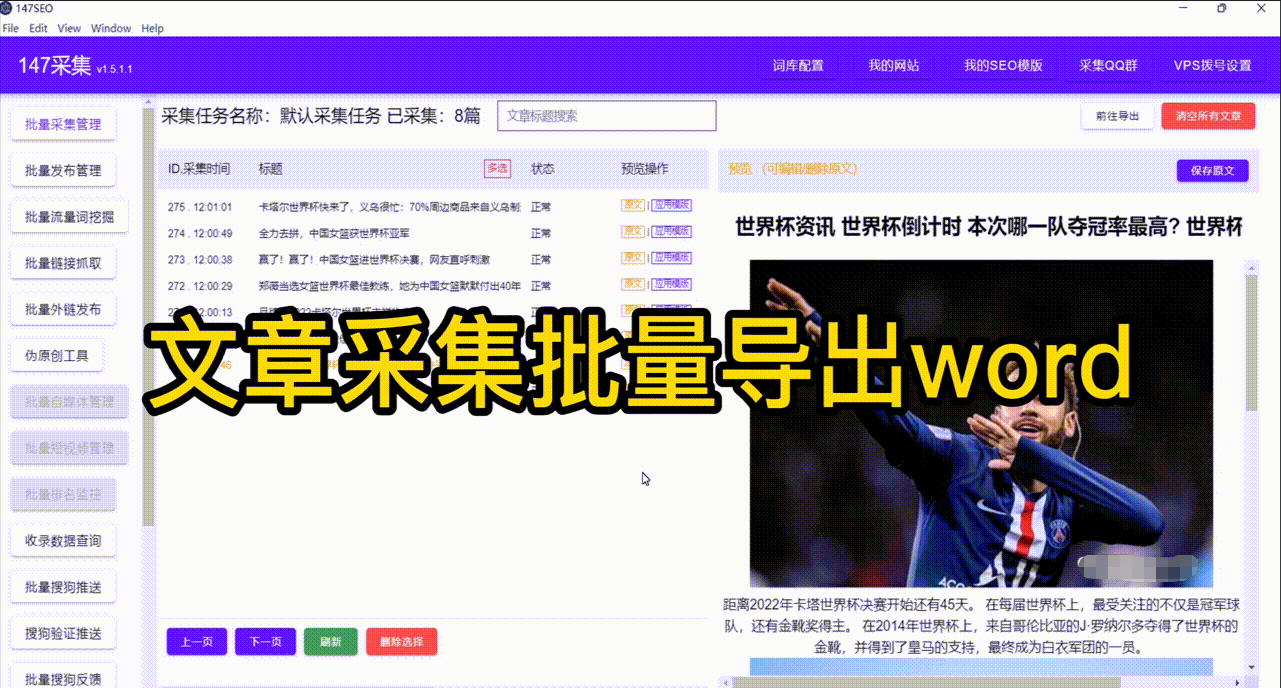
在信息时代,大量的数据隐藏在互联网海量的页面中,为了获取这些宝贵的信息,需要运用爬虫网站技术来进行数据抓取。那么,如何利用爬虫网站提高网络数据抓取效率,让我们一起来探讨一下。
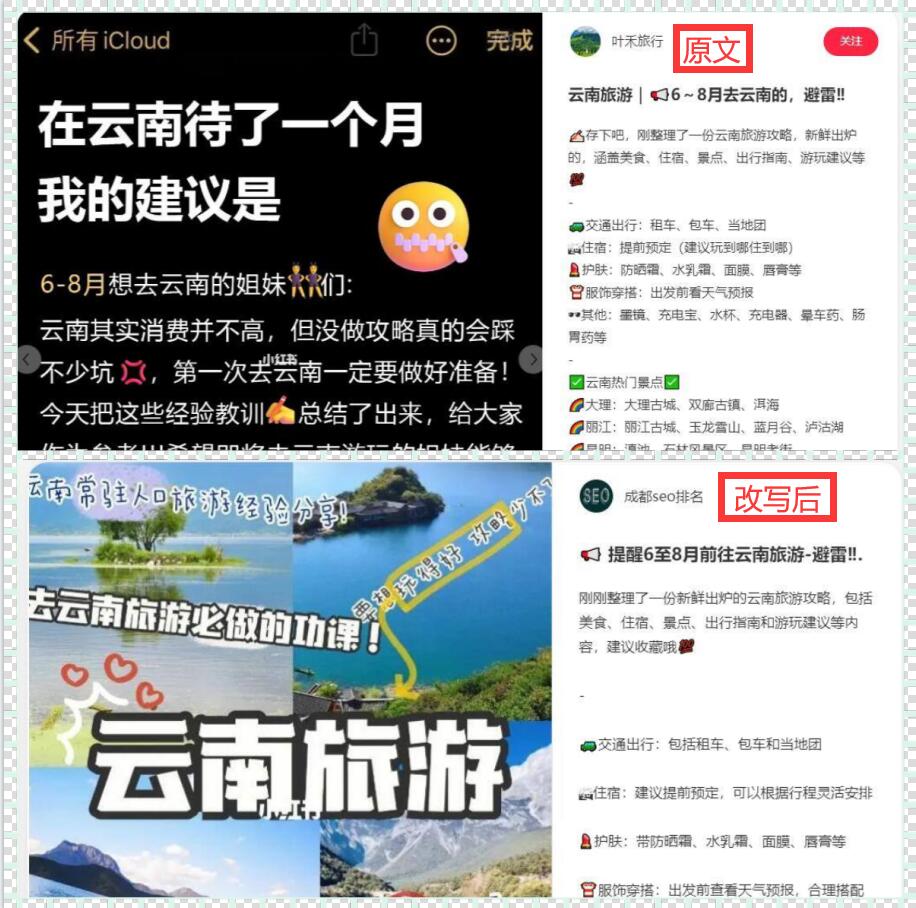
一、选择合适的爬虫网站工具 选择一个合适的爬虫网站工具是提高数据抓取效率的首要步骤。根据实际需求,可以选择Python中的Scrapy框架或BeautifulSoup库,或者PHP中的Goutte等工具。这些工具具有强大的功能,可以帮助我们快速、准确地抓取所需数据。
二、制定合理的抓取策略 在进行数据抓取前,需要制定合理的抓取策略,以确保数据的完整性和准确性。需要根据目标网站的结构、布局和反爬虫措施等因素来制定抓取规则,遵循网络礼仪和规则法规进行数据抓取。
三、设置合理的抓取间隔时间 为了不给被抓取网站带来过大的负担,并尊重网站的访问频率限制,我们需要设置合理的抓取间隔时间。可以通过合理设置User-Agent、Referer、Cookie等请求头信息,减少网站对爬虫的阻拦机制,并合理控制数据抓取频率。
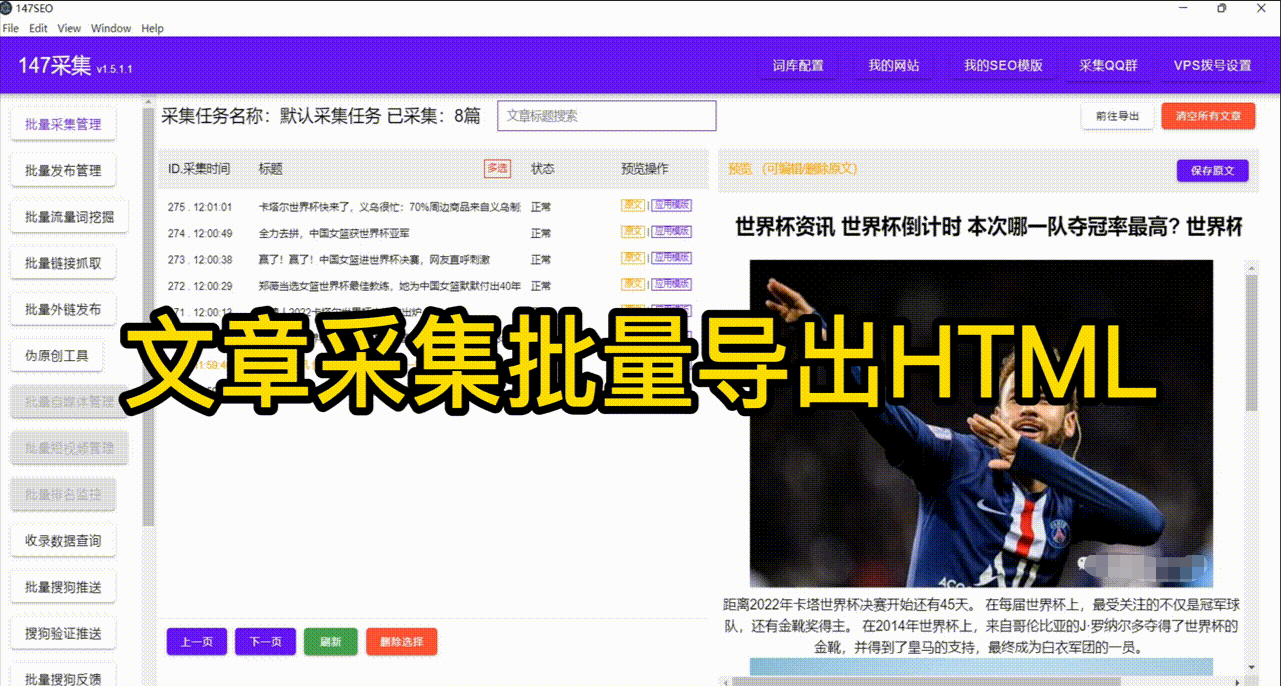
四、处理反爬虫措施 许多网站为了防止爬虫抓取数据,会设置各种反爬虫措施,如验证码、登录限制、IP封锁等。在遇到这些反爬虫措施时,我们可以采用验证码识别技术、账号模拟登录或使用代理IP等方法来解决。尽量避免对被抓取网站造成困扰,并合法合规地进行数据抓取。
五、优化数据存储和处理 在进行数据抓取后,需要对获取的数据进行存储和处理。可以选择将数据存储到数据库中,或使用数据分析工具进行处理和分析。同时,在存储和处理数据时,需要注意数据的去重、清洗和格式转换等问题,以保证数据的质量和可用性。
总结起来,利用爬虫网站技术提高网络数据抓取效率需要选择适合的工具、制定合理的策略、设置合理的抓取间隔时间、处理反爬虫措施,以及优化数据存储和处理等方面。同时,我们也要注意合法合规地进行数据抓取,遵循网络礼仪和规则法规。希望本文对读者有所帮助,并在实际应用中发挥其作用。