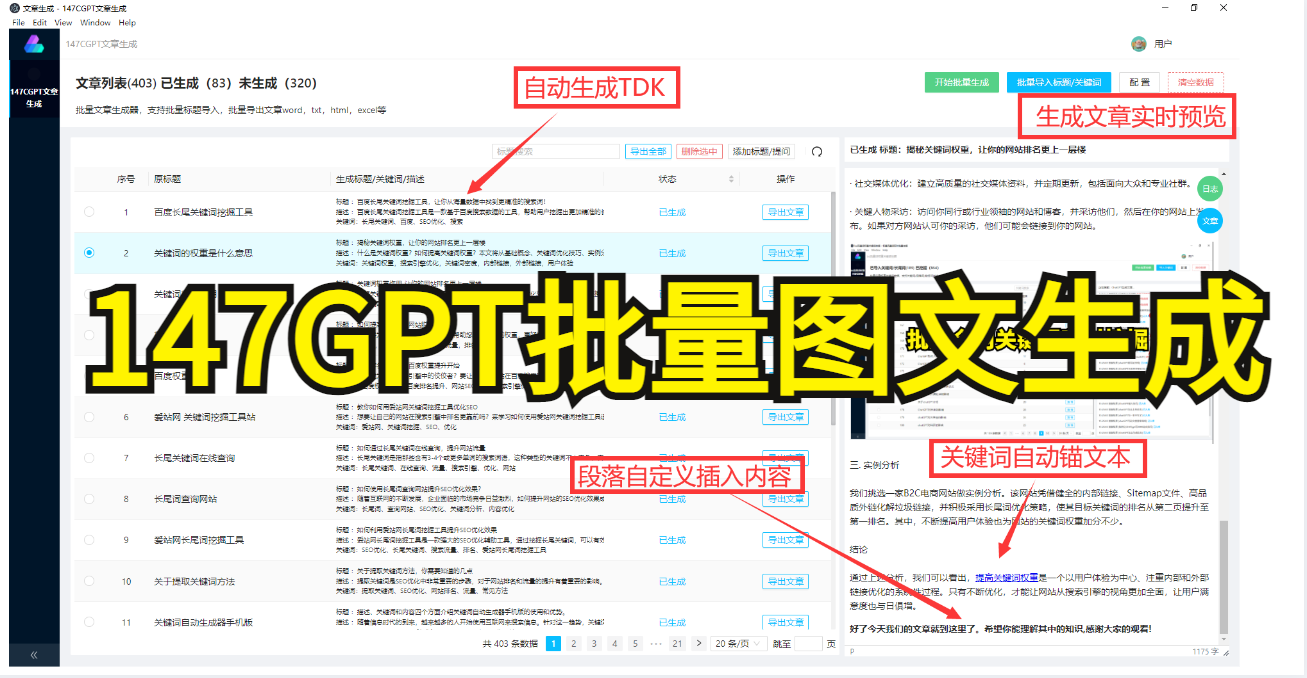
随着互联网的快速发展和普及,人们需要获取各种各样的信息时更多地依赖于网络。但是,由于网络上的信息太多太杂,我们很难快速地找到自己需要的内容,这就需要一些自动化工具来帮助我们提高信息搜索效率,而网页采集就是其中的一种。
网页采集指的是利用计算机程序自动从互联网上获取数据的过程。相当于我们把兴趣点告诉采集器,让它代替我们完成一系列操作,从而获得我们想要的数据,这样的方式速度快、准确度高、效率高。
网页采集的应用范围非常广泛,比如信息收集、社交监测、竞争情报、商业研究等等。它可以帮我们收集各种不同类型的数据,包括文本、图片、视频、音频等等。不仅如此,通过网页采集可以快速抓取商品价格、评论、库存等信息,帮助运营商制定更加实用、准确的业务方案。
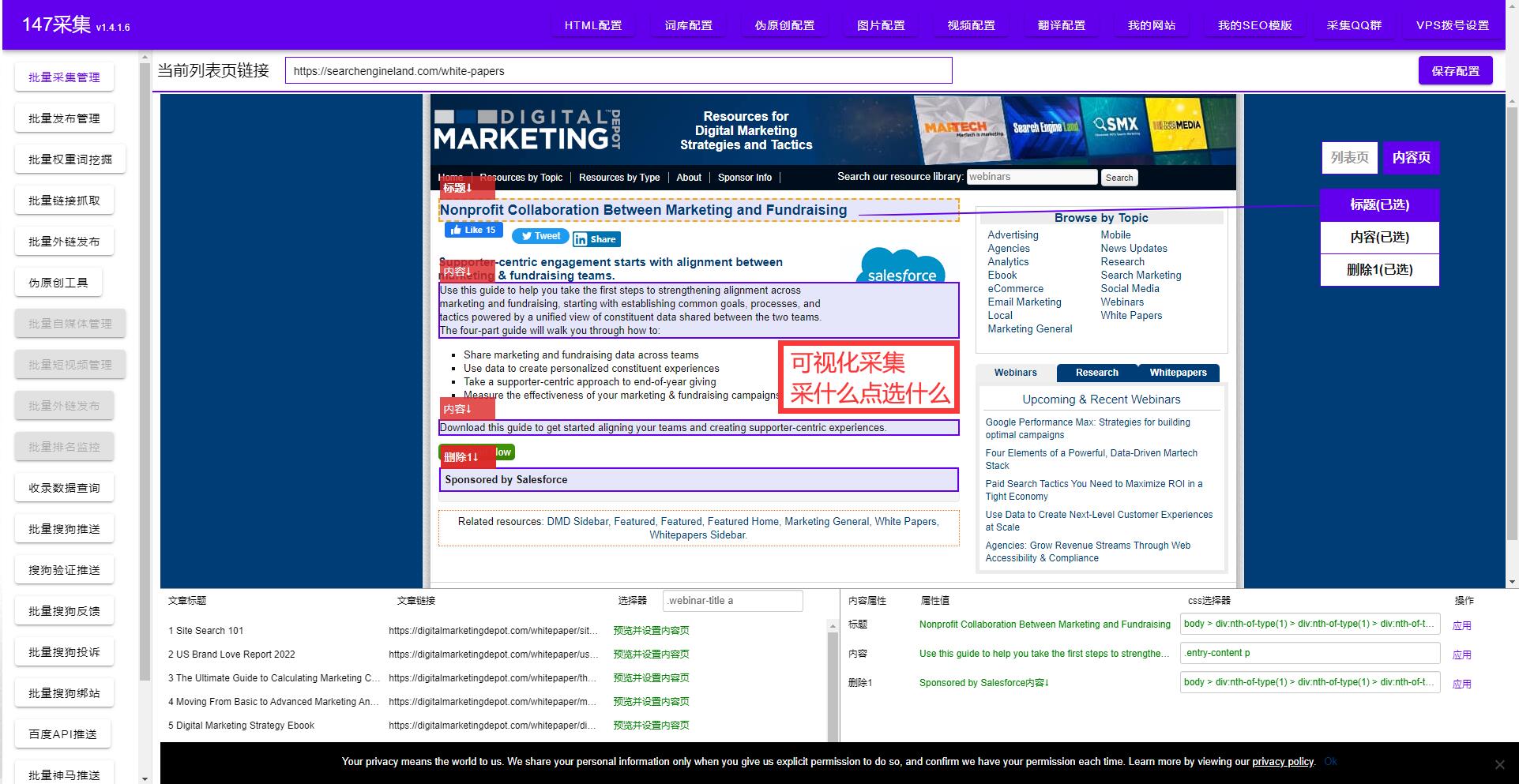
那么,网页采集是如何实现的呢?在技术上,网页采集需要用到一些语言和工具,包括Python、Perl、Ruby等编程语言,以及Scrapy、Beautiful Soup等框架。这些工具和语言可以帮助我们从各种各样的网页中获取所需的数据。但是,要想更好地完成采集,还需要具备一定的编程能力和对网页结构的理解。
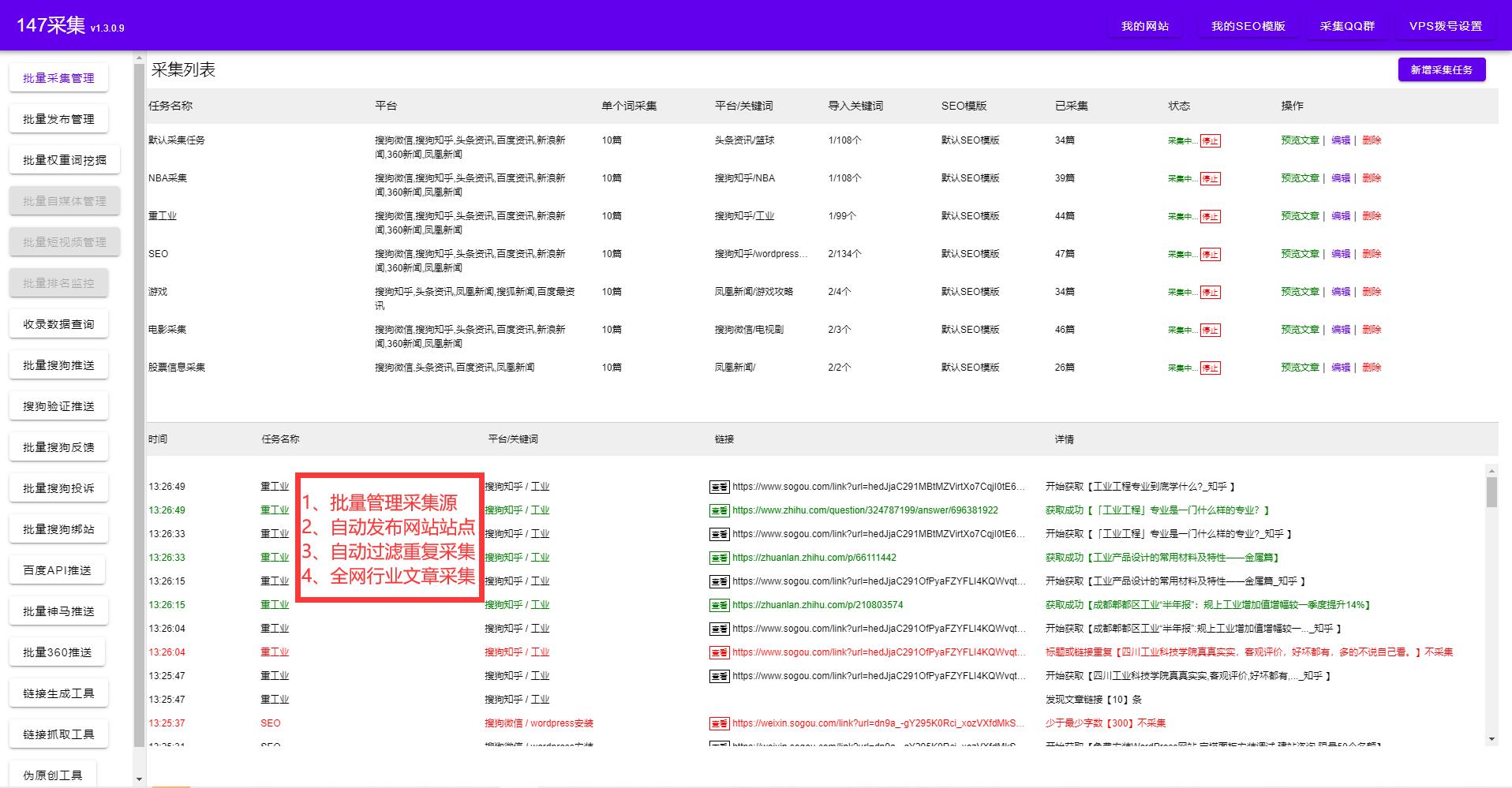
目前,市面上有很多网页采集工具,比如爬虫、八爪鱼、EasyWebPage等等。这些工具的共同优点就是方便易用、功能强大、可扩展性高。但是,网页采集的难点不在于选择什么工具,而在于如何合理选取、设置和分析数据,从而实现所需要的业务需求。
在市场需求方面,网页采集正成为企业、政府、个人等群体中不可或缺的工具。比如,商业信息分析中的市场调研和竞品分析需要从各种渠道采集大量数据,再进行数据清洗、处理和分析,所以网页采集越来越受到企业的青睐。又比如,政府数据的采集和处理也需要越来越好的工具和技术支持,以更好地服务社会和民生。
综上所述,网页采集是一种有益无害的工具,可以帮助我们提高信息搜索效率,拓展我们的数据源。它所涉及到的技术越来越成熟、更加易用,市场需求也越来越高。因此,如果你需要采集大量数据或提高信息搜索效率,不妨考虑网页采集这个好帮手。