
互联网时代的到来给我们提供了大量的信息ZY,但要找到所需的数据并不总是轻而易举的。而对于一些需要大量数据支持的应用程序和研究者来说,找到可靠的数据源显得尤为重要。这时,爬虫抓取网址就成了一个高效便捷的方式。
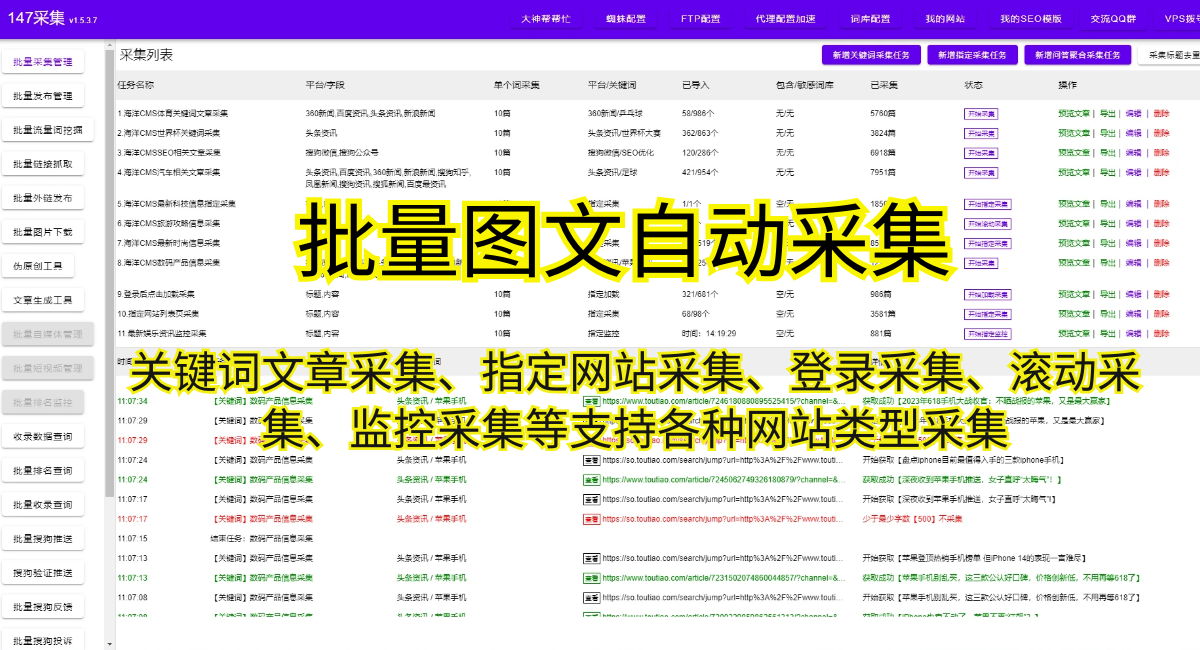
爬虫是一种自动化程序,可以模拟人类在网络上的行为,通过网络抓取指定网页上的信息。通过爬虫抓取网址,我们可以获取到网络上的各种数据,如新闻、gupiao行情、商品信息、论坛帖子等。通过分析这些数据,我们可以实现各种功能,如数据分析、信息检索、推荐系统等。
爬虫抓取网址的必要性在于,它能够帮助我们快速获取到大量的数据,节省了手动收集数据的时间和人力成本。特别是对于一些需要实时数据的应用程序来说,爬虫可以实时抓取最新的数据,保证了数据的准确性和时效性。此外,通过爬虫抓取网址,我们还可以获取到一些公开的数据,如政府公告、企业公示等,对于研究者和决策者来说,这些数据非常有价值。
要实现爬虫抓取网址,我们可以使用各种编程语言和工具。Python是一种常用的编程语言,拥有丰富的爬虫库和工具,如BeautifulSoup、Scrapy等。这些工具提供了丰富的功能,可以帮助我们快速开发和部署爬虫程序。此外,还有一些云pingtai,如阿里云、腾讯云等,提供了爬虫服务,可以免去搭建服务器、维护程序等繁琐的工作。
在使用爬虫抓取网址时,我们也要遵守一些规则和道德准则。首先,我们应该遵守网站的相关规定,尊重网站的使用规则和隐私政策。不应该通过爬虫抓取网址侵犯他人的合法权益,如dao取个人信息、发布垃圾信息等。其次,我们应该设置适当的爬取速度,避免对网站造成过大的负担和影响网站的正常运行。
总之,爬虫抓取网址是一种高效获取网络数据的方式,对于那些需要大量数据支持的应用和研究者来说,它具有显著的优势。通过合理、合法地使用爬虫技术,我们可以获取到丰富的数据ZY,为我们的应用程序和研究工作提供有力的支持。



