
小旋风蜘蛛池不能采集的原因有哪些
小旋风蜘蛛池是一款常用于网络爬虫的工具,它可以自动访问网页并提取有用的数据。然而,有时候我们会发现小旋风蜘蛛池无法采集到想要的数据,这是为什么呢?下面将介绍一些小旋风蜘蛛池不能采集的原因。
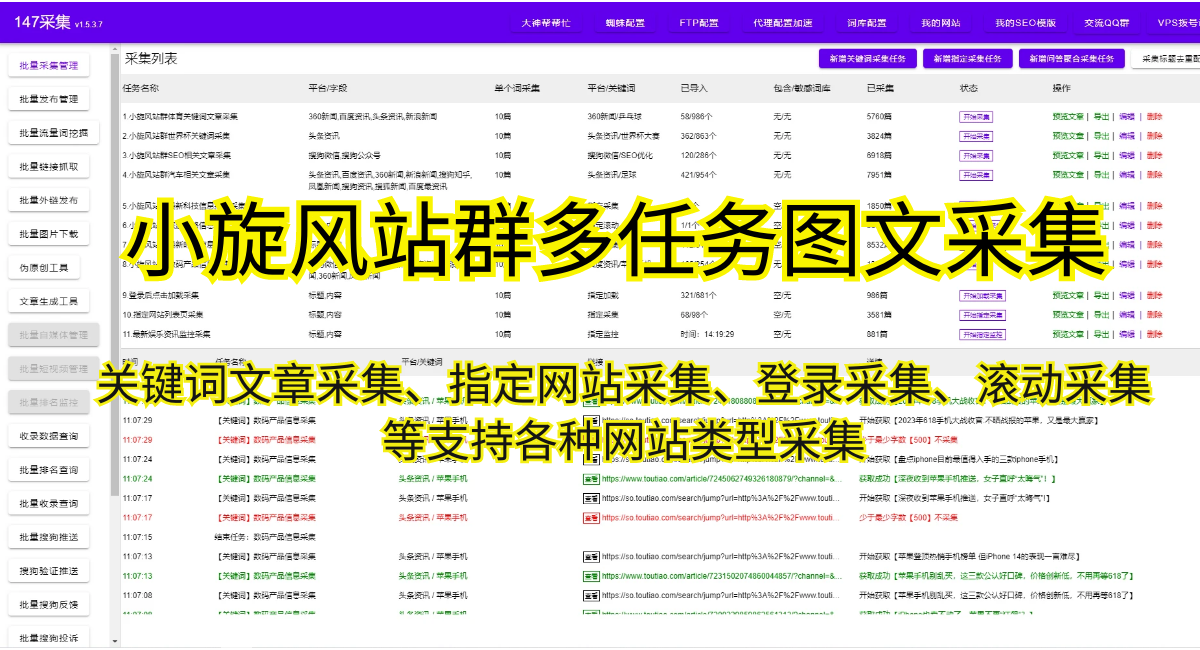 1.网站反爬虫机制:一些网站为了防止被爬虫访问,会设置反爬虫机制,例如验证码、IP封禁等。这些机制会使小旋风蜘蛛池无法正常访问和采集数据。
2.动态网页:小旋风蜘蛛池对于静态网页的采集效果较好,但对于动态网页则可能存在问题。动态网页通过JavaScript等技术来实现内容的更新和加载,而小旋风蜘蛛池默认只会采集首次访问的静态内容,无法获取到后续动态加载的数据。
3.限制访问速度:一些网站为了确保正常用户的访问体验,会对爬虫访问速度进行限制。当小旋风蜘蛛池的访问速度超过了网站的限制时,会被网站识别并拒绝访问。
1.网站反爬虫机制:一些网站为了防止被爬虫访问,会设置反爬虫机制,例如验证码、IP封禁等。这些机制会使小旋风蜘蛛池无法正常访问和采集数据。
2.动态网页:小旋风蜘蛛池对于静态网页的采集效果较好,但对于动态网页则可能存在问题。动态网页通过JavaScript等技术来实现内容的更新和加载,而小旋风蜘蛛池默认只会采集首次访问的静态内容,无法获取到后续动态加载的数据。
3.限制访问速度:一些网站为了确保正常用户的访问体验,会对爬虫访问速度进行限制。当小旋风蜘蛛池的访问速度超过了网站的限制时,会被网站识别并拒绝访问。
 4.网页结构变化:如果网站的网页结构发生了改变,小旋风蜘蛛池可能无法正确解析和提取数据。例如,网页元素的CSS类名或标签名称发生了变化,原先配置好的采集规则就无法正确匹配。
5.网站维护或升级:当网站进行维护或升级时,可能会暂时关闭或改变页面结构,导致小旋风蜘蛛池无法采集数据。
总结起来,小旋风蜘蛛池不能采集的原因包括网站反爬虫机制、动态网页、限制访问速度、网页结构变化以及网站维护或升级。针对这些情况,可以通过调整采集策略、模拟用户行为、修改采集规则等方式来解决问题。
4.网页结构变化:如果网站的网页结构发生了改变,小旋风蜘蛛池可能无法正确解析和提取数据。例如,网页元素的CSS类名或标签名称发生了变化,原先配置好的采集规则就无法正确匹配。
5.网站维护或升级:当网站进行维护或升级时,可能会暂时关闭或改变页面结构,导致小旋风蜘蛛池无法采集数据。
总结起来,小旋风蜘蛛池不能采集的原因包括网站反爬虫机制、动态网页、限制访问速度、网页结构变化以及网站维护或升级。针对这些情况,可以通过调整采集策略、模拟用户行为、修改采集规则等方式来解决问题。
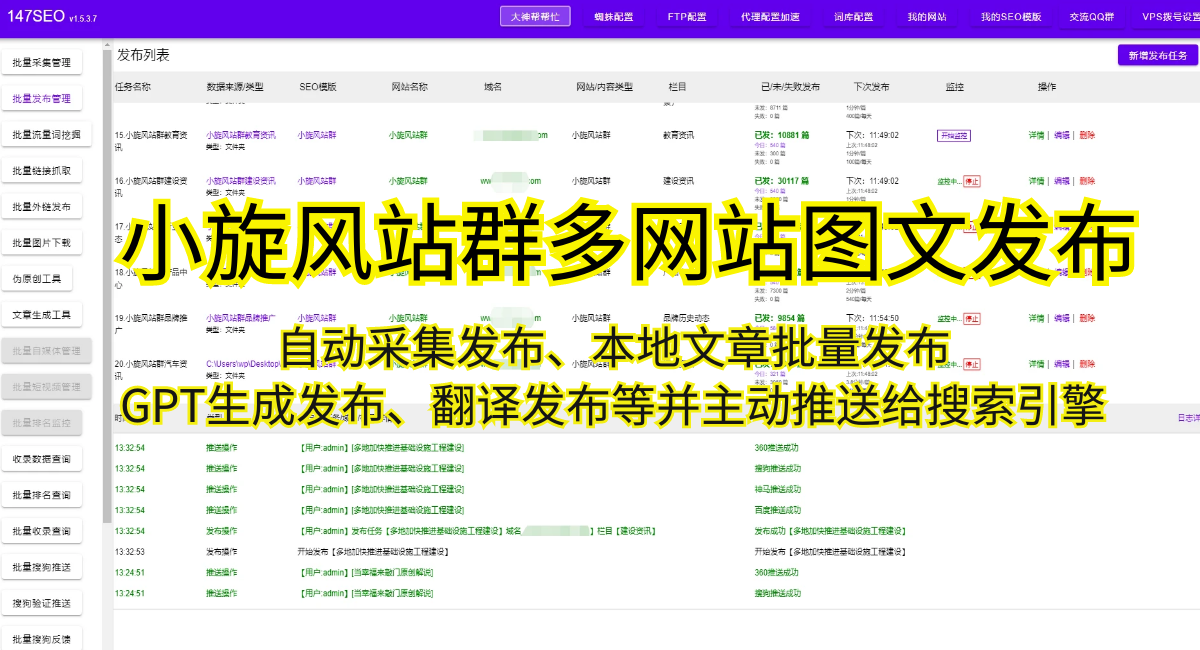
1.网站反爬虫机制:一些网站为了防止被爬虫访问,会设置反爬虫机制,例如验证码、IP封禁等。这些机制会使小旋风蜘蛛池无法正常访问和采集数据。
2.动态网页:小旋风蜘蛛池对于静态网页的采集效果较好,但对于动态网页则可能存在问题。动态网页通过JavaScript等技术来实现内容的更新和加载,而小旋风蜘蛛池默认只会采集首次访问的静态内容,无法获取到后续动态加载的数据。
3.限制访问速度:一些网站为了确保正常用户的访问体验,会对爬虫访问速度进行限制。当小旋风蜘蛛池的访问速度超过了网站的限制时,会被网站识别并拒绝访问。
4.网页结构变化:如果网站的网页结构发生了改变,小旋风蜘蛛池可能无法正确解析和提取数据。例如,网页元素的CSS类名或标签名称发生了变化,原先配置好的采集规则就无法正确匹配。
5.网站维护或升级:当网站进行维护或升级时,可能会暂时关闭或改变页面结构,导致小旋风蜘蛛池无法采集数据。
总结起来,小旋风蜘蛛池不能采集的原因包括网站反爬虫机制、动态网页、限制访问速度、网页结构变化以及网站维护或升级。针对这些情况,可以通过调整采集策略、模拟用户行为、修改采集规则等方式来解决问题。



