
采集网页内容,让信息变得更全面更便捷
在现代社会,信息已经成为了人们永无止境的追求。每个人都渴望得到越来越多的信息,而采集网页内容便是一种能够让信息获取更加全面、便捷的工具。
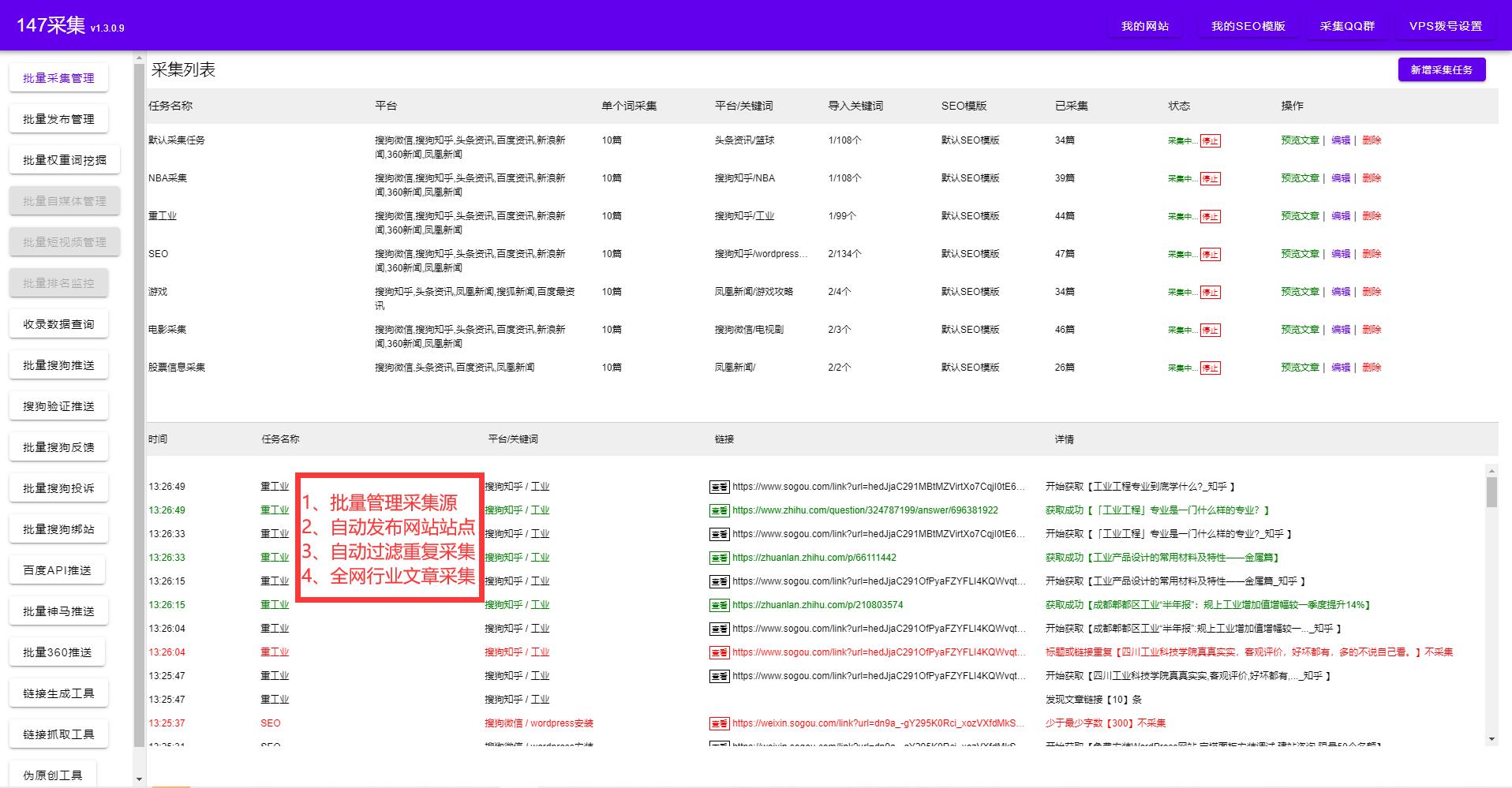
采集网页内容的原理非常简单,就是在网页上自动提取内容,并保存到数据库中。而采集网页内容的用途也非常广泛。它可以被用来做数据分析、信息搜集、竞争情报分析等。采集网页内容的优点在于:区分内容数据和网页格式;自定义采集规则,更加灵活;支持多种编码格式,支持不同语言的网页采集;可以自动实现分页采集、去重采集等。
采集网页内容的过程中,有一些需要注意的问题。首先,一些网站是有反爬虫机制的,需要在采集时进行模拟或使用代理。其次,采集的数据需要经过处理和清洗,避免噪声数据以及冗余数据的干扰。此外,采集到的数据需要存储,可以选择存放到数据库中,也可以选择导出到文件中。
采集网页内容在不同领域都有着广泛的应用。比如,在电商领域,可以采集竞争对手的商品信息以及价格,为企业决策提供参考;在教育领域,可以采集各种教育信息,以便教师更好地为学生服务;在政府部门,可以采集公共数据信息,为政策决策提供支持。
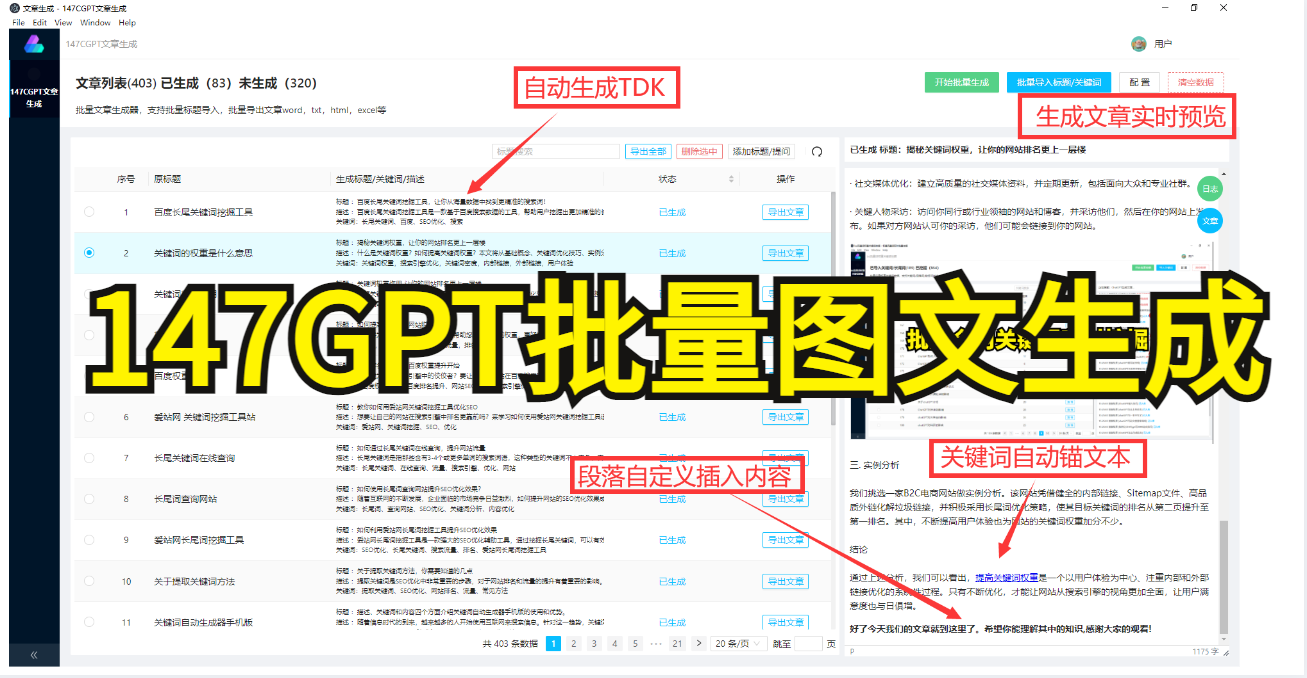
总结一下,采集网页内容能够为人们的信息获取带来极大的方便。不过,在采集数据过程中,需要注意各种问题,避免采集到无用信息以及受到反爬虫机制的干扰。只有在科学合理使用的前提下,才能够将采集网页内容这一工具发挥出最大的作用。



