
作为信息爆炸时代的重要组成部分,新闻扮演着传播信息、引导舆论的重要角色。如何高效获取海量的新闻资讯,成为许多人关注的话题。而网络爬虫技术的出现,为我们提供了一种全新的解决方案。
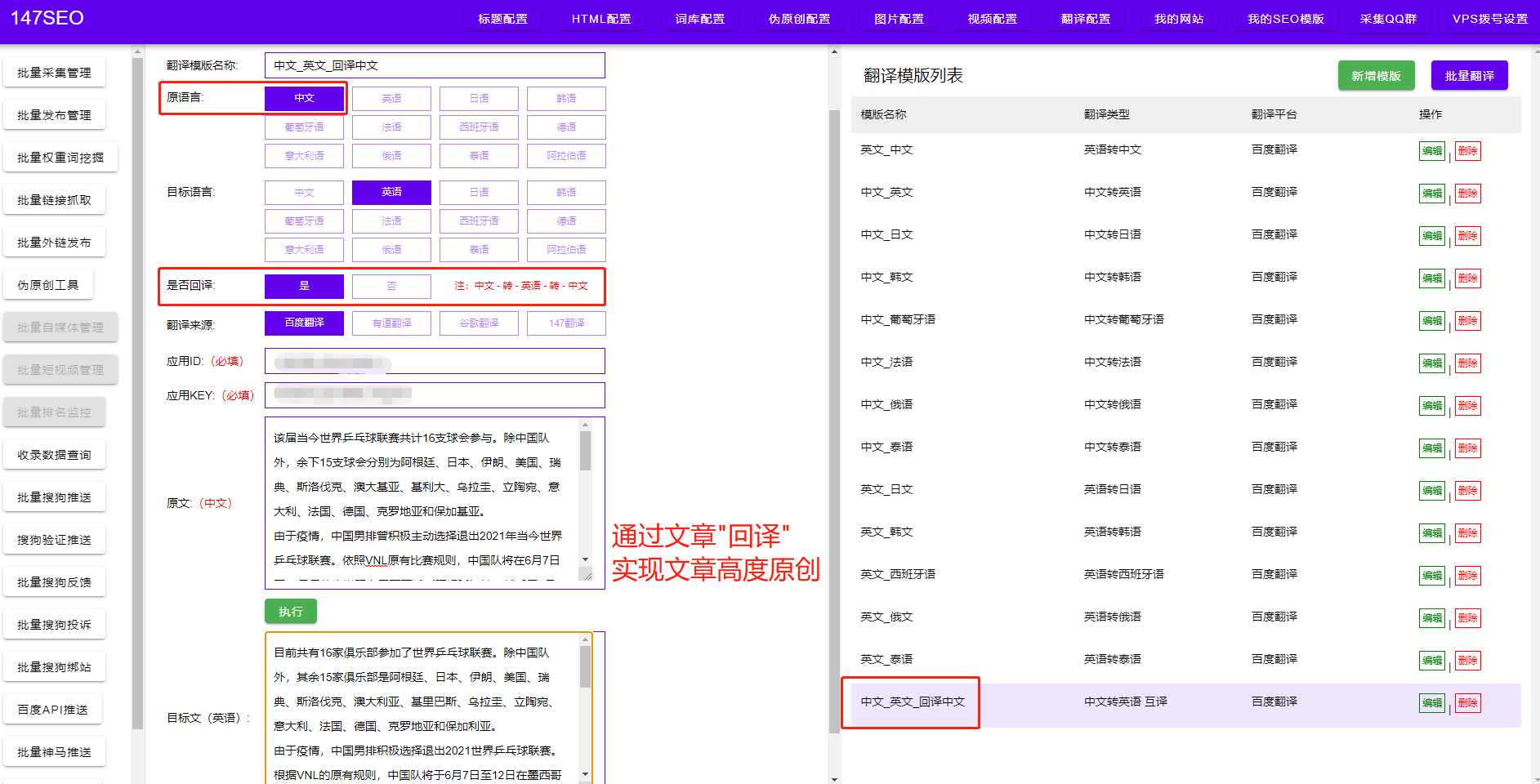
爬虫是一种自动化程序,能够模拟人的行为,自动采集互联网上的各种信息。爬虫在新闻领域应用广泛,通过爬虫技术,我们可以轻松地爬取包括文字、图片、shiping等多种形式的新闻数据。下面,我们将为你介绍如何使用爬虫来爬取新闻内容。
一、确定爬虫目标 在开始爬取新闻之前,我们首先需要确定我们的爬虫目标。要爬取的新闻网站有很多,我们可以选择一些热门的新闻网站作为目标,如新浪新闻、腾讯新闻等。根据自己的需求选择合适的网站进行爬取。
二、分析目标网站的结构 在进行爬取之前,我们需要对目标网站的结构进行分析。通过观察网站的HTML源代码,分析网页的结构,确定需要爬取的数据在哪个位置。
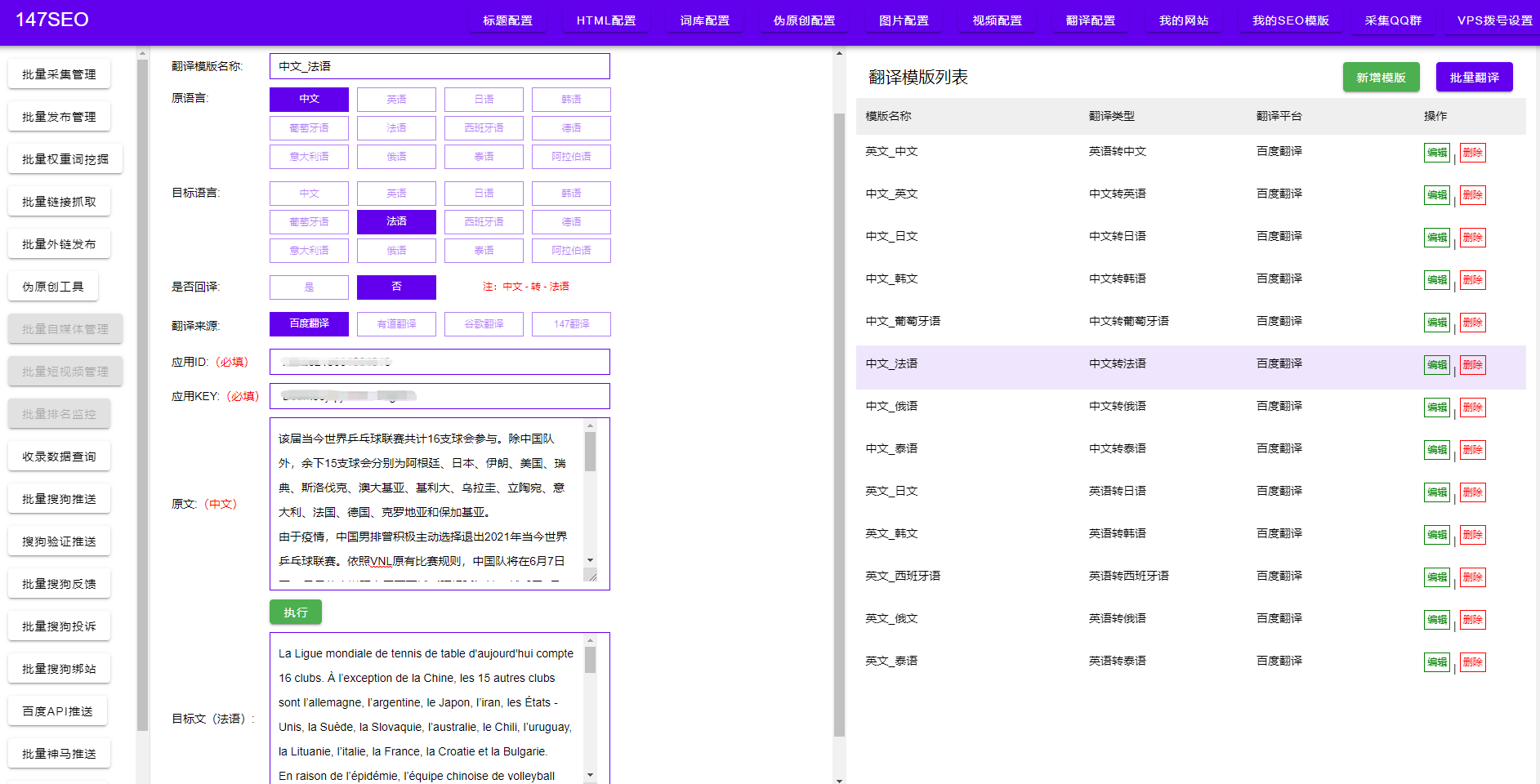
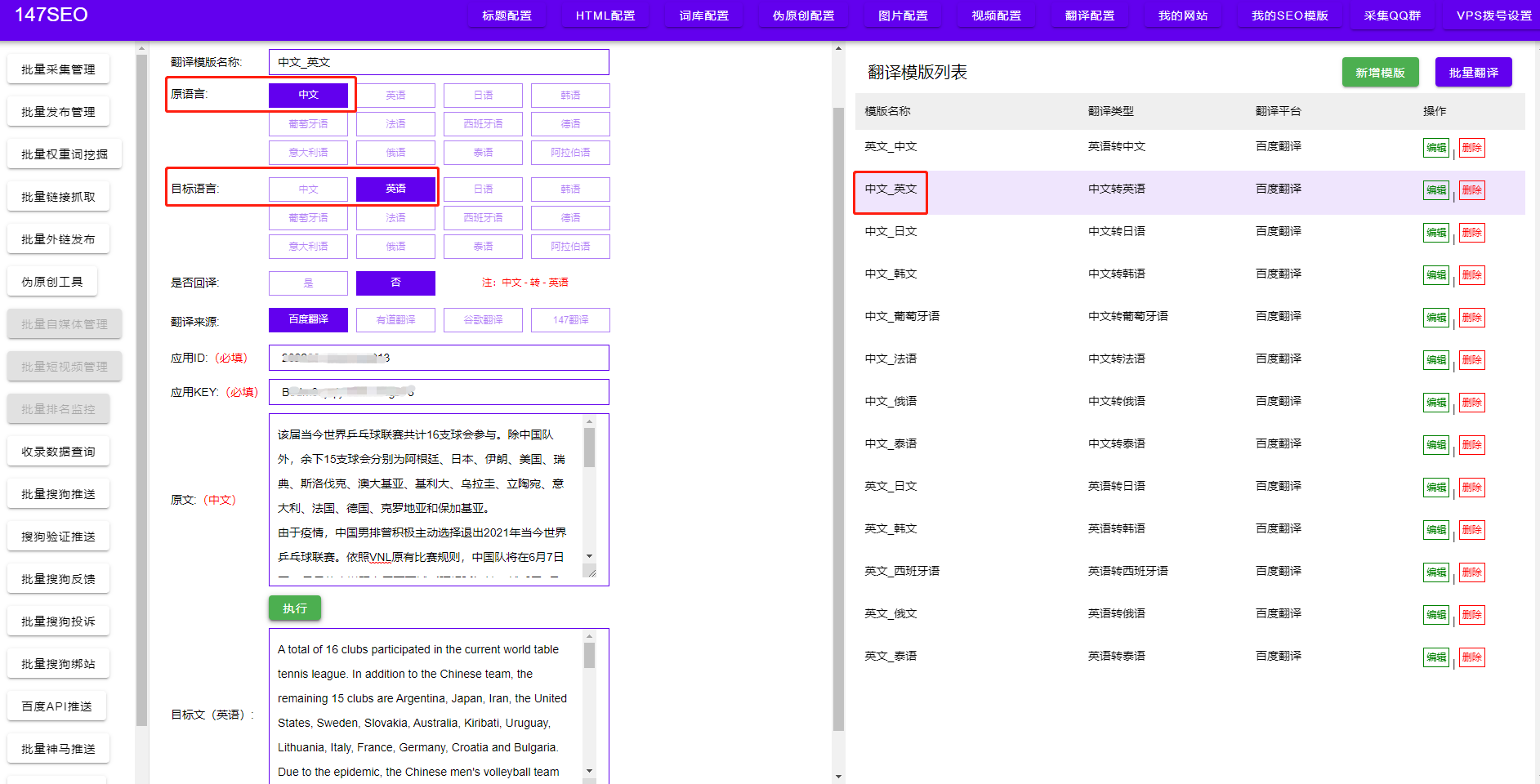
三、编写爬虫代码 在分析目标网站结构之后,我们就可以开始编写爬虫代码了。使用Python语言编写爬虫代码是最常见的选择,Python提供了许多强大的爬虫框架和库,如Scrapy、BeautifulSoup等。根据自己的需求,选择合适的工具,并按照其文档进行爬虫代码的编写。
四、处理反爬措施 为了防止被网站屏蔽或封禁,我们需要在爬虫代码中处理一些反爬措施。常见的反爬措施包括限制爬取速度、设置User-Agent、使用代理IP等。针对不同的反爬措施,我们需要做出相应的处理,确保能够正常获取数据。
五、数据存储与管理 爬取到的新闻数据需要进行存储和管理。我们可以选择将数据存储到数据库中,如MySQL、MongoDB等,也可以存储到本地文件中。另外,为了方便后续的数据分析和处理,我们还可以使用数据处理工具,如Pandas、NumPy等进行数据清洗和分析。
通过以上五个步骤,我们就可以使用爬虫技术来爬取新闻内容了。通过灵活运用爬虫技术,我们不仅可以获取到海量的新闻资讯,还可以进行数据分析、挖掘和展示。采集到的新闻数据可以用于舆情监测、新闻推荐等领域,为我们提供更多的信息和决策依据。
总结起来,网络爬虫技术在新闻爬取领域有着广泛的应用,通过爬虫技术,我们可以轻松地获取新闻网站上的新闻内容。合理运用爬虫技术,我们可以更好地掌握信息,提高工作效率,为我们的工作和生活带来便利。赶快动手尝试吧!



