
GPT是“GenerativePre-trainedTransformer”的缩写,意为生成式预训练变换器。它是一种基于人工智能技术的自然语言处理模型。GPT模型采用了Transformer架构,该架构在语言处理任务中表现出色,尤其是在机器翻译和文本生成方面。GPT模型是OpenAI公司开发的,旨在通过预先训练模型来改善语言处理任务的性能。
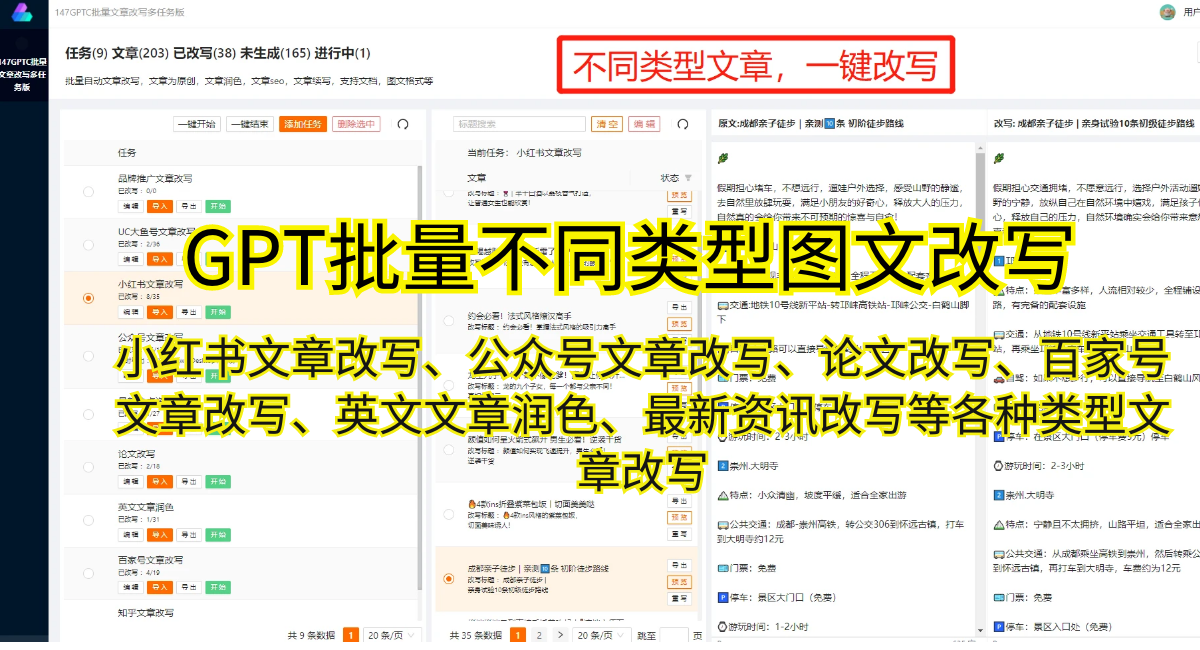
GPT模型的训练方式是通过对大量互联网文本进行自监督学习。这意味着GPT模型在训练阶段不需要人工标注的标签来指导学习,而是根据输入文本的上下文进行学习。通过预训练,GPT模型能够学习到语言的统计模式、语义关系和上下文理解等能力。
GPT的应用非常广泛。在自然语言处理领域,GPT模型可以用于机器翻译、文本摘要、自动对话系统、文本生成等任务。GPT模型在生成文本方面表现出色,用户可以利用GPT模型生成各种类型的文本,如新闻报道、故事情节、诗歌等。此外,GPT模型还可以应用于智能客服系统,为用户提供实时的问题解答和对话交流。
除了在自然语言处理领域,GPT模型还可以应用于其他领域,如图像处理和推荐系统等。通过将图像和文本进行联合训练,GPT模型可以实现图像的描述生成,并能够根据用户的兴趣和历史行为进行个性化的推荐。
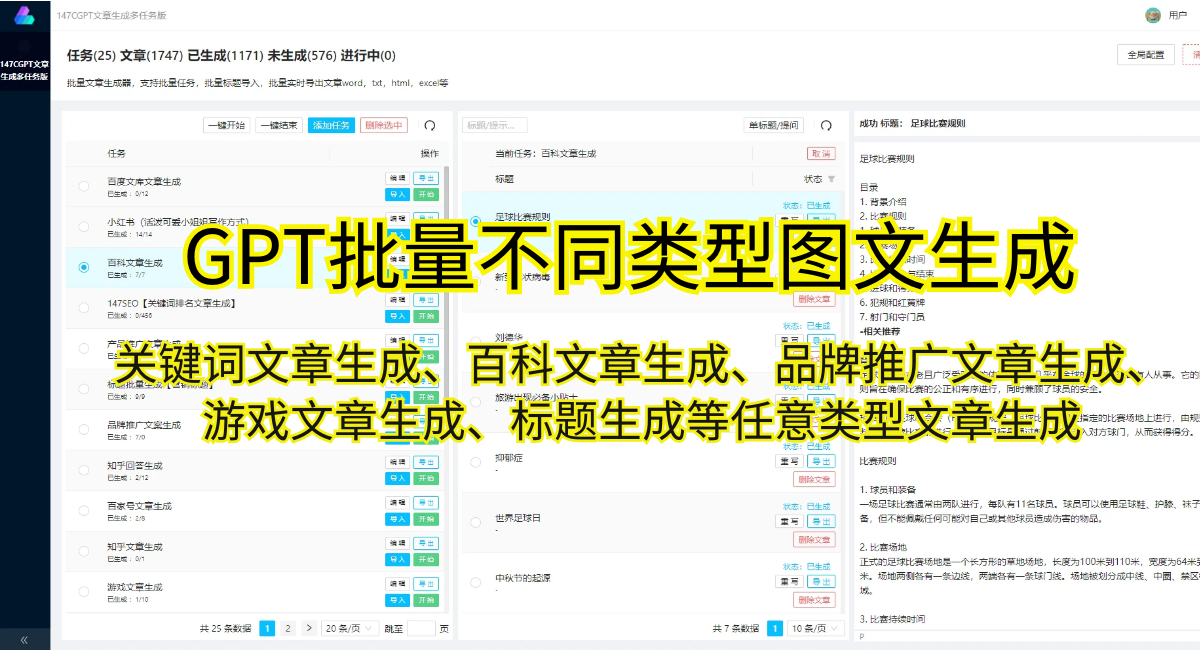
然而,GPT模型也存在一些挑战和问题。由于GPT模型是基于互联网文本进行预训练的,因此在特定领域的应用中可能会出现不能很好地处理领域专业术语和上下文的问题。此外,GPT模型在训练过程中也容易受到数据偏见的影响,导致生成的文本存在一定的倾向性。
总之,GPT是一种基于人工智能的自然语言处理模型,通过预先训练提供了很好的语言处理能力。它在机器翻译、文本生成、智能对话和推荐系统等方面具有广泛的应用前景。然而,开发人员在使用GPT模型时需要注意其局限性和潜在的偏见问题,以确保生成的文本符合预期和准确度的要求。



