
掌握爬虫技术,轻松抓取网站数据
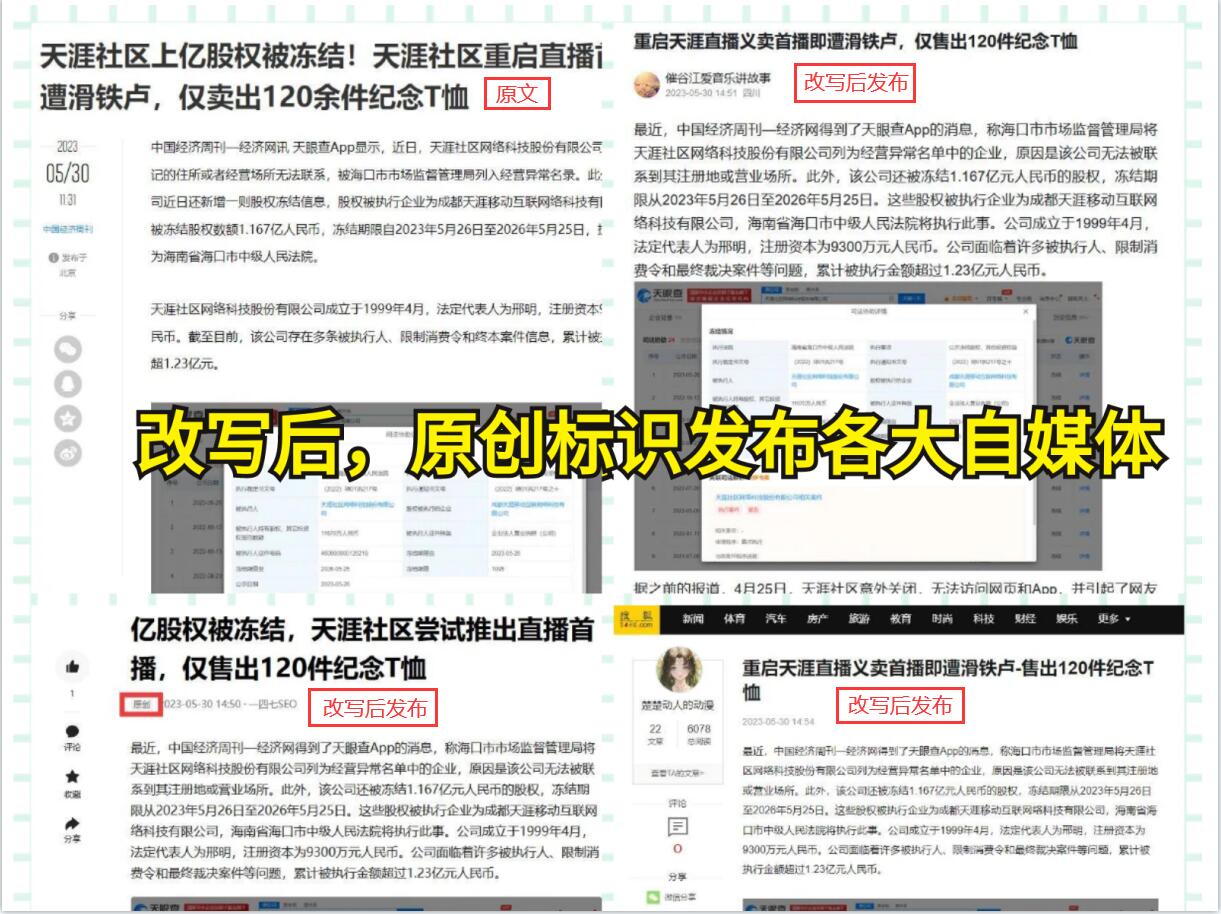
随着互联网的发展和数据的爆炸式增长,如何获取和利用海量的网络数据已成为现代社会的重要课题。而爬虫技术作为一种高效的数据采集手段,正在逐渐受到广泛关注和应用。本文将为大家介绍爬虫技术的基本概念和应用,以及如何使用爬虫工具抓取网站数据,并利用数据进行分析和应用。
什么是爬虫?
简而言之,爬虫就是一种自动化程序,用于从网页中获取所需的信息。它可以模拟浏览器行为,访问互联网上的各种ZY,并将获取到的数据进行整理和存储。通过编写爬虫程序,我们可以很轻松地获取到网站上的各种信息,如新闻、商品、用户评论等。
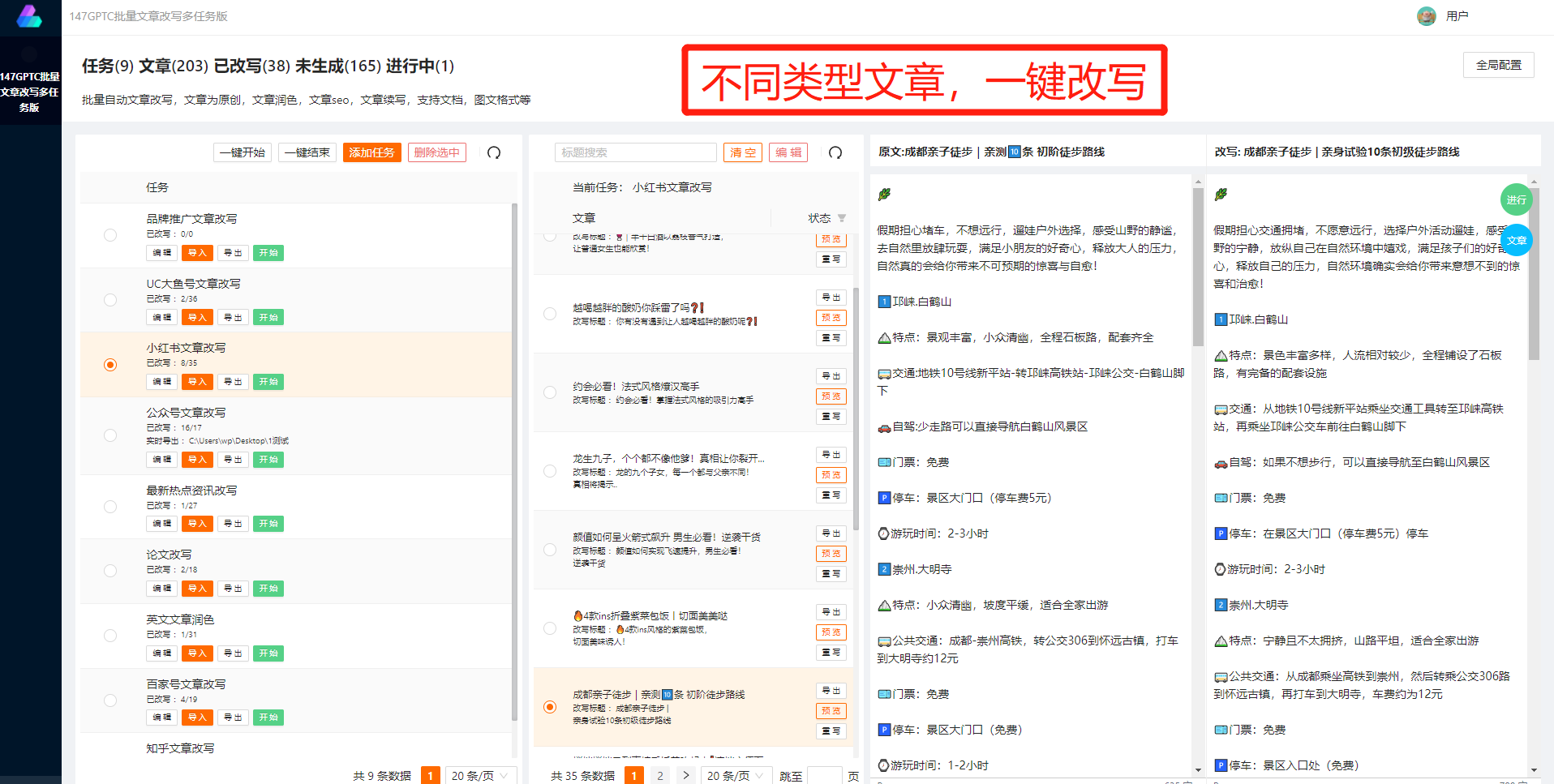
如何使用爬虫抓取网站数据?
使用爬虫抓取网站数据的基本步骤如下:
1.确定目标网站:首先要确定要抓取的目标网站,并了解其网页结构和数据存放方式。
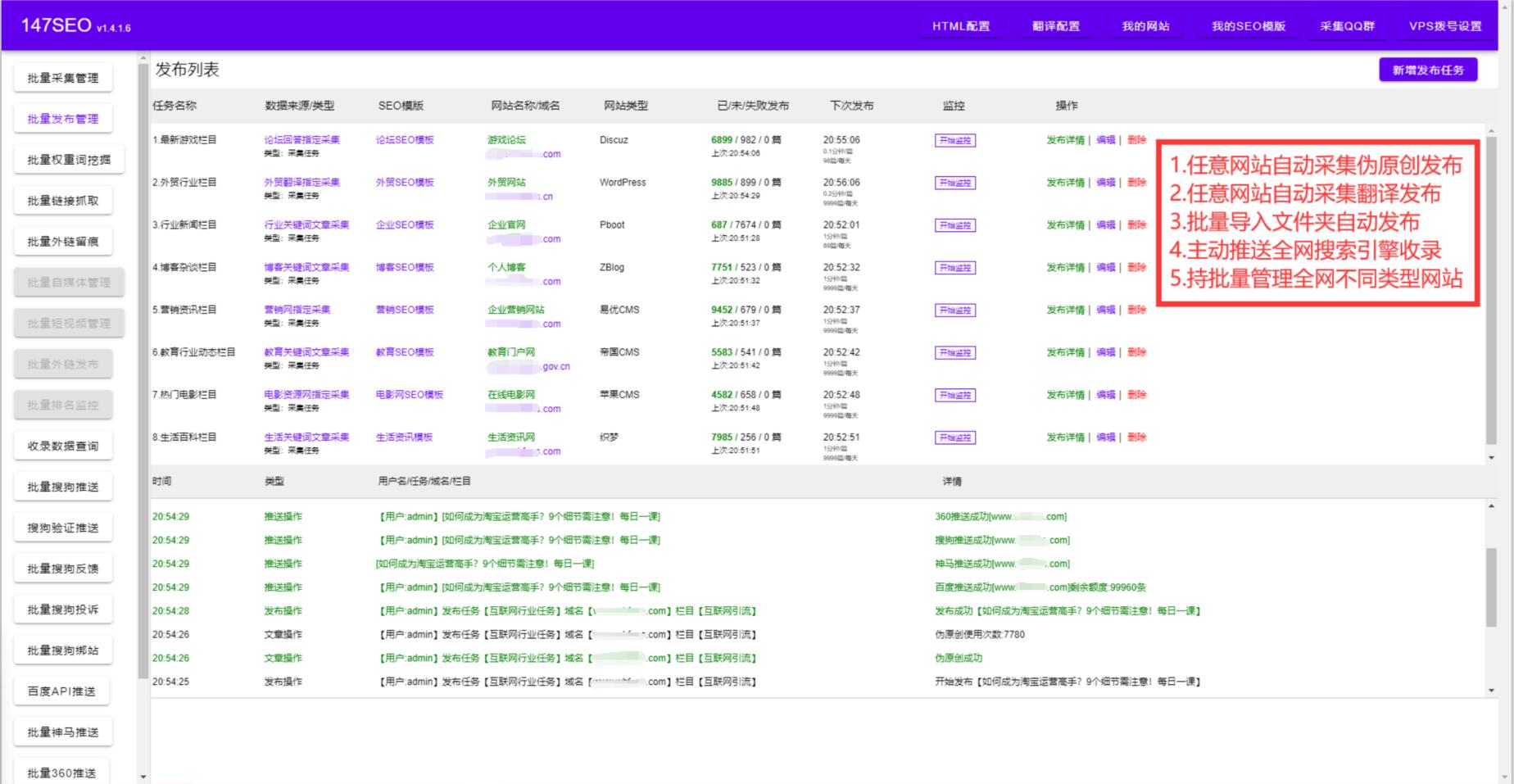
2.选择合适的爬虫工具:根据目标网站的特点,选择合适的爬虫工具。目前常用的爬虫工具有Scrapy、BeautifulSoup、Selenium等。
3.编写爬虫程序:根据网页结构和数据存放方式,编写爬虫程序,指定需要抓取的数据和存储方式。
4.运行爬虫程序:通过运行爬虫程序,爬虫工具会自动访问目标网站,按照设定的规则抓取数据,并将数据存储到指定的位置。
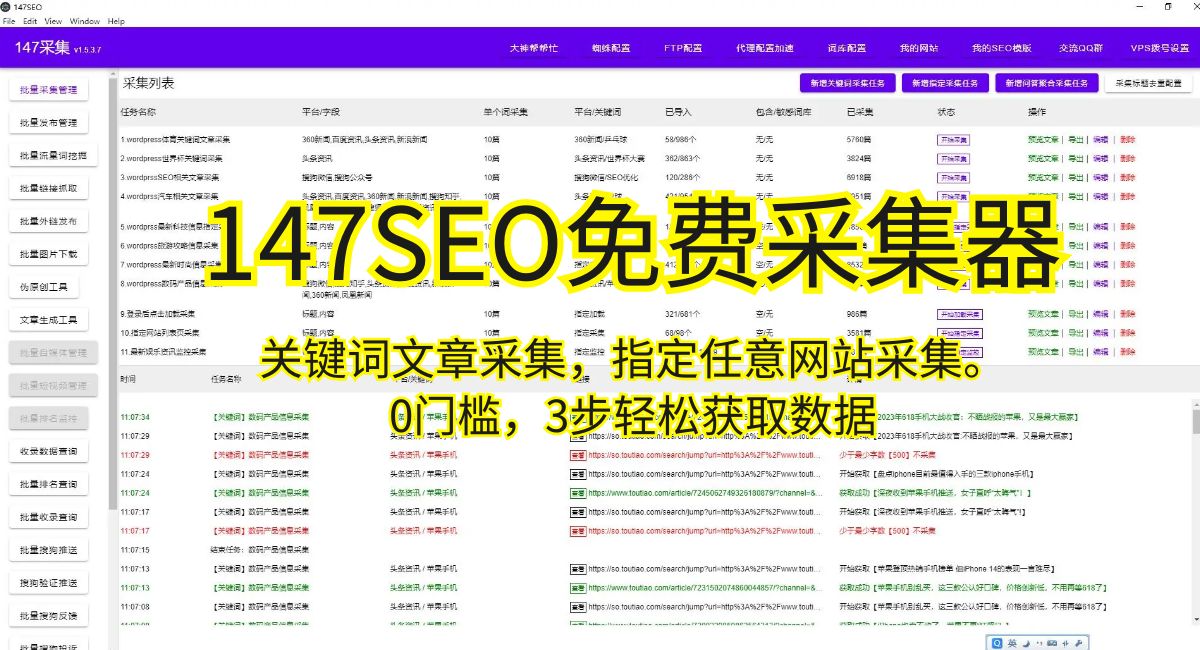
数据分析与应用
抓取到的网站数据可以进行各种分析与应用,例如:
1.市场调研:通过抓取竞争对手网站的数据,了解市场趋势和竞争态势,为制定营销策略提供依据。
2.舆情监控:通过抓取和分析各种网络数据,包括新闻、社交媒体等,了解公众舆论和意见动向,及时应对危机和问题。
3.数据挖掘:通过抓取和分析海量数据,发现隐藏的规律和关联性,为企业决策提供参考。
总结
爬虫技术作为一种高效的数据采集手段,正日益受到广泛关注和应用。通过使用爬虫工具,我们可以轻松地抓取网站数据,并利用数据进行分析和应用。无论是市场调研、舆情监控还是数据挖掘,都需要掌握爬虫技术来获取所需的数据。因此,掌握爬虫技术对于数据分析和应用来说是至关重要的。希望本文对您有所启发,让您更好地了解和应用爬虫技术。



