
Discuz自动采集原理
Discuz是一种流行的开源论坛程序,广泛应用于各种网站。它提供了丰富的插件和主题,能够满足用户不同的需求。其中,自动采集是Discuz的一个重要功能,可以帮助用户快速获取互联网上的信息。
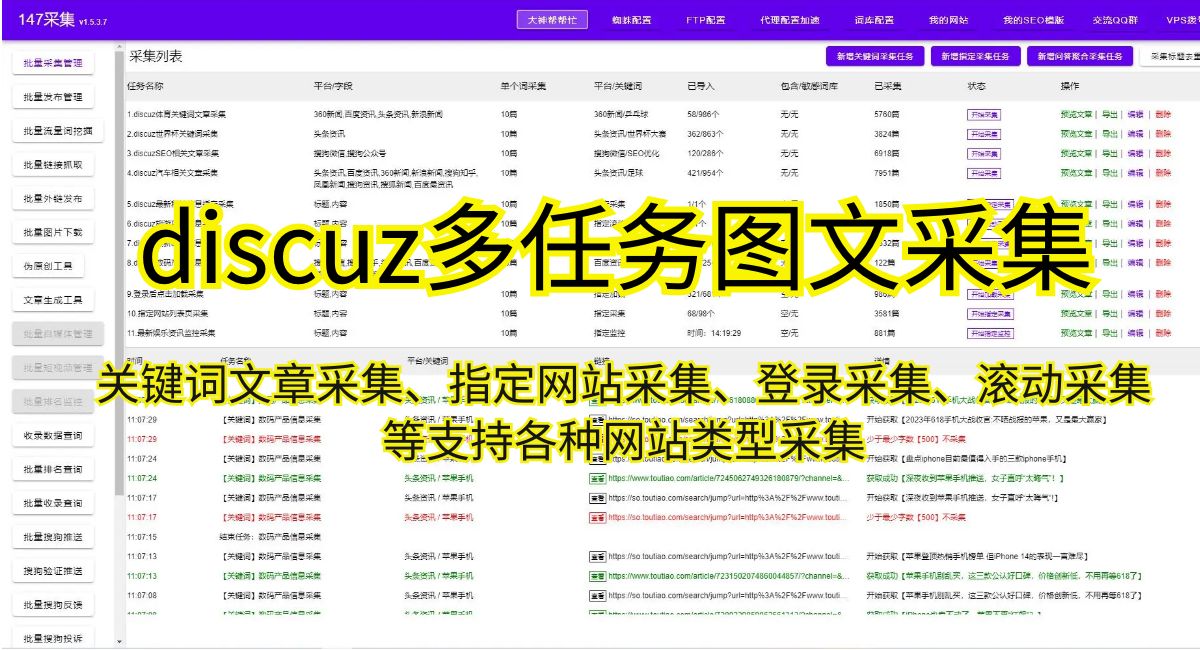 自动采集的原理主要分为三个步骤:搜索、抓取和解析。首先,Discuz通过设定关键词进行搜索,获取相关的信息。然后,利用网络爬虫技术抓取网页内容,包括文字、图片和链接等。最后,通过解析抓取到的内容,提取出关键信息,并进行数据处理与存储。
在搜索阶段,Discuz会根据用户设定的关键词,向搜索引擎发起请求,获取搜索结果。搜索引擎会根据算法和相关性对搜索结果进行排序,并返回给Discuz。用户可以设定搜索引擎、搜索范围和排序规则等参数,以获得满意的搜索结果。
抓取阶段是自动采集的核心步骤。Discuz会根据搜索结果中的URL,利用网络爬虫技术来获取网页内容。网络爬虫是一种模拟浏览器行为的程序,可以自动访问网页并获取其中的信息。Discuz利用网络爬虫技术,访问网页的过程中会解析HTML代码,提取出需要的信息,如标题、正文内容、图片地址等。这些信息会被存储到数据库中,为后续的数据处理做准备。
自动采集的原理主要分为三个步骤:搜索、抓取和解析。首先,Discuz通过设定关键词进行搜索,获取相关的信息。然后,利用网络爬虫技术抓取网页内容,包括文字、图片和链接等。最后,通过解析抓取到的内容,提取出关键信息,并进行数据处理与存储。
在搜索阶段,Discuz会根据用户设定的关键词,向搜索引擎发起请求,获取搜索结果。搜索引擎会根据算法和相关性对搜索结果进行排序,并返回给Discuz。用户可以设定搜索引擎、搜索范围和排序规则等参数,以获得满意的搜索结果。
抓取阶段是自动采集的核心步骤。Discuz会根据搜索结果中的URL,利用网络爬虫技术来获取网页内容。网络爬虫是一种模拟浏览器行为的程序,可以自动访问网页并获取其中的信息。Discuz利用网络爬虫技术,访问网页的过程中会解析HTML代码,提取出需要的信息,如标题、正文内容、图片地址等。这些信息会被存储到数据库中,为后续的数据处理做准备。
 解析阶段是对抓取到的内容进行处理和解析的过程。Discuz会根据设定的规则,对抓取到的信息进行解析,并提取出关键信息。例如,可以通过正则表达式匹配网页中的某个固定格式的信息,或者使用XPath语法来提取XML或HTML中的特定元素。解析后的数据会根据需求进行存储,可以是数据库、文件或者其他形式的存储方式。
Discuz的自动采集功能在实际应用中具有广泛的场景。例如,可以用于快速搭建新闻聚合网站,自动采集各大新闻网站的头条新闻;也可以用于论坛板块的自动更新,定时采集最新的话题内容;此外,还可以用于商品比价网站,自动采集不同电商平台的商品信息。通过自动采集,使论坛更加活跃,网站内容更加丰富,用户体验得到提升。
综上所述,Discuz的自动采集原理基于搜索、抓取和解析三个步骤,能够快速获取互联网上的信息。它在论坛搭建、新闻聚合、商品比价等场景中具有重要的应用价值。希望本文对Discuz用户了解自动采集原理有所帮助。
解析阶段是对抓取到的内容进行处理和解析的过程。Discuz会根据设定的规则,对抓取到的信息进行解析,并提取出关键信息。例如,可以通过正则表达式匹配网页中的某个固定格式的信息,或者使用XPath语法来提取XML或HTML中的特定元素。解析后的数据会根据需求进行存储,可以是数据库、文件或者其他形式的存储方式。
Discuz的自动采集功能在实际应用中具有广泛的场景。例如,可以用于快速搭建新闻聚合网站,自动采集各大新闻网站的头条新闻;也可以用于论坛板块的自动更新,定时采集最新的话题内容;此外,还可以用于商品比价网站,自动采集不同电商平台的商品信息。通过自动采集,使论坛更加活跃,网站内容更加丰富,用户体验得到提升。
综上所述,Discuz的自动采集原理基于搜索、抓取和解析三个步骤,能够快速获取互联网上的信息。它在论坛搭建、新闻聚合、商品比价等场景中具有重要的应用价值。希望本文对Discuz用户了解自动采集原理有所帮助。

自动采集的原理主要分为三个步骤:搜索、抓取和解析。首先,Discuz通过设定关键词进行搜索,获取相关的信息。然后,利用网络爬虫技术抓取网页内容,包括文字、图片和链接等。最后,通过解析抓取到的内容,提取出关键信息,并进行数据处理与存储。
在搜索阶段,Discuz会根据用户设定的关键词,向搜索引擎发起请求,获取搜索结果。搜索引擎会根据算法和相关性对搜索结果进行排序,并返回给Discuz。用户可以设定搜索引擎、搜索范围和排序规则等参数,以获得满意的搜索结果。
抓取阶段是自动采集的核心步骤。Discuz会根据搜索结果中的URL,利用网络爬虫技术来获取网页内容。网络爬虫是一种模拟浏览器行为的程序,可以自动访问网页并获取其中的信息。Discuz利用网络爬虫技术,访问网页的过程中会解析HTML代码,提取出需要的信息,如标题、正文内容、图片地址等。这些信息会被存储到数据库中,为后续的数据处理做准备。
解析阶段是对抓取到的内容进行处理和解析的过程。Discuz会根据设定的规则,对抓取到的信息进行解析,并提取出关键信息。例如,可以通过正则表达式匹配网页中的某个固定格式的信息,或者使用XPath语法来提取XML或HTML中的特定元素。解析后的数据会根据需求进行存储,可以是数据库、文件或者其他形式的存储方式。
Discuz的自动采集功能在实际应用中具有广泛的场景。例如,可以用于快速搭建新闻聚合网站,自动采集各大新闻网站的头条新闻;也可以用于论坛板块的自动更新,定时采集最新的话题内容;此外,还可以用于商品比价网站,自动采集不同电商平台的商品信息。通过自动采集,使论坛更加活跃,网站内容更加丰富,用户体验得到提升。
综上所述,Discuz的自动采集原理基于搜索、抓取和解析三个步骤,能够快速获取互联网上的信息。它在论坛搭建、新闻聚合、商品比价等场景中具有重要的应用价值。希望本文对Discuz用户了解自动采集原理有所帮助。



