
一、引言

网站静态资源源码采集技术的应用范围越来越广泛,无论是个人还是企业,在项目开发、数据分析等方面都会涉及到采集网站的静态资源,因此掌握采集技术和工具变得尤为重要。
二、采集方法与工具
1. 网络爬虫技术

网络爬虫是一种自动化采集网站信息的技术,利用这种技术,可以获取到网站的HTML源码,从而提取出所需要的静态资源信息。常用的网络爬虫工具包括爬虫框架Scrapy、Python库Beautiful Soup等。
2. HTTP请求
通过向目标网站发送HTTP请求,可以获取网站的源码,进而提取出目标静态资源。常用的HTTP请求工具有curl、Postman等。通过学习HTTP请求的使用方法,可以实现简单快捷地采集网站静态资源。
3. 第三方API接口
许多网站提供了开放的API接口,利用它们可以直接获取到所需的静态资源数据。通过调用相关API接口,可以大大简化采集流程,提高效率。例如,百度、Google等搜索引擎都提供了开放的API接口。
三、源码采集的注意事项
在进行网站静态资源源码采集时,有些事项需要注意,以确保采集的有效性和合法性:
1.合法性:在采集网站资源时,需确保自己的行为合法,并不侵犯目标网站的合法权益。在遵循相关规则法规的前提下,进行资源的采集。
2.隐私保护:在进行网站静态资源源码采集时,要注意不要采集涉及个人隐私的信息,以免引发规则问题。
3.反爬虫机制:一些网站会采取反爬虫机制,限制爬虫程序的访问,需要针对具体网站的反爬虫策略,进行相应的应对措施。
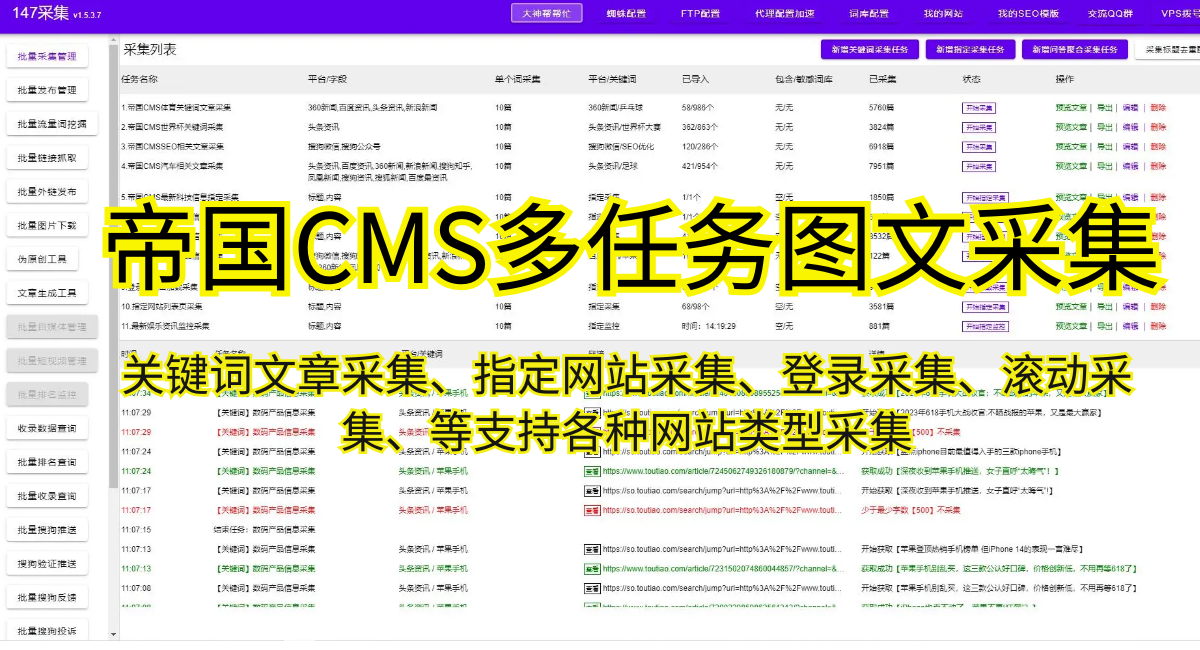
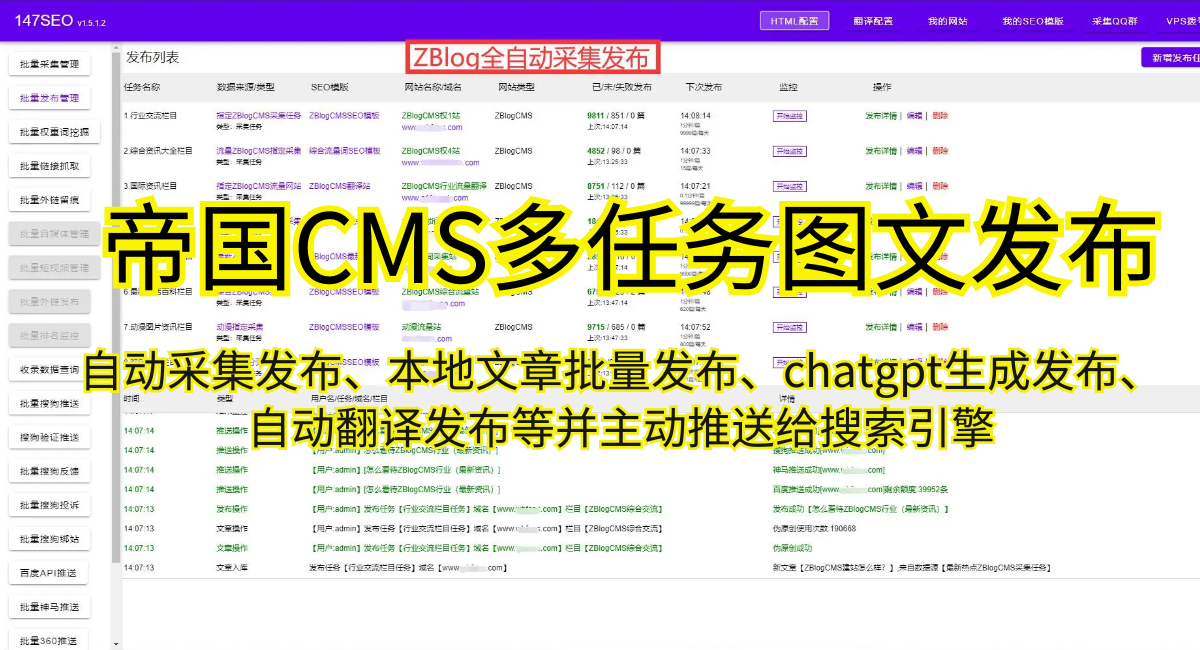
四、采集案例与实践
本文将通过介绍两个具体的采集案例,为读者展示如何利用不同的技术和工具,高效地采集网站静态资源。通过学习这些案例,读者可以更好地理解和掌握采集技巧和方法。
五、总结
网站静态资源源码采集是一项重要的技术,掌握这项技术对个人和企业都非常有价值。通过本文的介绍,相信读者们对网站静态资源采集有了更深入的了解,并可以利用相关技术和工具提升采集效率,满足个人和企业的需求。希望本文对您有所帮助。
147SEO » 助力网站静态资源采集,提升效率



