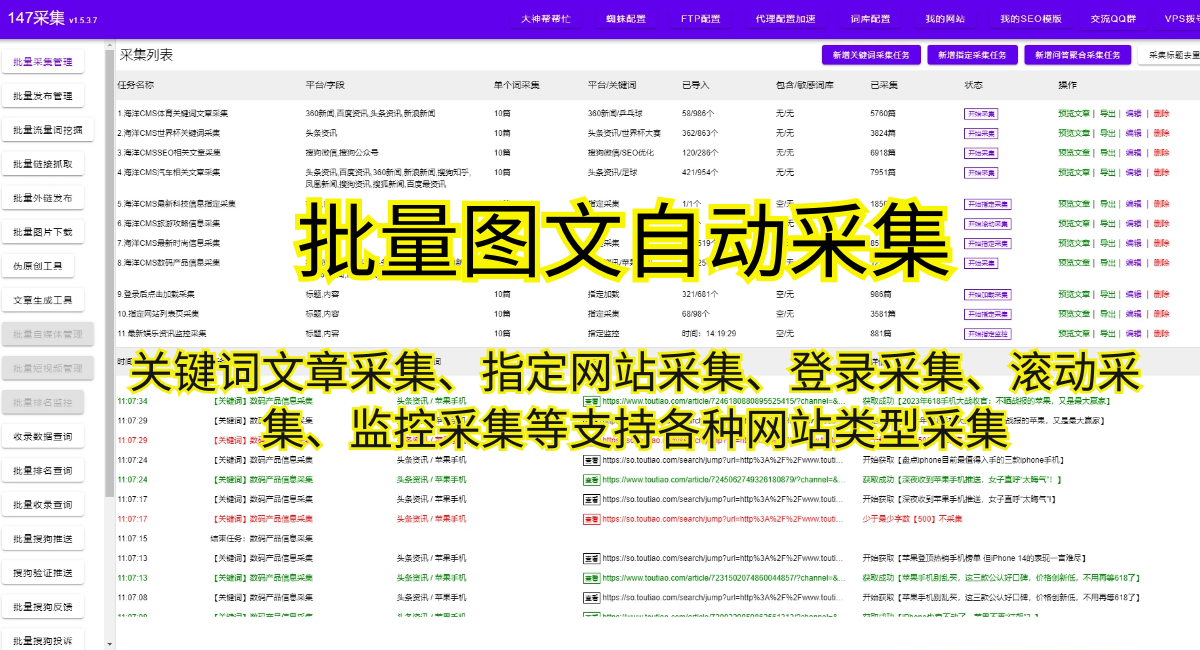
如今,随着互联网的发展,大量的数据储存在各种网站上。当我们需要这些数据时,手动访问并逐个复制粘贴变得低效且容易出错。幸运的是,爬虫技术的出现解决了这个问题,它可以自动化地从网站上抓取所需的数据。
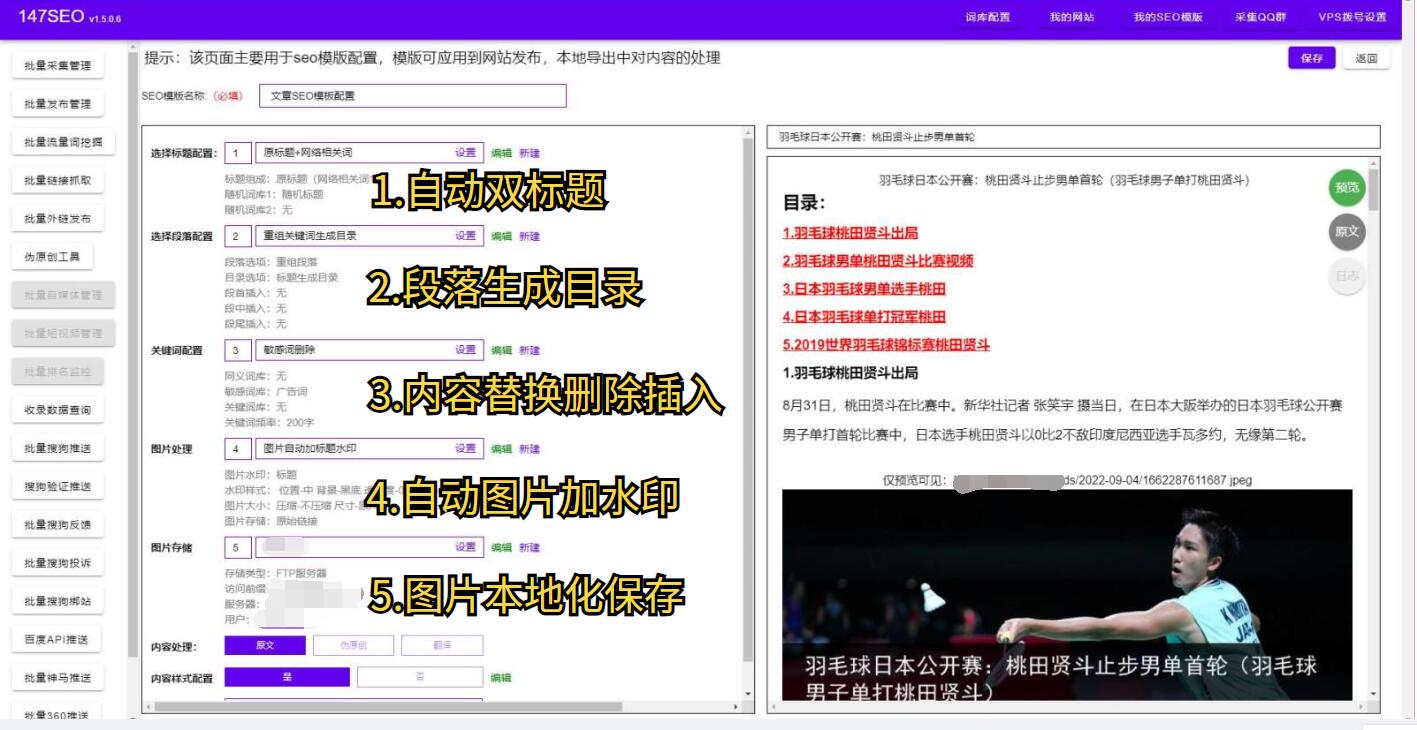
首先,我们需要了解爬虫技术。简单来说,爬虫是一种自动化程序,可以模拟人类在互联网上浏览网页的行为,获取网页上的数据。爬虫技术是一门复杂的技术,需要学习和掌握相关的知识和技能。幸运的是,有很多成熟的软件工具可以帮助我们实现这一目标。
一个常用的爬虫工具是Scrapy。它是一个强大的Python框架,专门用于爬取网站数据。Scrapy提供了丰富的功能和灵活的配置选项,可以轻松地抓取网站上的数据。它还支持多线程和分布式爬虫,可以提高爬虫效率。因此,对于那些想要掌握爬虫技术的人来说,Scrapy是一个不错的选择。
另一个流行的爬虫工具是BeautifulSoup。它是基于Python的库,用于解析HTML和XML文档。BeautifulSoup提供了一套简单而强大的API,可以快速地定位和提取所需的数据。相比于Scrapy,BeautifulSoup更适合那些只需简单的抓取任务的人。
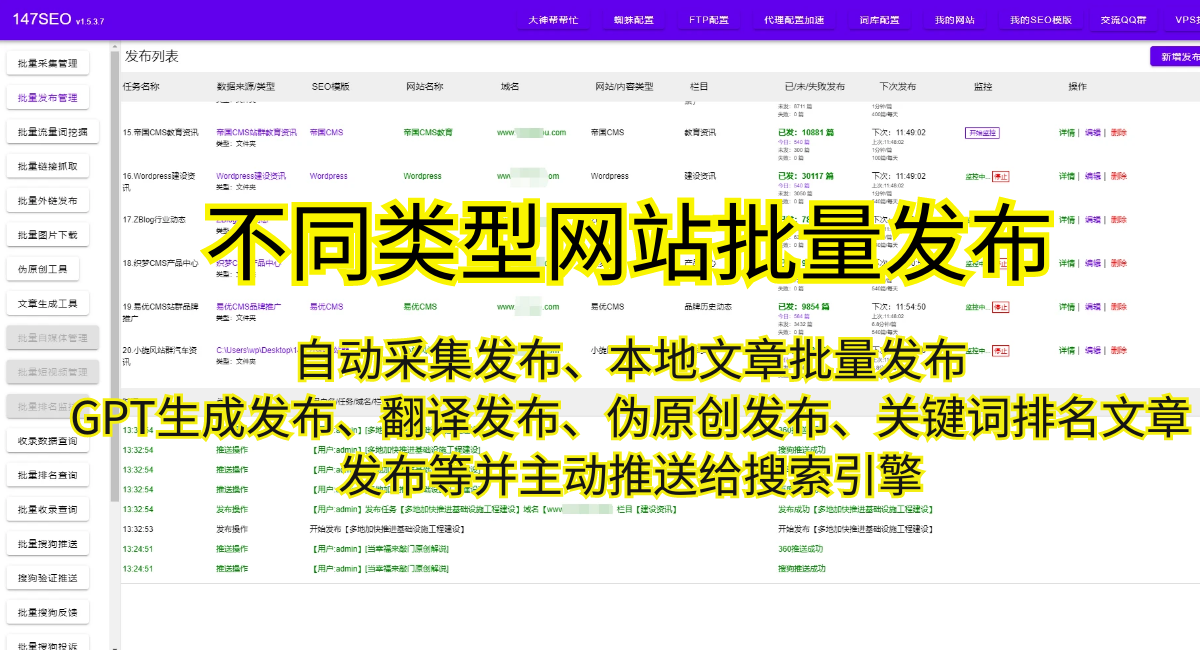
除了上述工具,还有一些商业化的爬虫软件可供选择,如Octoparse、WebHarvy等。这些软件通常提供了更友好的用户界面和更简便的操作方式,但功能相对较为有限。如果你只需要进行简单的抓取任务,并且不想花太多时间学习和配置爬虫,这些软件可能是不错的选择。
在使用爬虫技术时,我们需要注意一些规则和道德问题。首先,我们应该尊重网站的隐私政策和使用条款。有些网站可能会明确禁止使用爬虫程序,我们应该遵守相关规定。此外,我们还需要避免对目标网站造成过大的负担,可以通过控制爬虫的访问频率和速度来达到这一目的。
总而言之,爬虫技术是一种强大而有用的技术,可以帮助我们自动化地抓取网站上的数据。通过使用适当的爬虫工具,我们可以轻松地实现这一目标。然而,我们在使用爬虫技术时需要注意规则和道德问题,以确保我们的行为合法和合理。希望本文对你有所帮助!