
在人工智能领域探索的历程中,不断出现各种创新和突破,其中一个引人瞩目的里程碑是GPT-3Transformer。GPT-3Transformer是由OpenAI团队开发的一种深度学习模型,它利用了Transformer架构和大规模预训练的神经网络,能够生成令人惊叹的自然语言文本。
Transformer是一种基于自注意力机制的神经网络架构,它在自然语言处理任务中表现出色。而GPT-3Transformer则是在此基础上进一步发展的结果。该模型使用了1750亿个参数进行训练,是迄今为止最大规模的预训练模型之一。这使得GPT-3Transformer具备了极强的文本理解和生成能力。
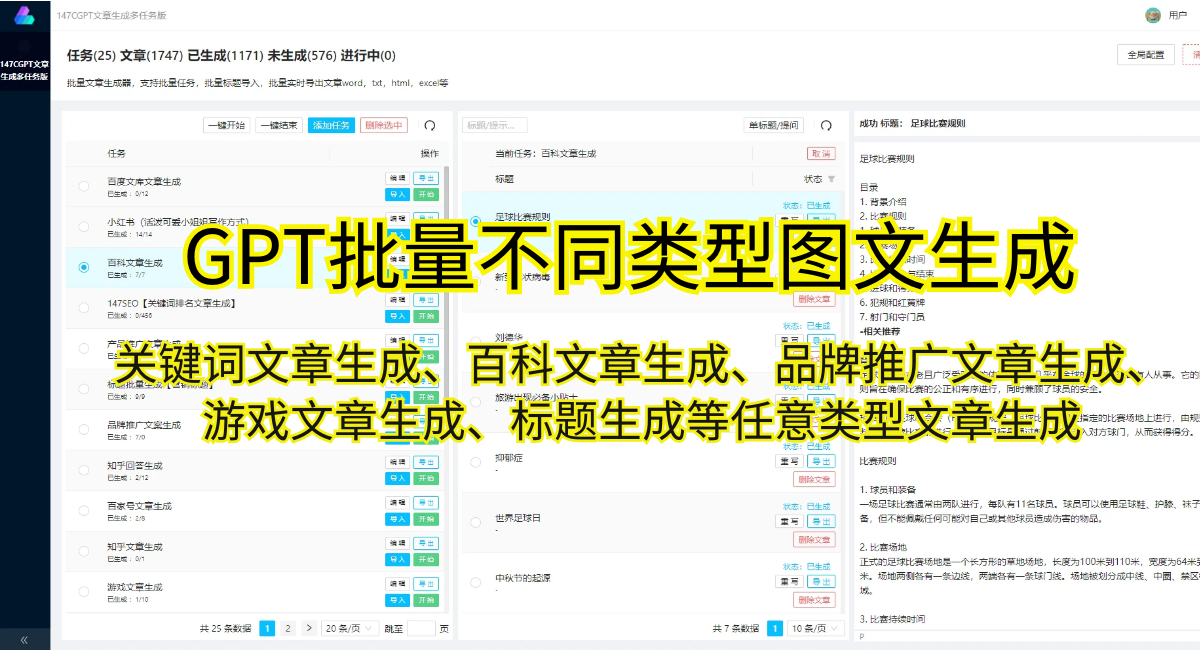
GPT-3Transformer在文本生成方面的表现令人惊叹。它可以根据给定的输入,自动生成连贯、流畅的文章、新闻报道甚至对话。不仅如此,GPT-3Transformer还可以完成翻译、摘要、问题回答等任务。因此,它在自然语言处理领域具有巨大的潜力。
利用GPT-3Transformer进行文本生成的过程非常简单。只需将需要生成的文本内容作为输入,模型就能够自动生成相应的文本。这种方式不仅可以用于写作,还可以应用于广告创意、新闻编辑、智能客服等领域。GPT-3Transformer的高质量文本生成能力为许多领域带来了方便和效率。
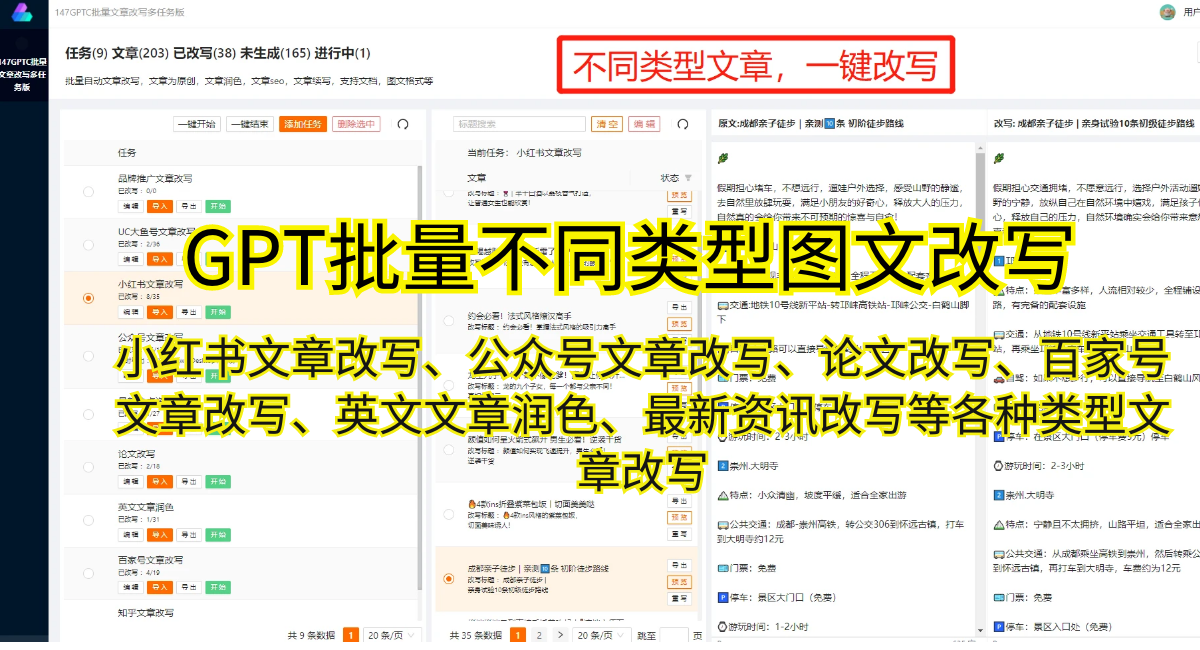
然而,GPT-3Transformer的发展也面临一些挑战。由于大规模的预训练使得参数数量庞大,导致模型的计算负担较重。这意味着在现实应用中,需要强大的计算资源来支持GPT-3Transformer的使用。此外,由于预训练模型的特性,GPT-3Transformer在处理某些特定领域的任务时可能出现一些偏见和错误。
尽管如此,GPT-3Transformer作为人工智能领域的新里程碑,其带来的创新和应用潜力是不可忽视的。它为文本生成、自然语言处理等领域带来了巨大的进步。我们有理由期待,随着技术的发展和改进,GPT-3Transformer将在未来的人工智能应用中发挥更重要的作用。



