
使用爬虫技术对于爱好WordPress网站的用户来说是一项必备的技能。通过爬取WordPress网站,你可以了解最新的网站信息、获取有价值的数据并进行个性化的分析。本文将为你介绍爬取WordPress网站的重要性,以及实现这一目标的方法。
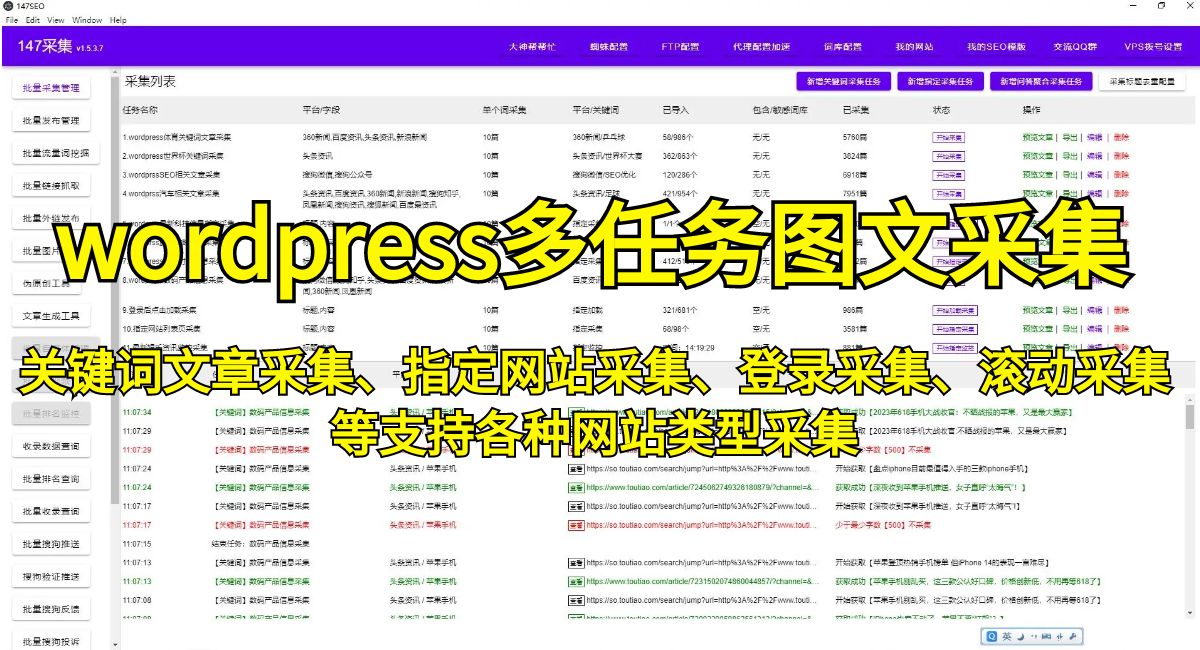
首先,爬取WordPress网站可以帮助你了解网站的最新动态和发展趋势。无论是作为站点管理员还是普通用户,了解网站的变化对于提升用户体验和识别商机都是至关重要的。通过爬取WordPress网站的数据,你可以获取最新发布的文章、评论、用户活动等信息,及时了解网站的更新情况。
其次,爬取WordPress网站可以获取有用的数据。例如,你可能想了解某个网站的关键词、访问量、用户反馈等指标。通过爬取网站的数据,你可以收集这些信息进行进一步的分析。这些数据可以用于改善SEO优化、评估用户满意度、追踪产品发布的成功度等等。
然而,爬取WordPress网站并不是一件简单的任务。首先,你需要确定你想要抓取的网站和数据类型。然后,选择一个合适的爬虫工具,例如Python的Scrapy框架。Scrapy提供了强大的抓取和解析功能,可以帮助你方便地提取所需的数据。
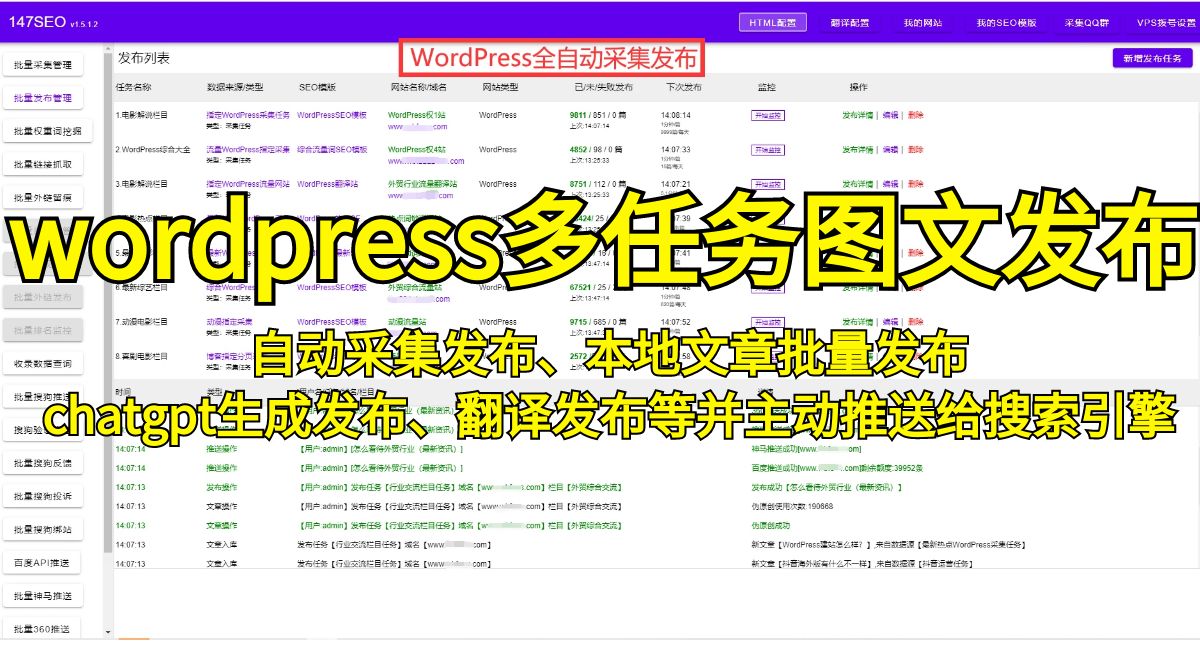
接下来,你需要了解目标网站的页面结构和数据存储方式。使用浏览器开发者工具,你可以查看网站的HTML源代码并确定要爬取的数据所在的位置。对于HTML页面,你可以使用XPath或CSS选择器来定位和提取数据。
在开始爬取之前,要确保你遵守相关规则法规和网站使用协议。某些网站可能禁止爬取他们的数据。在爬取过程中,要注意控制爬取频率,避免对目标网站造成过大的负担。同时,使用合适的User-Agent和IP代理,以减少被目标网站封禁的风险。
最后,完成爬取后,你可以对获取的数据进行处理和分析。将数据存储到数据库或导出为CSV文件,然后使用数据分析工具进行进一步的处理。你可以使用Python的pandas库来处理和分析数据,或使用其他工具和语言,根据你的需求进行选择。

总之,了解如何爬取WordPress网站是一个有益的技能。通过获取最新的网站信息和有用的数据,你可以提升用户体验,优化网站运营,并识别商机。希望本文对你了解爬取WordPress网站的重要性和方法有所帮助。
147SEO » 爬取WordPress:了解最新网站信息的必备技巧



