
人工智能(ArtificialIntelligence,AI)领域的GPT(GenerativePre-trainedTransformer)模型,以其惊人的能力引起了广泛关注。GPT是由OpenAI团队开发的一种自然语言处理模型,但在实际应用中,它的潜力已经远远超出了文字生成。在最新的GPT-4版本中,我们见证了一个重大突破:GPT可以生成图片!
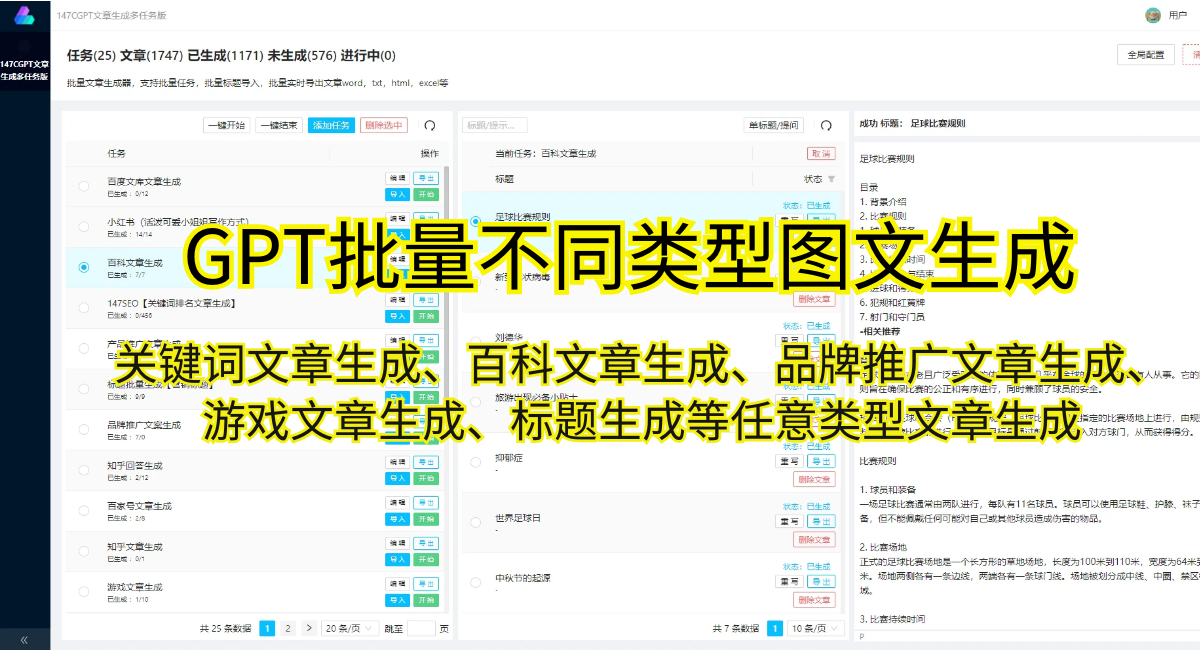
GPT的图片生成能力是如何实现的呢?首先,我们需要了解GPT的工作原理。GPT使用了Transformer模型,这是一种基于自注意力机制的深度学习模型。通过预训练和微调两个阶段的训练,GPT可以从大规模的文本数据中学习到丰富的语义知识。然后,在生成图片的任务上,GPT通过将文本输入转化为像素级别的数据,再通过反向传播进行微调,从而学会生成逼真的图片。
在利用GPT生成图片之前,我们首先需要准备好适当的数据集。一个好的数据集应该包含大量高质量的图片,这样才能让GPT学习到更多的图像特征和风格。当然,数据集的质量也直接关系到最终生成图片的质量,因此选择合适的数据集是非常重要的。
在准备好数据集后,我们可以开始使用GPT生成图片了。首先,我们需要将图片转化为文本描述。这可以通过图片的特征向量或者辅助文本的方式实现。然后,将这些文本描述作为输入,通过GPT进行处理,即可生成对应的图片。当然,生成的图片可能会存在一定的偏差或者失真,这是因为GPT在图像生成方面还有待进一步的提升。
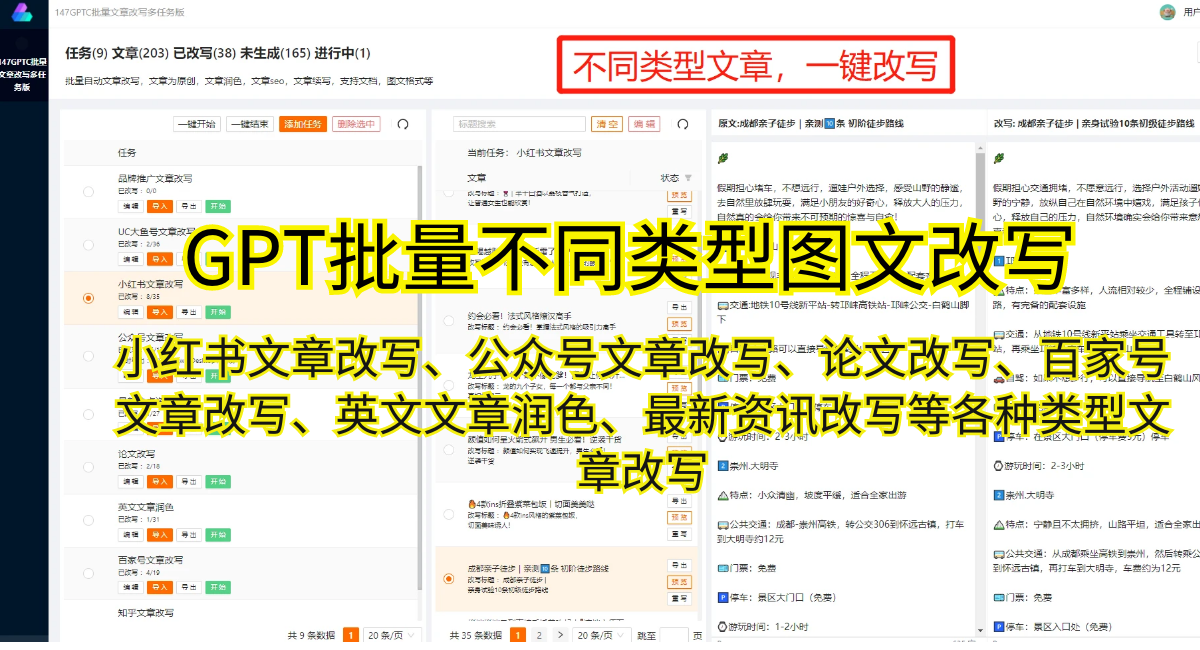
利用GPT生成图片的应用潜力是巨大的。不仅可以用于艺术创作和设计领域,还可以用于辅助创意思维和解决问题。比如,在设计师需要快速生成草图或者原型时,GPT可以根据设计要求生成符合要求的图片。在建筑师需要探索新的建筑风格时,GPT可以生成多种多样的设计方案。在医学领域,GPT可以生成人体器官的立体模型,辅助医生进行手术规划和模拟。
当然,利用GPT生成图片也存在一些挑战和限制。首先,由于GPT是基于文本输入的,因此生成图片的效果受到输入描述的限制。如果输入描述不够准确或不完整,生成的图片可能会出现不符合要求的情况。此外,由于GPT的训练数据是基于大规模的文本数据,因此在生成图片时可能会出现与现实世界不完全吻合的情况。
总之,利用GPT生成图片是一项非常有前景和潜力的研究方向。尽管目前还存在一些挑战和限制,但随着技术的不断发展和改进,我们对于GPT在图片生成领域的应用前景充满期待。相信在不久的将来,GPT将为我们带来更多惊喜!



