
在当今信息爆炸的时代,网络世界蕴藏着丰富的宝藏,想要全面了解一个域名下的全部信息是一项极其重要的任务。幸运的是,爬虫技术的发展为我们提供了强大的工具,使我们能够轻松地爬取一个域名下的全部网页,从中获取宝贵的数据。
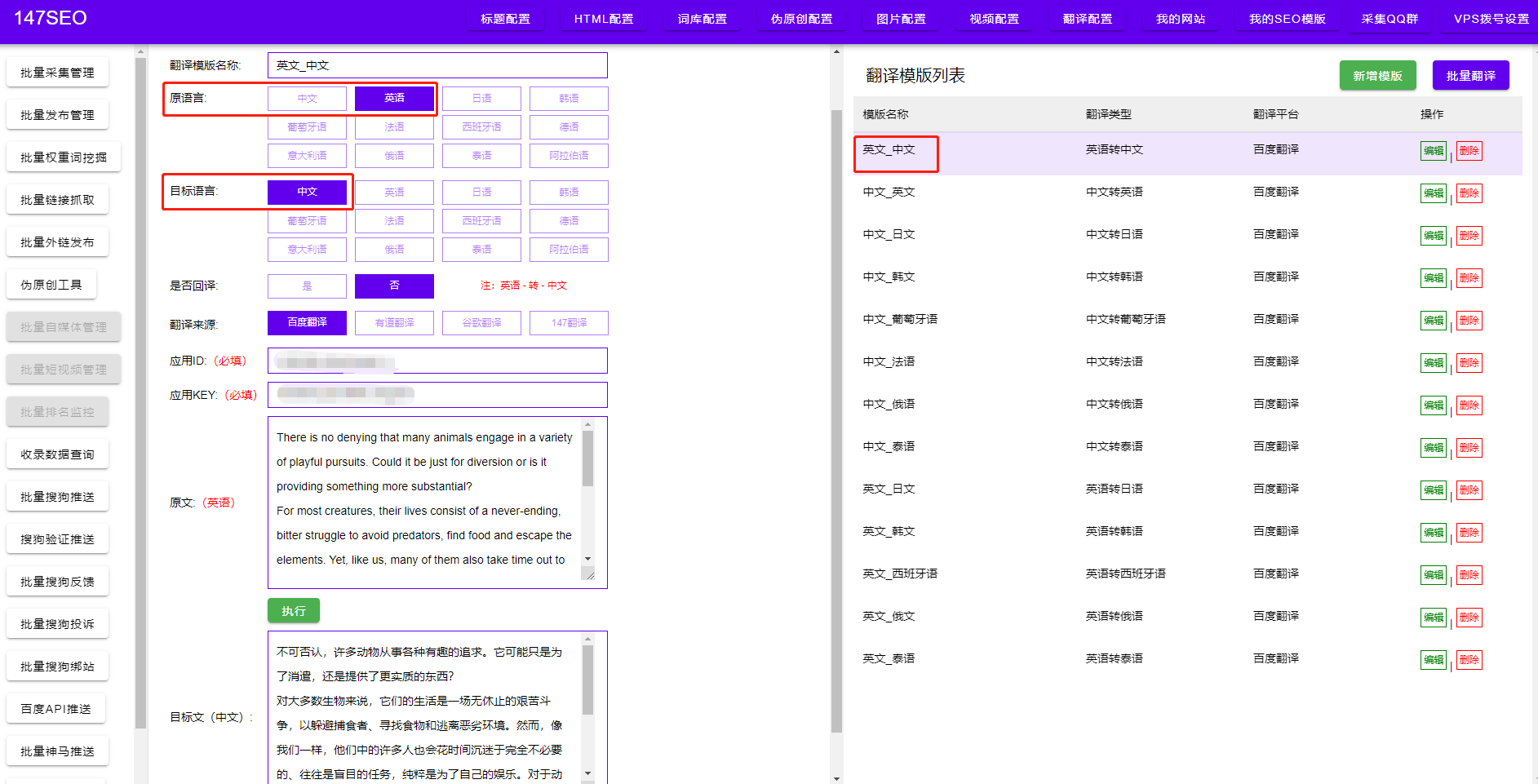
爬虫技术是一种模拟浏览器行为的自动化程序,通过发送HTTP请求,获取网页的HTML源代码,从中提取出所需的信息。它可以在很短的时间内访问和分析大量的网页,从而帮助我们了解网页的结构、内容和链接,提取其中的关键信息。
要想爬取一个域名下的全部网页,首先需要确定需要爬取的域名,并设置起始网址。然后,通过发送HTTP请求获取网页源代码,并解析提取出其中的链接。接下来,我们对提取到的链接进行进一步的分析,判断是否为同一域名下的网页,并将这些新的网址加入待爬取的队列。通过递归地不断爬取和分析,我们可以逐步扩展爬取到的网页数量,最终获得一个域名下的全部网页。
爬取一个域名下的全部网页有许多实际应用,例如搜索引擎的建立和更新,网站的SEO优化,以及市场竞争的分析等。通过获取大量的网页数据,我们可以建立强大的搜索引擎,使用户能够快速找到所需的信息。同时,我们还可以通过分析网页内容和链接关系,对网站进行优化,提升网站的搜索排名。此外,利用爬取到的网页数据,我们可以深入了解竞争对手的产品和营销策略,从而制定更具竞争力的商业计划。
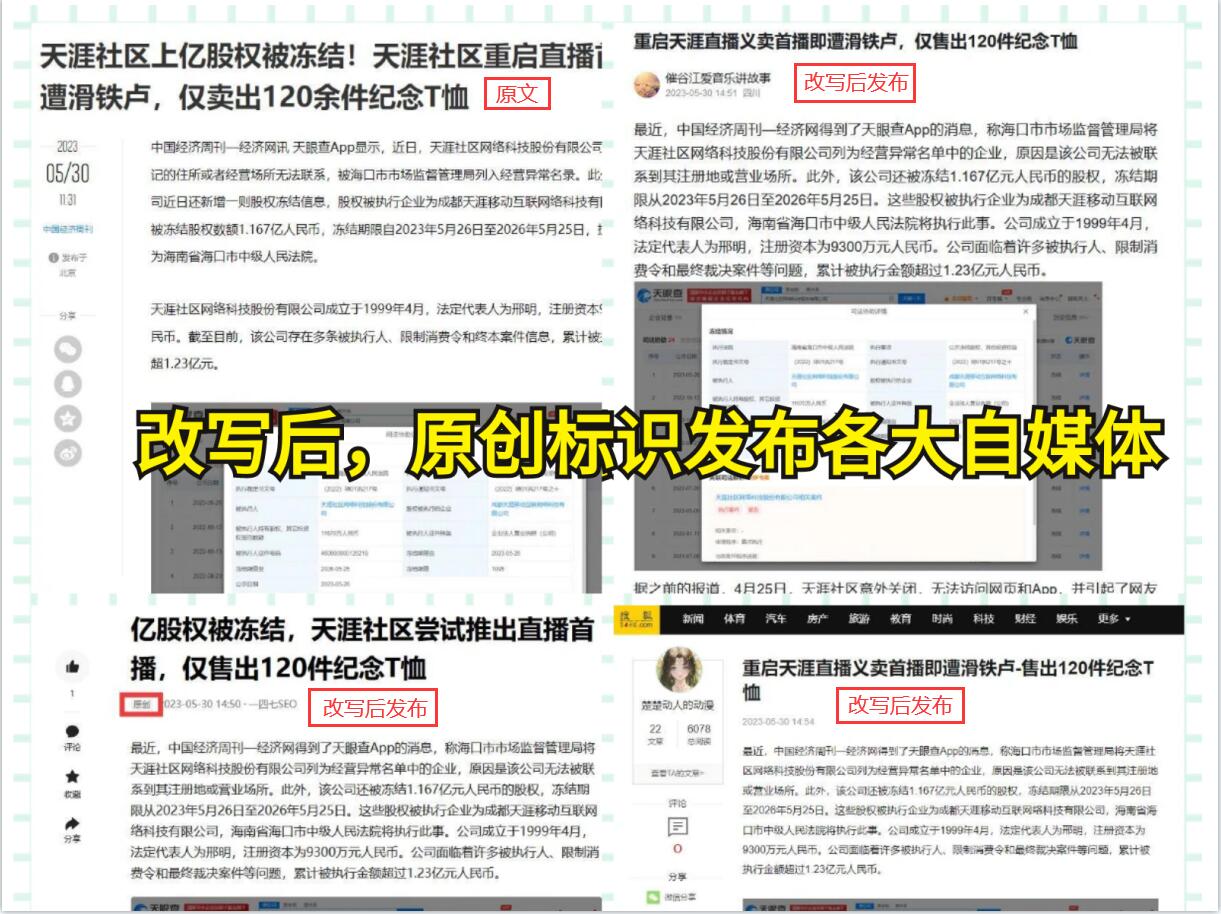
然而,爬取一个域名下的全部网页也面临一些挑战。首先,由于互联网的庞大规模,网页的数量可能会非常庞大,需要耗费大量的时间和ZY进行爬取。其次,网页的结构和内容可能千差万别,需要编写复杂的解析规则来提取所需的信息。此外,也需要解决反爬虫技术的挑战,如限制频繁请求和验证码等。
综上所述,爬取一个域名下全部网页是一项具有重要意义的技术任务,它可以帮助我们深度挖掘网络世界,从中获得宝贵的信息。作为数据挖掘的基础工具,爬虫技术的应用领域十分广泛,涉及搜索引擎、市场竞争分析、舆情监测等诸多领域。随着技术的进一步发展,我们有理由相信爬虫技术将在网络世界中发挥越来越大的作用,为我们带来更多的便捷和乐趣。


