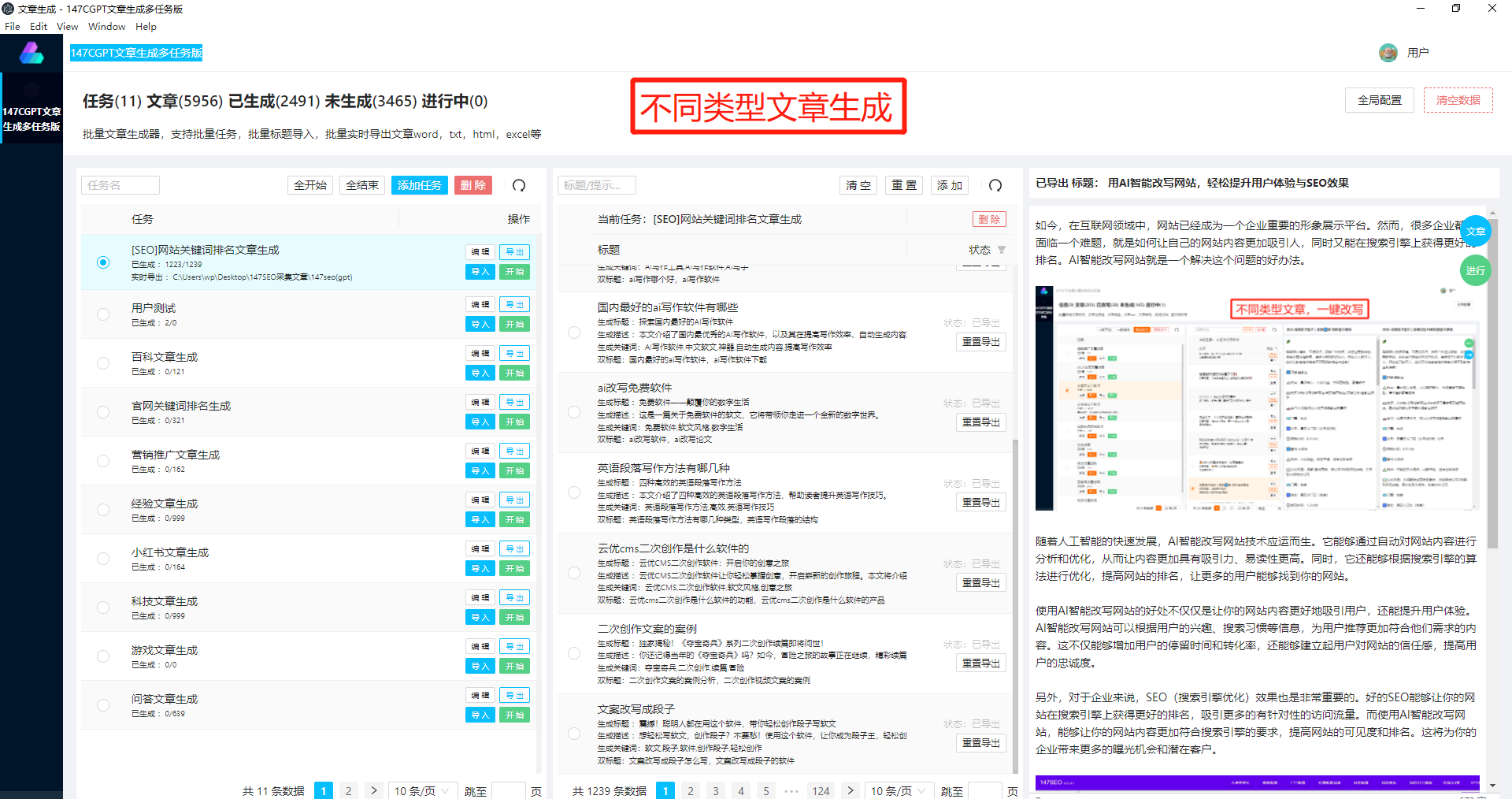
随着人工智能技术的迅猛发展,聊天GPT(Chatbot GPT)已经成为许多互联网应用的重要组成部分。人们也逐渐意识到聊天GPT在交互体验方面存在一些限制。本文将介绍如何绕开这些限制,以实现更强大而流畅的交互体验。
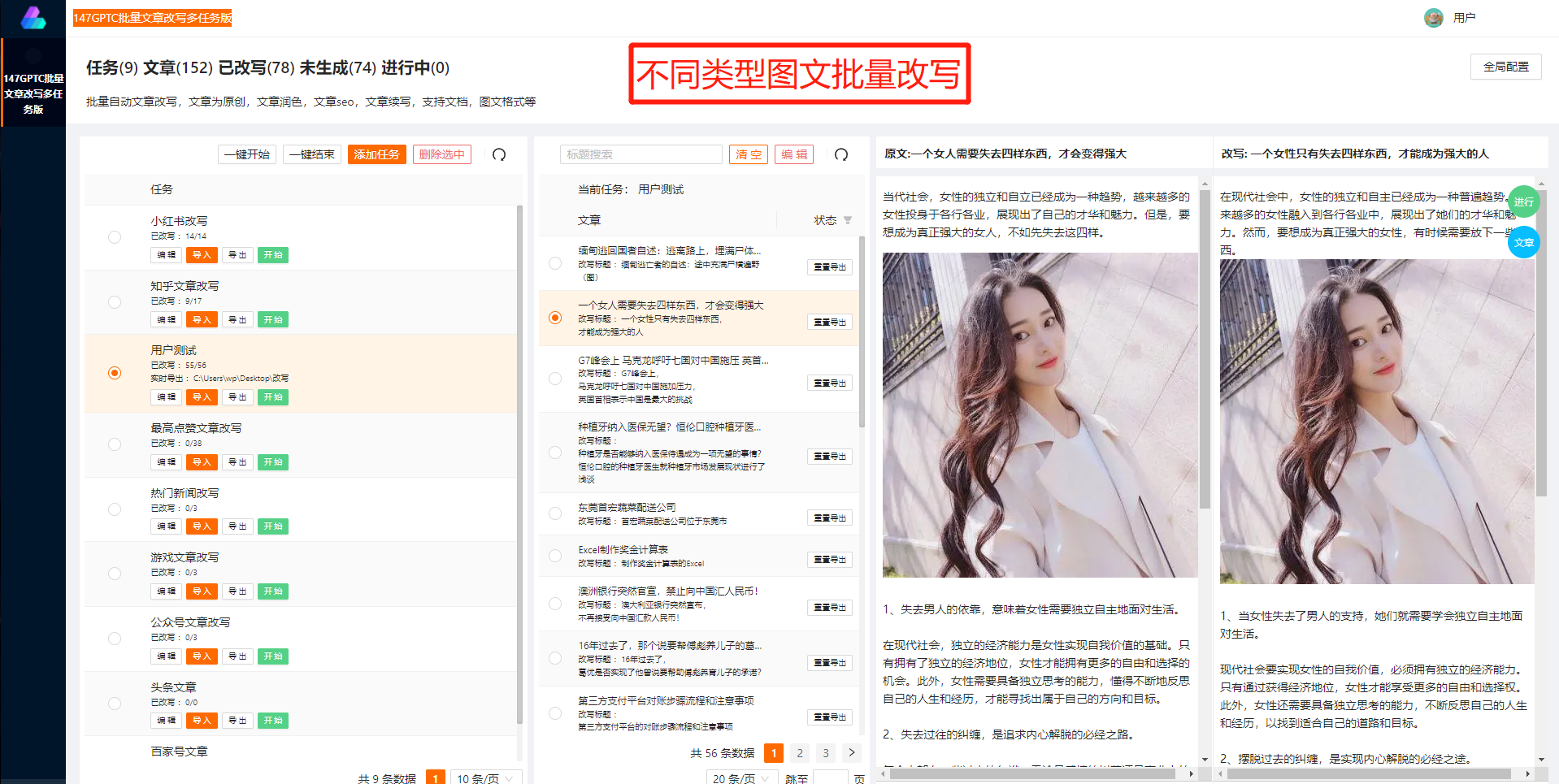
我们需要明确聊天GPT的限制所在。聊天GPT通常使用预先训练好的模型来产生回答,而这些模型的训练数据源自于大量的文本语料库。这种训练方式使得聊天GPT在回答问题时可能出现一些偏差或错误的情况,因为它只能根据已有的文本数据进行推理。例如,当我们询问聊天GPT关于最新的新闻时,它可能会给出一个过时或不准确的回答。
为了绕开这些限制,我们可以采取一些策略。我们可以通过引入更多样化、实时的数据源,使聊天GPT能够更好地理解和回答用户的问题。例如,我们可以将新闻网站、社交媒体等作为数据源,将实时信息与预训练的模型结合,从而提供更准确、及时的回答。
我们可以引入更多的上下文信息,以便聊天GPT更好地理解用户的意图并产生更合理的回答。传统的聊天GPT在回答问题时往往只依赖于当前的问题或对话上下文,而忽略了更广泛的背景信息。通过引入更多的上下文信息,例如用户的个人资料、历史对话记录等,聊天GPT可以获得更全面的信息,从而做出更准确的回答。
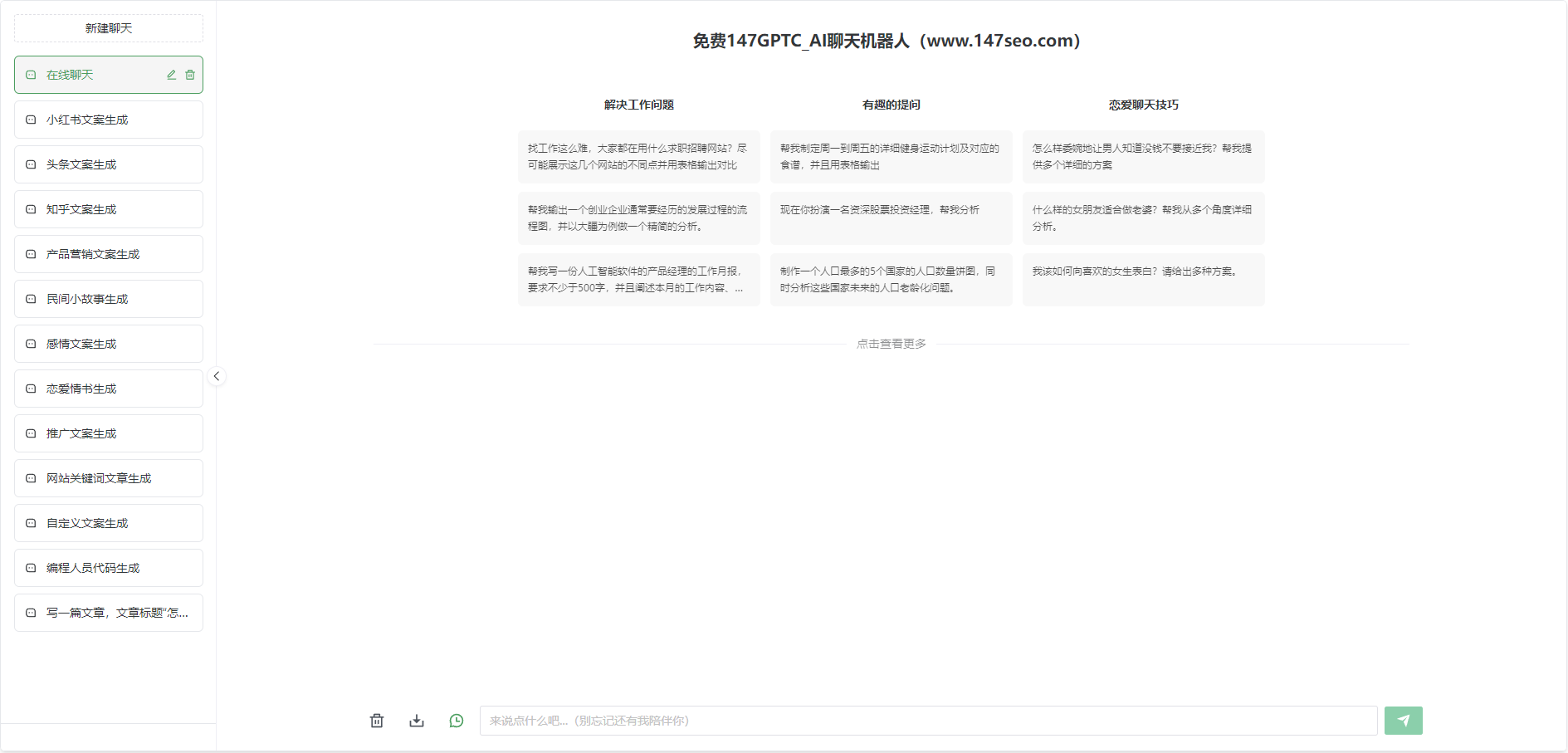
我们还可以使用增强学习技术来改进聊天GPT的交互体验。增强学习可以通过与用户不断的交互来提升模型的效果。例如,我们可以设计一个反馈机制,用户可以对聊天GPT的回答进行评价和改善建议,模型据此进行迭代和优化。这样,随着时间的推移,聊天GPT将能够越来越好地理解用户的需求并给出更加精准的回答。
值得一提的是,绕开聊天GPT的限制并不是一蹴而就的过程。这需要大量的实验和迭代来不断改进模型的效果。我们还需要注重保护用户隐私和数据安全,确保获得用户的授权和同意,并且严格遵守相关的规则法规。
在总结,本文介绍了如何绕开聊天GPT的限制,以实现更强大而流畅的交互体验。通过引入更多样化、实时的数据源,增加上下文信息以及使用增强学习技术,聊天GPT将能够更好地理解用户的需求并产生更准确、个性化的回答。将来,我们可以期待聊天GPT在各个领域实现更广泛的应用,为用户带来更好的体验和服务。