
GPT的缺点
1. 训练数据依赖性:GPT的性能高度依赖于大规模的训练数据,当数据规模较小或者数据质量较低时,GPT的生成结果可能不够准确或者连贯性不强。

2. 噪声敏感性:GPT在遇到输入中的噪声或错误时,往往会无法正确处理,导致生成的文本失去意义或者产生不准确的输出。
3. 模型可解释性:GPT是一种黑盒模型,它背后的决策过程很难被解释和理解。一些生成的结果可能缺乏合理性和可解释性,甚至存在一定的偏见。
4. 上下文依赖性:GPT生成文本时,只考虑了局部的上下文信息,并没有有效利用整个文档或者背景知识。这可能导致生成的文本与整体语境相悖或不连贯。
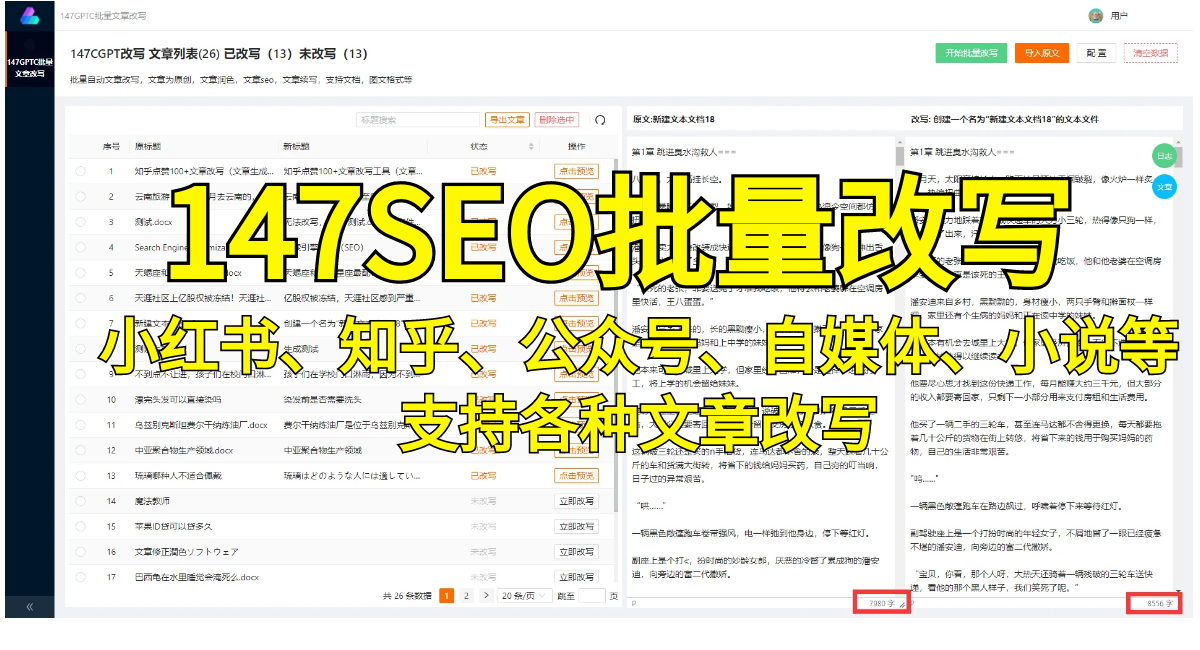
5. 输出一致性:GPT在生成长文本时,由于其自由度较高,存在输出的不一致性问题。同一个输入可能会生成多个不同但语义上合理的输出,这可能造成不稳定的结果。
6. 意义理解能力:GPT的语义理解能力相对较弱,无法真正理解输入文本的意图和上下文,往往只是简单地根据训练数据进行模式匹配和输出。
7. 长期依赖问题:GPT在处理长时序问题时,由于缺乏明确的记忆机制,可能出现信息遗忘或者失序的情况,导致生成结果的错误或者不一致。
8. 输出控制困难:GPT在生成文本时难以控制输出的具体风格、情感和内容,因此很难满足用户对于特定需求的定制化要求。
9. 数据隐私问题:GPT的训练需要大量的公开数据,而其中可能包含敏感信息,如用户隐私、商业机密等,这可能导致数据泄漏和隐私问题。
10. 环境依赖:GPT的性能和效果受到部署环境的影响较大,不同硬件设备和软件平台可能会导致性能差异,限制了其广泛应用的可能性。
虽然GPT在自然语言处理领域取得了令人瞩目的成就,但我们也需要正视其缺点和局限性,进一步深化研究和探索,提升其性能和可靠性,以更好地应用于实际场景中。



