
GPT2(GenerativePre-trainingTransformer2)是一种基于Transformer架构的自然语言处理模型,它在NLP领域取得了巨大的成功。最初由OpenAI团队开发,GPT2模型在大规模的文本语料上进行预训练,并能够生成流畅连贯的语言输出。其出色的生成能力使其在各种任务中广受欢迎和应用。
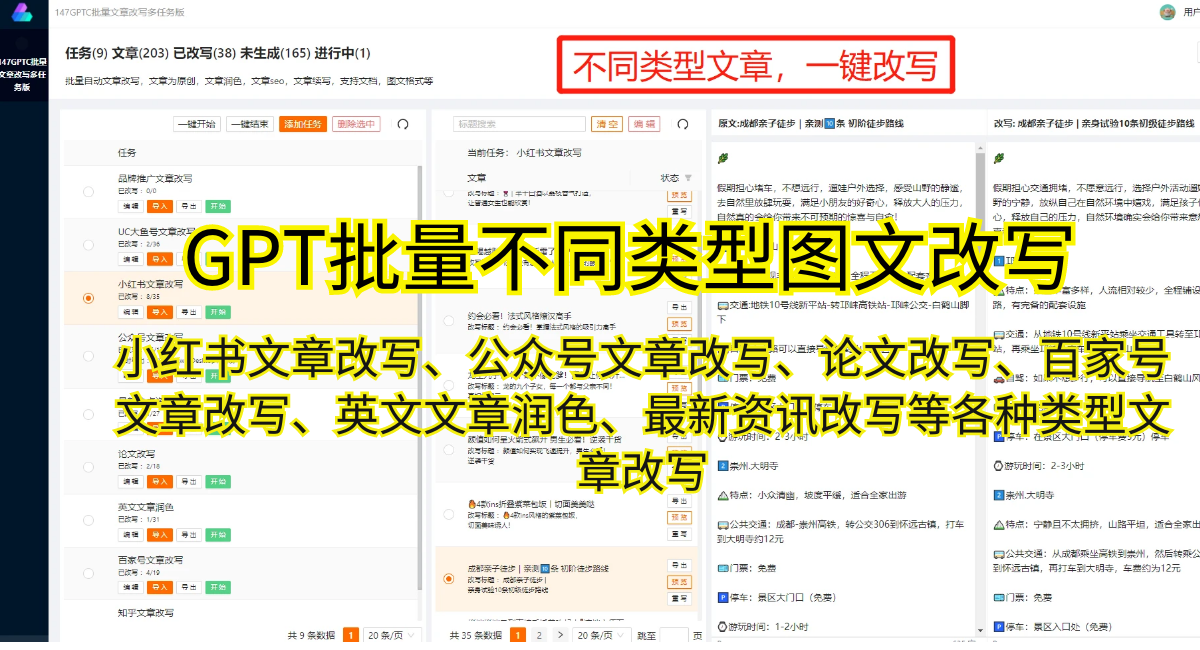
GPT2中文模型的成功离不开海量的中文文本数据。它首先在英文数据上完成预训练,然后在中文数据上进行进一步微调。这使得GPT2能够准确理解中文语境,生成出符合中文语言习惯的文本。其丰富的词汇和准确的语法使得生成的文本质量远超以往的模型,更加贴近人类表达习惯。
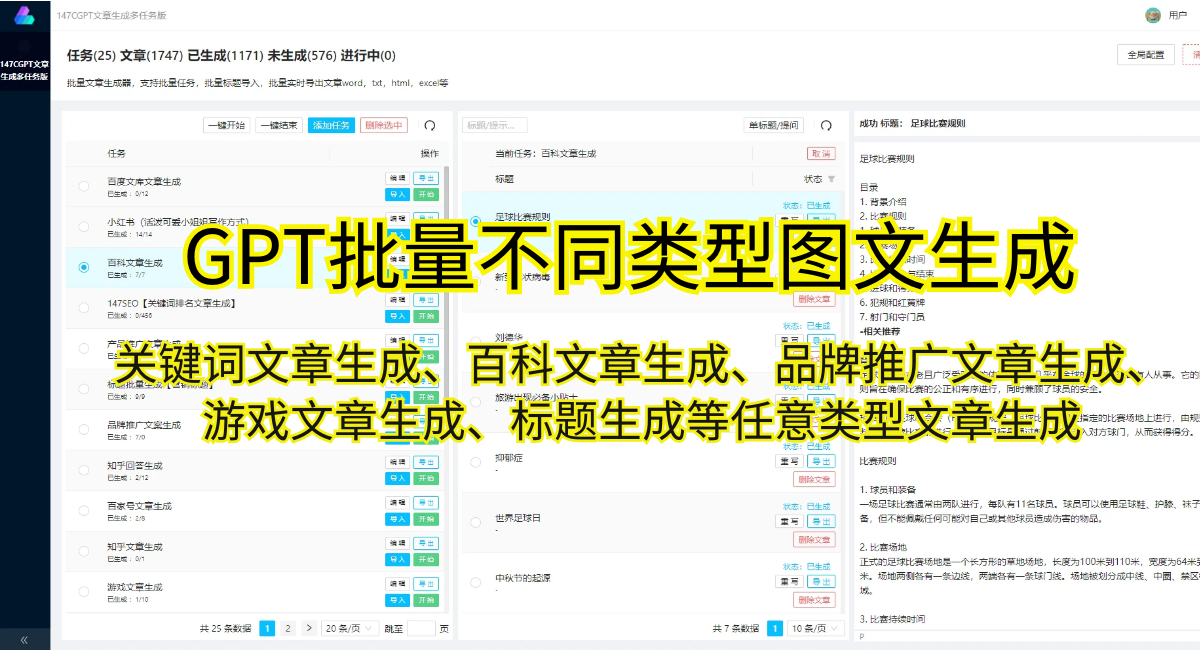
GPT2中文模型的应用几乎无处不在。它可以用于文本生成、机器翻译、对话系统、文章创作等领域。在文本生成方面,GPT2可以根据给定的前文生成后续的文本段落,具有较高的连贯性和逻辑性。在机器翻译中,GPT2可以将源语言自动转化为目标语言,实现快速高质量的翻译。在对话系统中,GPT2可以模拟人类对话,实现智能问答和客户服务。在文章创作中,GPT2可以写作新闻报道、小说情节等,节省了人工创作的时间和劳动成本。
除此之外,GPT2中文模型还被广泛应用于社交媒体、搜索引擎优化等领域。在社交媒体中,GPT2可以生成引人入胜的帖子或评论,吸引用户的注意。在搜索引擎优化中,GPT2可以生成高质量的网页内容,帮助网站提高排名和用户体验。
然而,GPT2中文模型也存在一些挑战和限制。由于其是基于大规模文本数据进行自我学习,可能会存在信息的偏向性和歧视性。此外,在使用GPT2生成的内容时,需要注意其可能存在的错误和不准确性,需要进行后续的修复和验证。对于敏感话题和内容,也需要谨慎使用,避免不必要的负面影响。
总之,GPT2中文模型以其出色的生成能力和广泛的应用领域展示了人工智能在自然语言处理中的无限可能。随着技术的不断进步和改善,相信GPT2中文模型将为我们带来更多有趣、有用的应用场景,推动人工智能在语言领域的发展。



