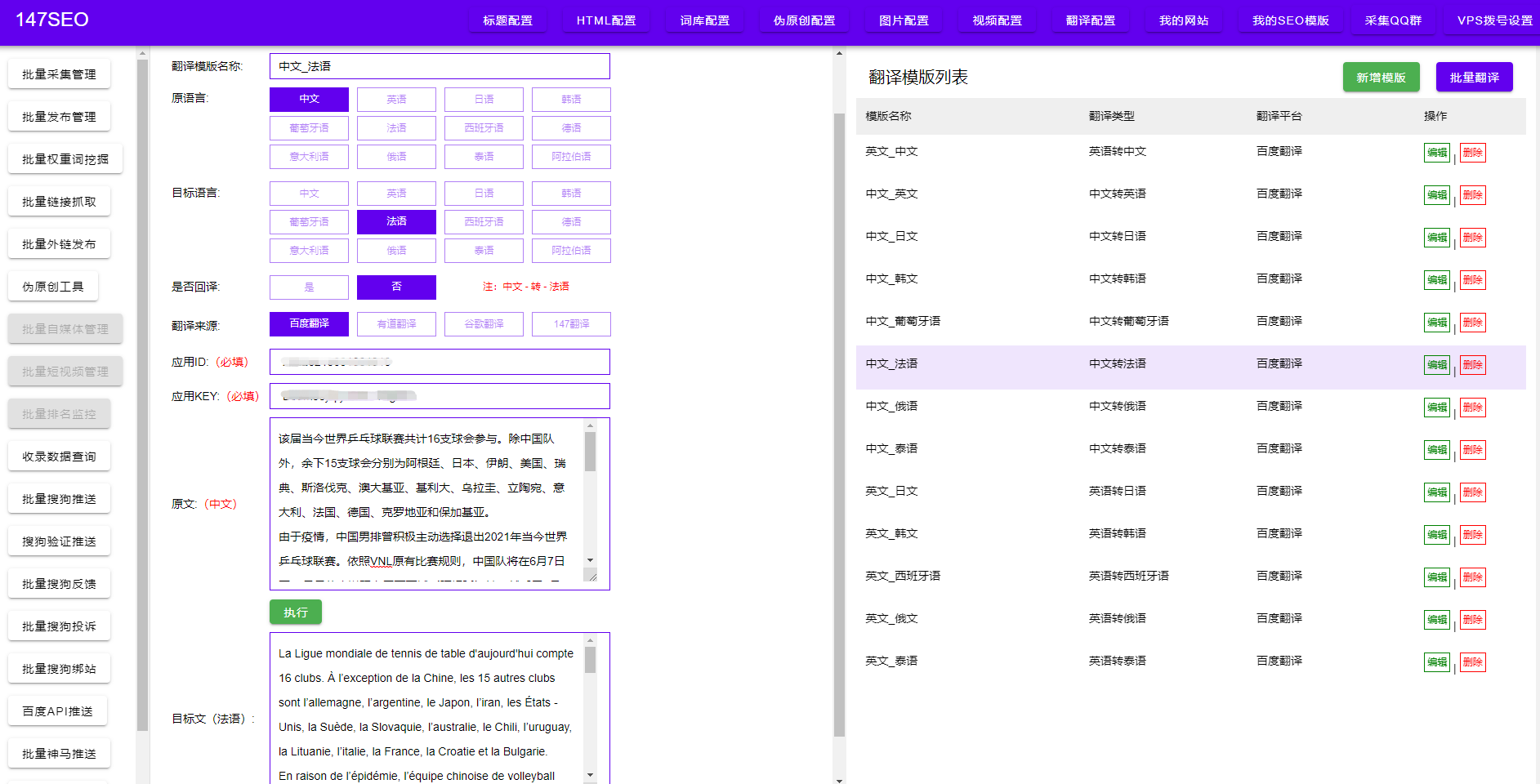
互联网上的丰富数据ZY为各行各业的发展提供了巨大的机遇和挑战。而要获取这些数据中的有用信息,爬虫技术便成为了一种不可或缺的工具。本文将分享一些关于如何使用爬虫来爬取网页数据的技巧和编程要点。
首先,为了更好地理解爬虫技术,我们需要明确爬虫的工作原理。简单来说,爬虫是通过模拟浏览器的行为,自动访问所需网页并提取其中的数据。一般而言,爬取网页数据的过程可以分为以下几个步骤:发起请求、获取响应、解析数据、存储数据。现在,我们来逐步介绍。
首先,发起请求是指向目标网页发送请求的过程。在发送请求之前,我们需要确定所需数据的来源和格式,以及指定需要抓取的网页URL。通常,我们可以使用Python编程语言中的requests库来发送HTTP请求,获取网页的响应内容。此外,还需注意设置合适的请求头部信息,以模拟浏览器的行为。
获取响应后,我们需要对响应内容进行解析,以提取所需数据。其中,HTML和XML是常见的网页标记语言,可以使用一些解析库,如BeautifulSoup或lxml,来解析网页内容。通过这些库,我们可以按照标签、属性或Xpath等规则提取出所需的数据。
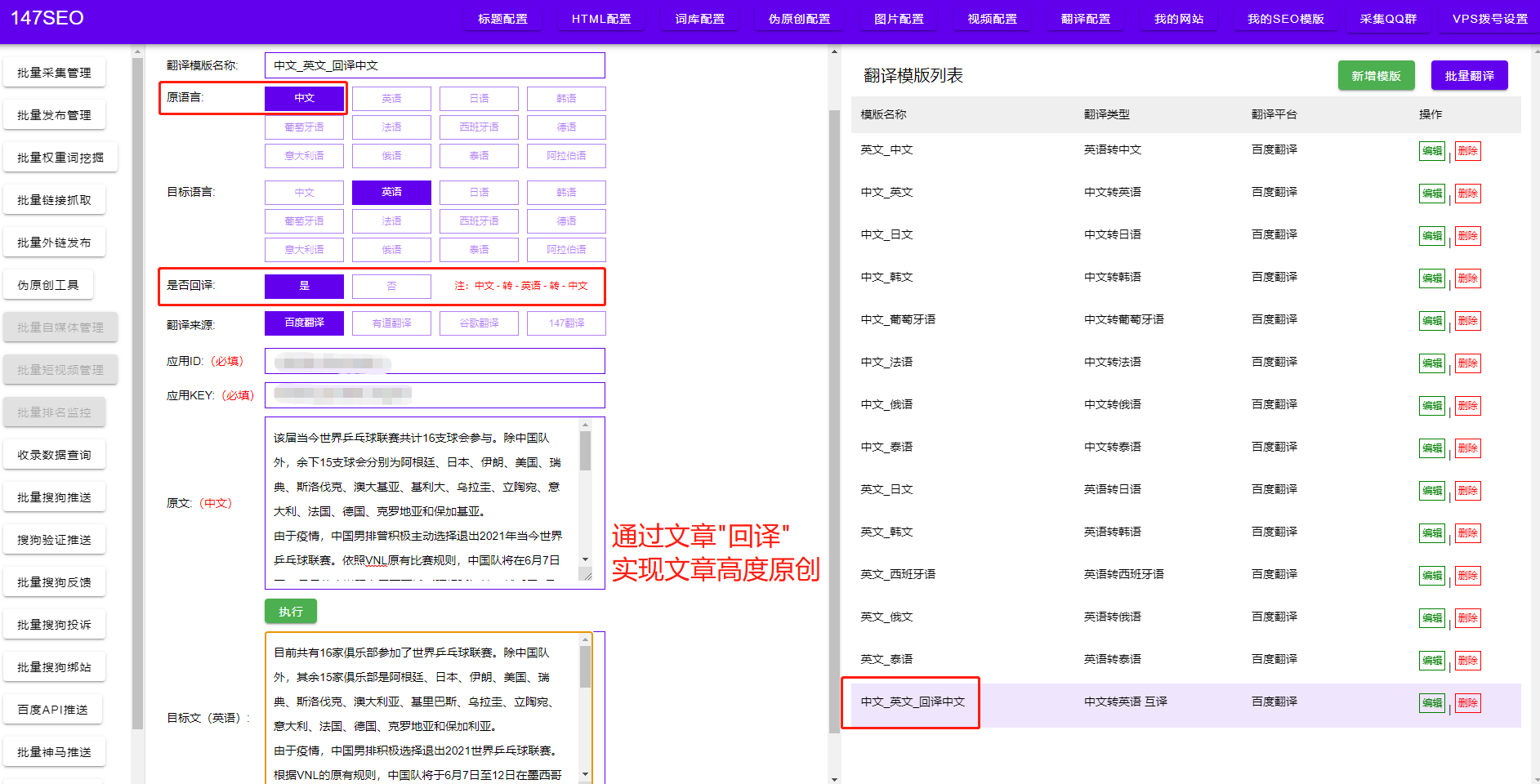
在解析数据的基础上,为了更好地存储数据,我们可以使用JSON格式来保存爬取的数据。JSON是一种轻量级的数据交换格式,易于阅读和解析。Python中的json库提供了简单方便的方法来处理JSON数据。我们可以将解析得到的数据转换为JSON对象,并进行存储和后续处理。
此外,在进行数据爬取时,还需了解一些编程技巧和注意事项。首先,合理设置爬虫访问的速度,避免给网站服务器带来过大的负担。设置合理的请求间隔,或使用代理IP,可以有效避免被封锁或限制访问。其次,了解网站的反爬虫策略和规则,避免触发网站的反爬机制。可以通过模拟登录、使用验证码识别库等方式来绕过一些简单的反爬机制。最后,要注意规则和道德的约束,遵守网络数据采集的相关规定和原则,避免侵犯他人的权益。
总而言之,使用爬虫技术来获取网页数据是一项复杂而有挑战性的任务。本文介绍了爬虫的基本原理以及一些技巧和编程要点。通过充分理解和掌握这些内容,我们可以更好地应对数据爬取的需求,并从海量的网页数据中获取有用的信息,为各行各业的发展提供有力支持。