
解决dede采集不了网站的方法

在进行网站采集的过程中,用户有时会遇到dede采集不了网站的问题。这给用户的工作带来了困扰,本文将为您介绍一些解决dede采集不了网站的方法,希望能帮助到您。
方法一:检查网站robots.txt文件
dede采集不了网站的一个常见原因是robots.txt文件中的限制。该文件用来向搜索引擎指示网站的爬虫如何抓取网页。有些网站会在robots.txt文件中设置禁止爬取的规则,从而导致dede无法采集。用户可以通过访问网站的robots.txt文件来检查是否有相关的限制。如果存在限制,则可以尝试联系网站管理员解决或调整dede的爬取策略。
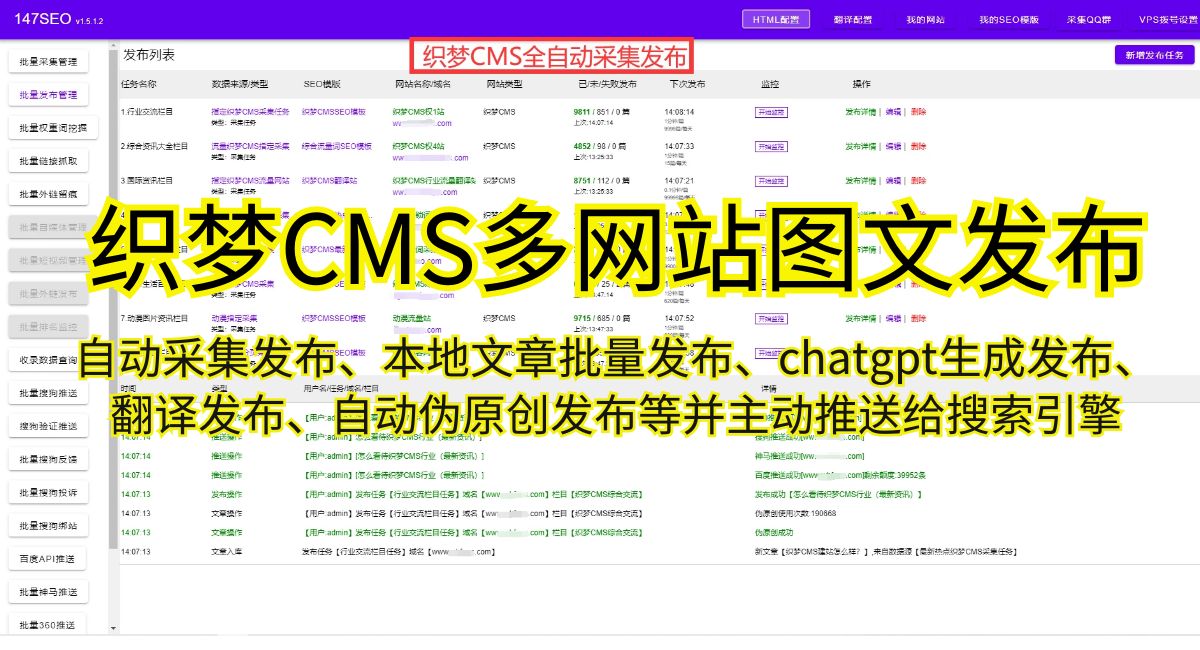
方法二:检查采集规则配置
dede作为一款专业的采集工具,需要用户正确设置采集规则。如未正确配置,就会导致dede无法采集网站。用户可以检查自己的采集规则是否正确,包括采集的URL、关键词、正则表达式等。根据网站不同,可能需要灵活调整采集规则。
方法三:考虑网站反爬虫策略

有些网站为了防止被爬虫抓取信息,会通过反爬虫策略来限制dede等采集工具的访问。用户可以尝试模拟正常用户的访问行为来规避这些反爬虫策略。例如,可以设置合理的访问频率、使用代理IP、更换User-Agent等方式来规避网站的反爬虫策略,从而使dede能够顺利采集。
方法四:寻求帮助和反馈
如果用户一直无法解决dede采集不了网站的问题,可以考虑寻求专业人士的帮助。用户可以加入相关的技术论坛、社群或咨询客服,向他们咨询问题并寻求解决方案。同时,用户也可以将自己遇到的问题反馈给dede官方团队,以便他们能够在后续的版本更新中进行改进和优化。
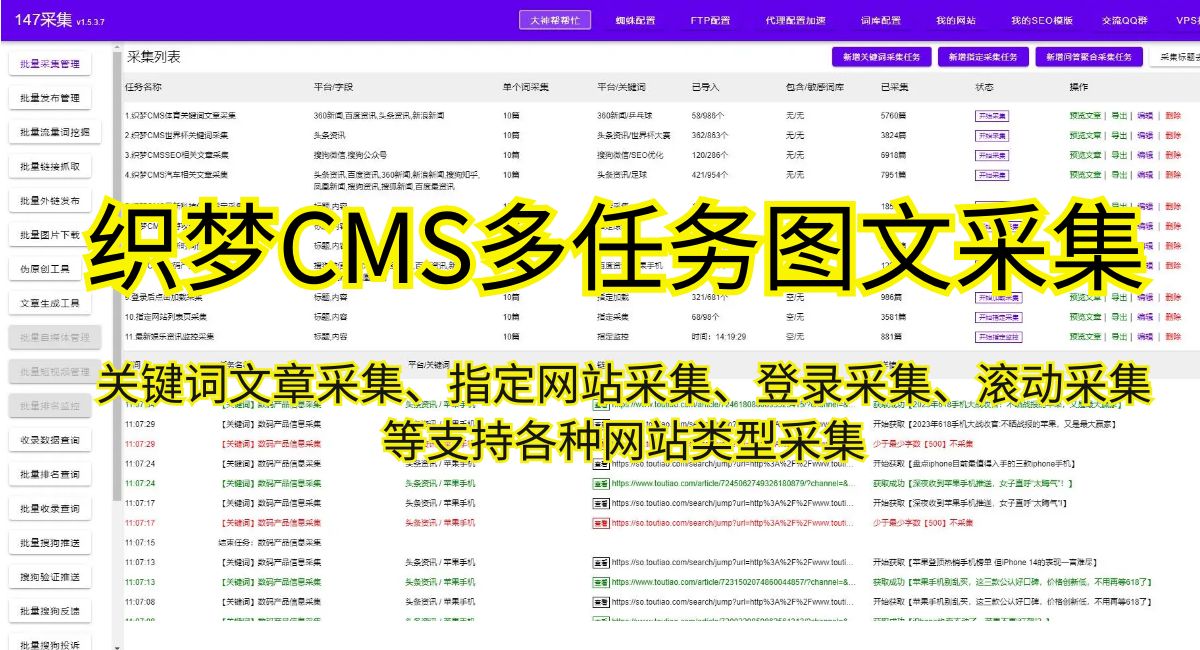
总结
本文介绍了解决dede采集不了网站的一些方法,希望能够帮助到用户解决问题。在实际操作中,用户要充分了解网站的限制和采集规则,同时也要留意网站的反爬虫策略。如有需要,建议寻求专业人士的帮助,以获得更准确的指导和解决方案。希望dede用户能够顺利进行网站采集工作,提高工作效率。



