在当今信息爆炸的时代,准确、及时获取所需数据是工作效率的重要保障之一。而在大量的网络信息中获取所需内容是一个繁琐且耗时的过程。然而,使用爬虫这一神奇工具,可以简化数据获取流程,提升工作效率。
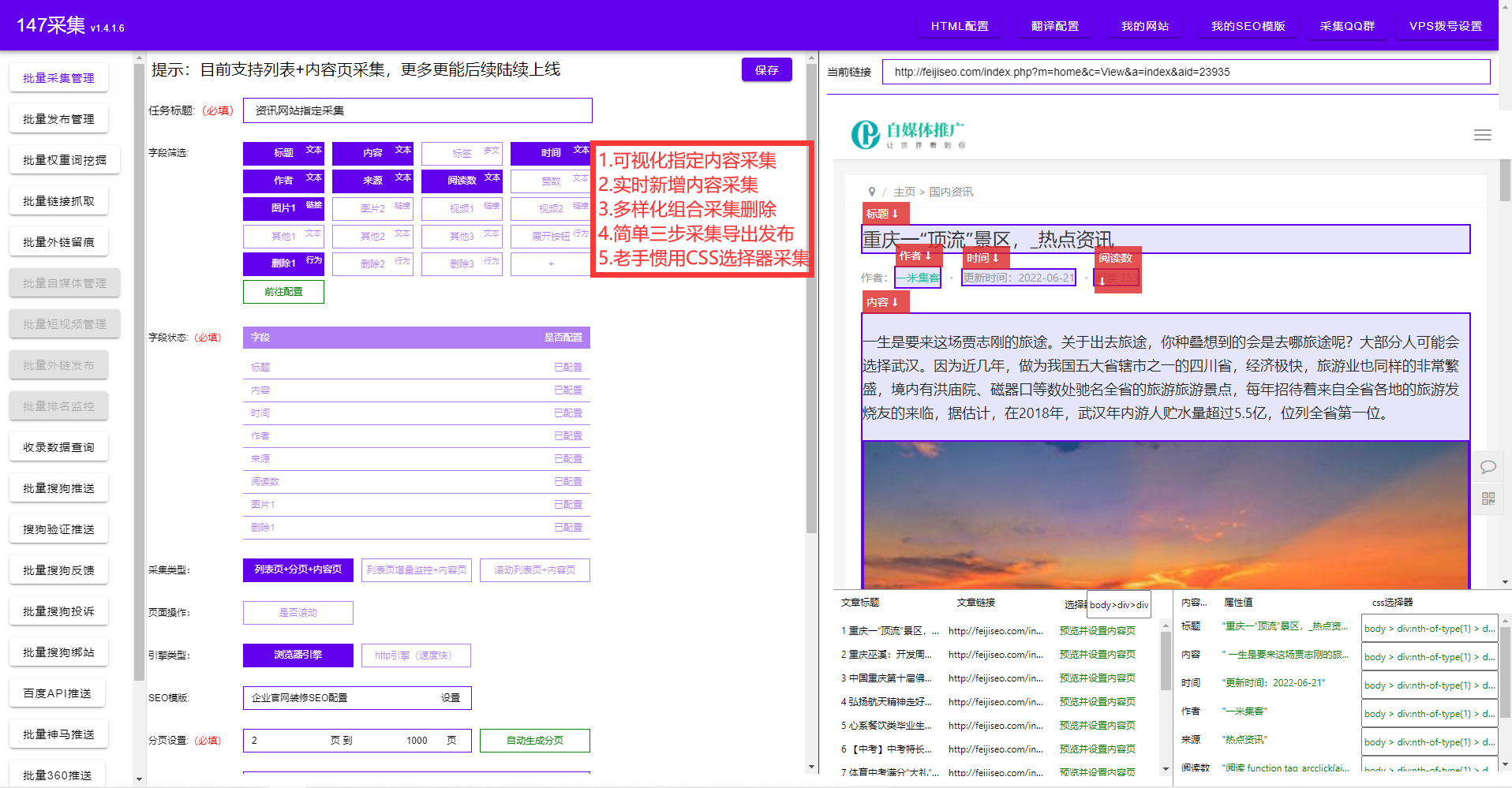
爬虫是一种自动化程序,用于在互联网上爬取和解析网页数据。通过制定规则,它可以自动抓取网页上的各种数据,并将其保存或分析。爬虫可以模拟人类浏览器的行为,具有自动化、高效性的特点。
使用爬虫获取网页数据有许多优势。首先,爬虫可以迅速抓取大量网页数据。与人工抓取相比,它的速度更快,可以在短时间内搜集大量信息。其次,爬虫可以解析网页上的结构化数据,并以易于处理的格式存储。这意味着数据可以直接用于后续的分析和应用。此外,爬虫还可以定期自动化地获取数据,并实时更新,保证数据的及时性和准确性。
在实际应用中,爬虫获取网页数据有着广泛的应用场景。例如,市场调研人员可以使用爬虫获取竞争对手的产品信息和销售数据,以辅助制定营销策略。新闻媒体可以使用爬虫实时抓取各大网站的头条新闻,以快速了解时事动态。金融机构可以利用爬虫收集和分析企业的财务数据,以评估投资价值。等等。爬虫的应用领域非常广泛,几乎涵盖了所有需要获取网络数据的领域。
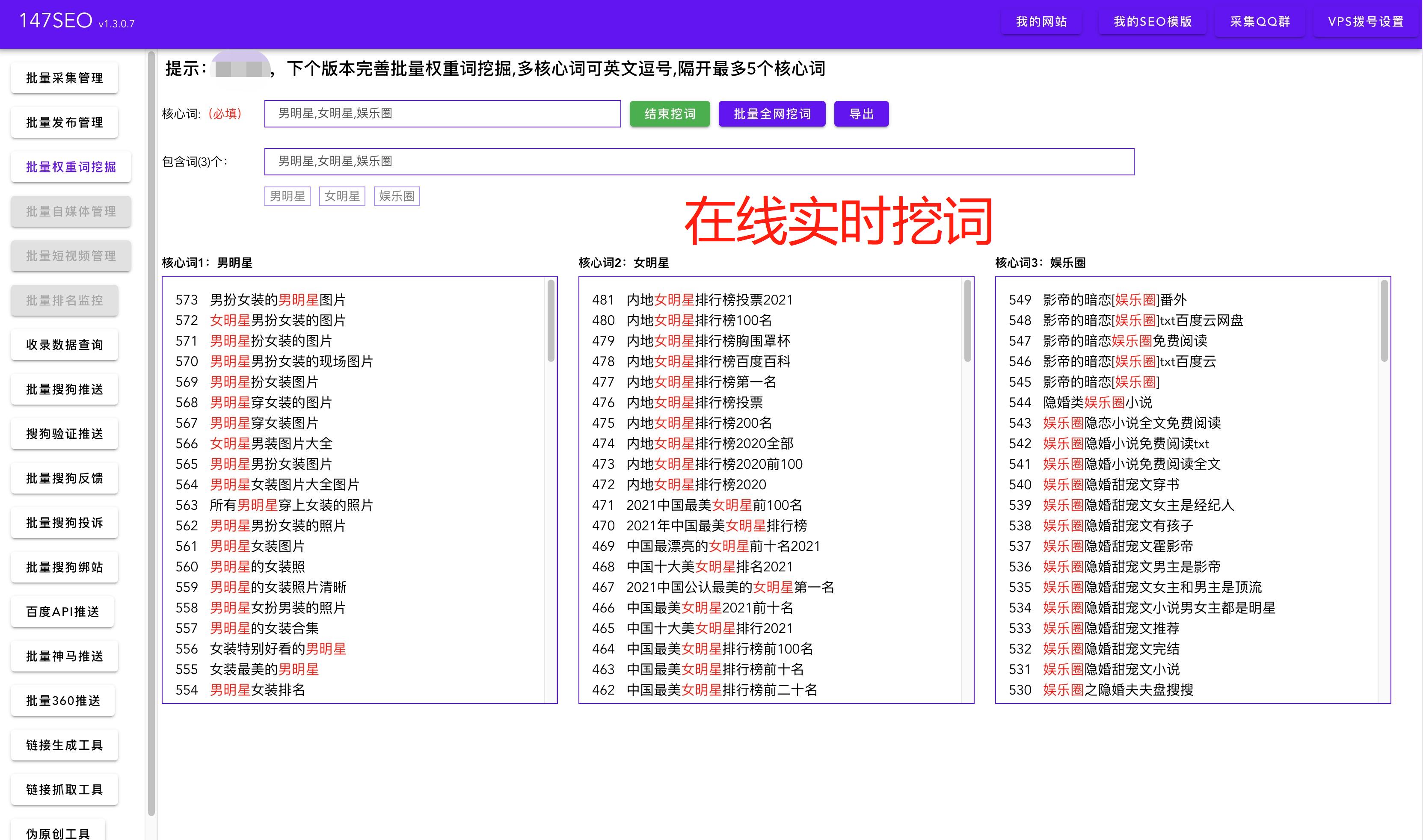
爬虫获取网页数据并不复杂。一般而言,需要以下几个步骤。首先,确定需求,明确需要抓取的网页和所需数据。然后,编写爬虫程序,制定抓取规则,并添加相应的页面解析逻辑。接着,运行爬虫程序,开始抓取数据。最后,对获取到的数据进行清洗和整理,以便后续的应用。
当然,使用爬虫进行数据获取也要注意一些道德和规则规范。在爬取数据时,应尊重网站的规则和要求,遵循相关规则法规,不得进行非法行为。此外,还应注意数据的使用权限和隐私保护,不得滥用他人的数据。
总结一下,爬虫获取网页数据是一种高效、快速的数据采集方式,可以帮助我们提升工作效率。通过使用爬虫,我们可以迅速抓取大量数据,并以易于处理的格式保存和分析。爬虫在各行各业都有着广泛的应用,是一种非常强大的工具。当然,在使用爬虫的过程中,我们也应该遵循相关规则法规和道德规范,保护数据使用的合法性和隐私权益。