
ygbook自动采集发布无需编写规则代码
ygbook采集规则,ygbook采集规则难吗?做过小说站的人应该都知道,编写采集规则都是需要一定的编程能力以及html代码能力的。写好的部分采集规则也会失效的,今天给大家分享一款免费自动采集更新工具:全自动采集自动更新,只要初期设置好seo模板、输入目标站以及目标模板等,后续什么都不用管,完全解放了你的个人时间的同时,又让你有一个潜力无穷的小说站.
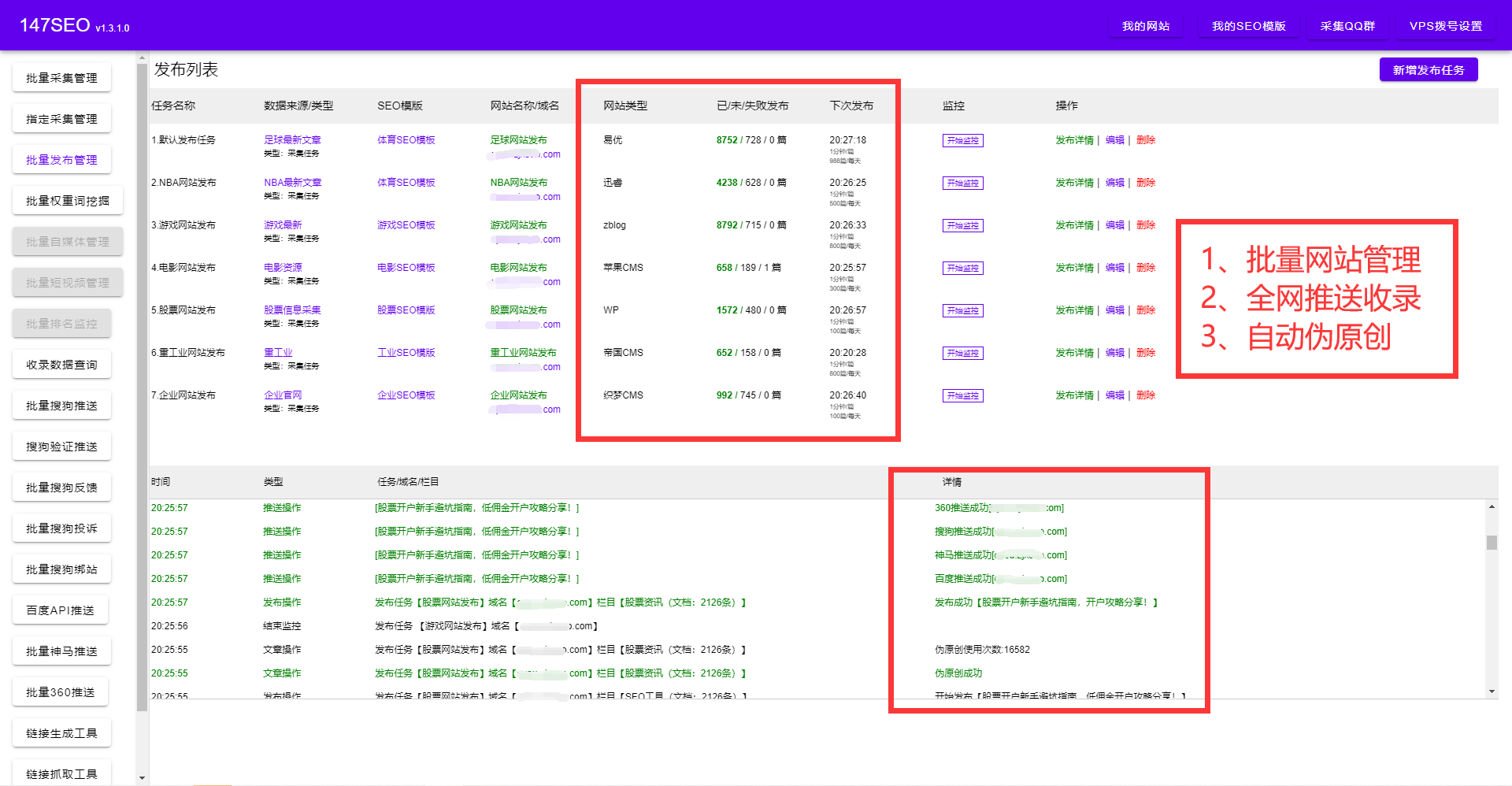
由于 YGbook采集规则奇缺的问题。这里使用软件采集了26条的YGBook采集规则供分享给大家,大家可根据各自的情况筛选出5-6条权重高、更新快、质量好的采集源,ygbook采集即可保证每天能自动采集、更新200-500+的小说。
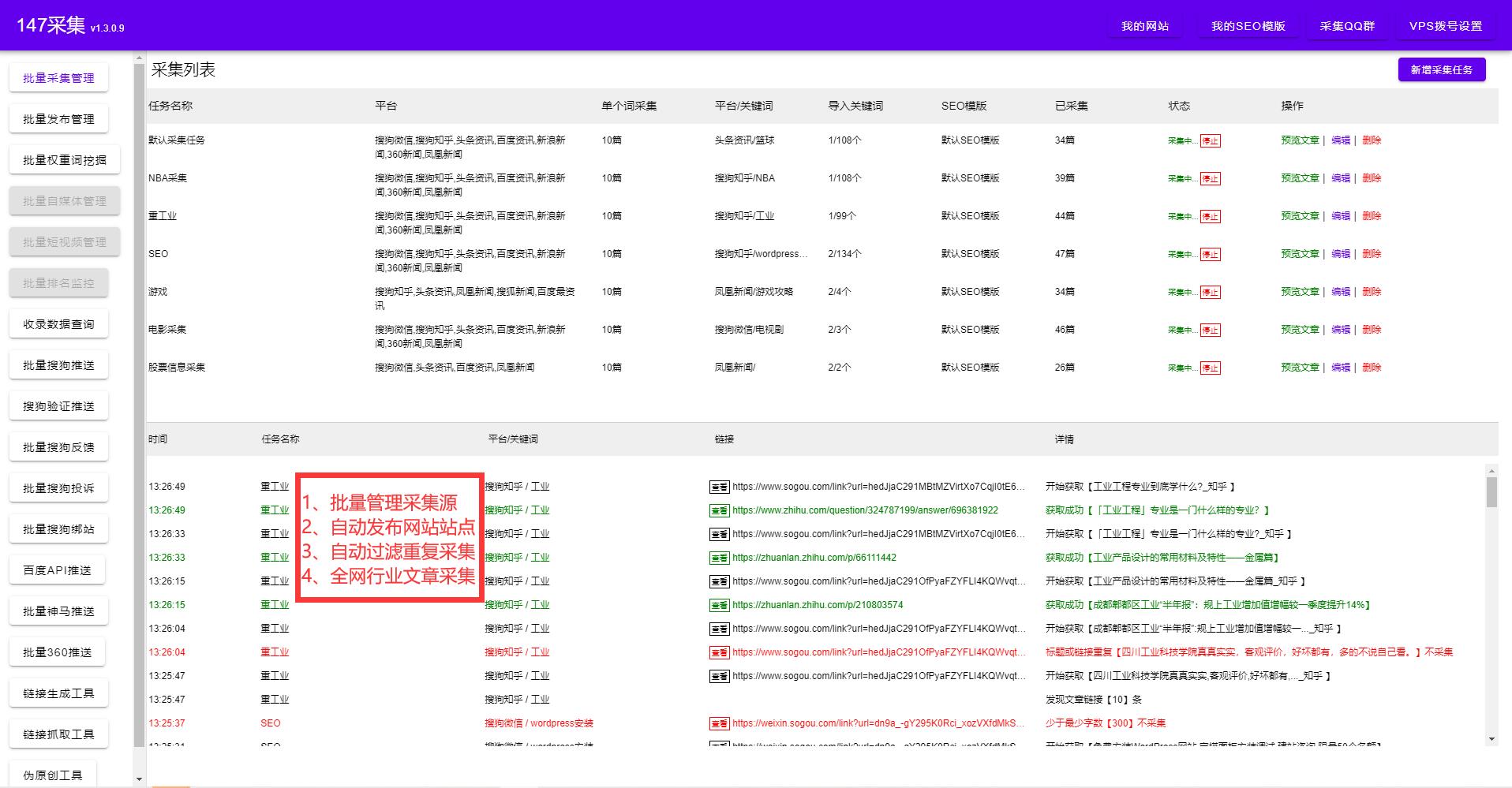
YGBOOK基于ThinkPHP+MYSQL开发,可以在大部分常见的服务器上运行。
环境要求:PHP5.4以上,有伪静态功能。推荐配置php7.2mysql5.6+
主机要求:IIS/APACHE/NGINX均可,虚拟主机/VPS/服务器/云服务器均可。
YGBOOK优点:
1.不保存任何数据,小说以类似软链接的形式存在。没有版权纷争。
2.因为是软链接,所以对硬盘空间需求极小,成本低。
3.后台预置广告位, 添加广告代码极其简单,想赚烟钱的老哥可以看一下。
4.可以挂机自动采集,简单省事。
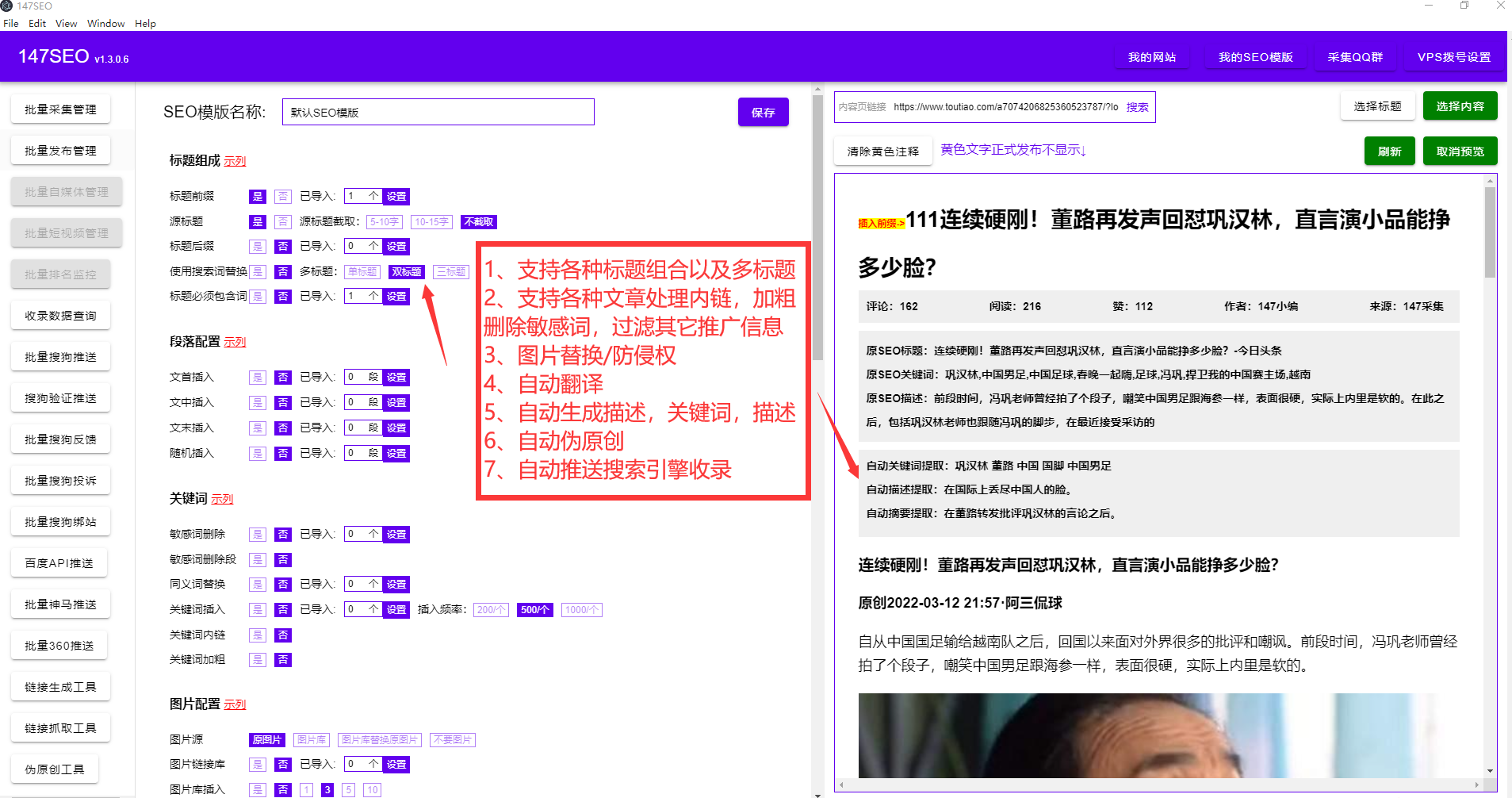
YGBOOK基于ThinkPHP+MYSQL开发,可以在大部分常见的服务器上运行。
环境要求:PHP5.4以上,有伪静态功能。推荐配置php7.2mysql5.6+
主机要求:IIS/APACHE/NGINX均可,虚拟主机/VPS/服务器/云服务器均可。推荐使用linux系统,apache inx均可
硬件要求:CPU/内存/硬盘/宽带大小无要求,但配置越高,采集效率会更好!
其他要求:如采集目标站服务器在国内,而你的主机在国外,会产生采集效率低的问题。应尽量选择同区域的网站进行采集,美国服务器宜选择机房设在美国的小说站,国内服务器则选择国内站点,以尽可能提升网站速度。
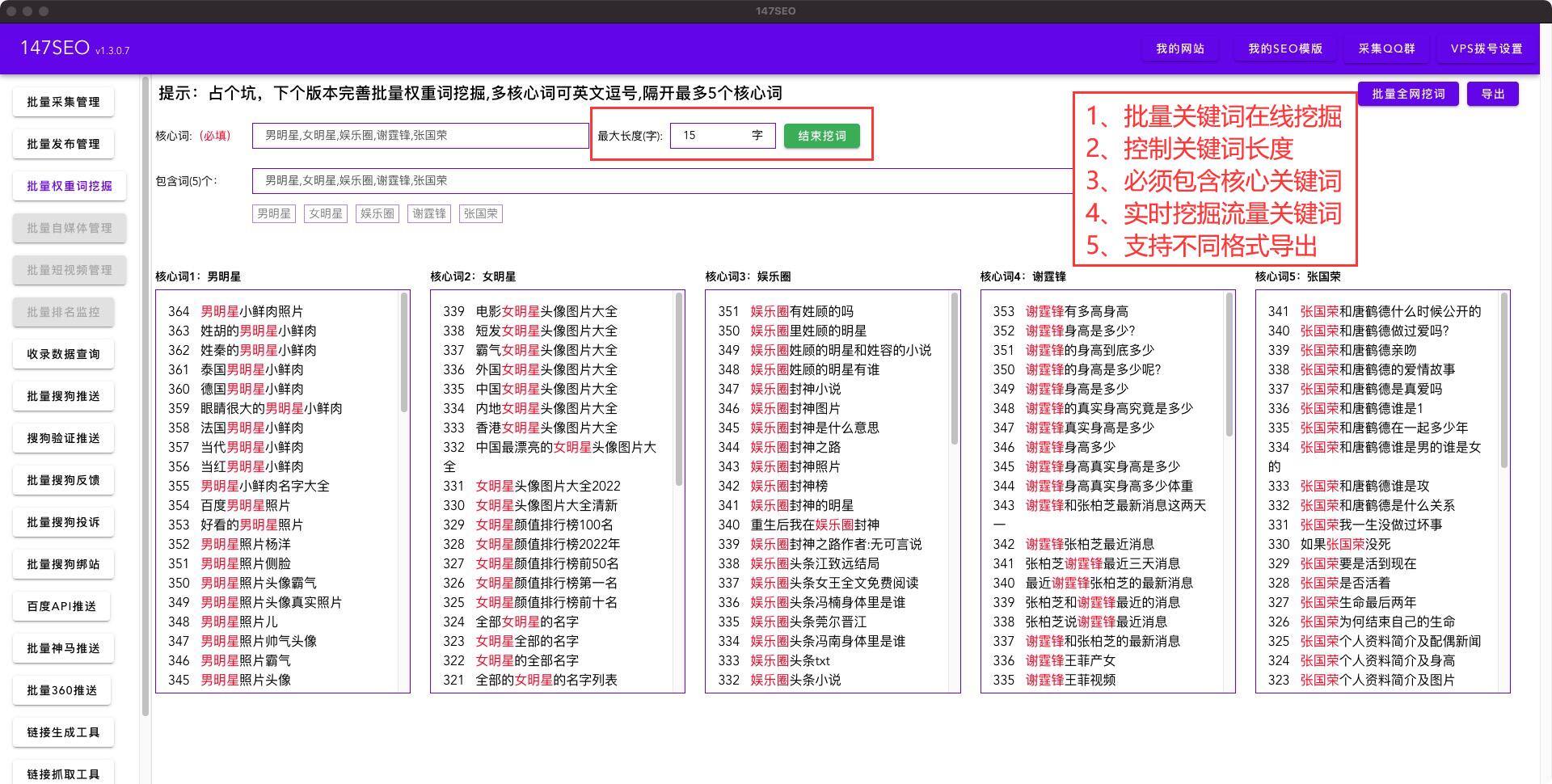
ygbook采集[cate]对应情况取源站顶部分类要中文的,比如玄幻小说 修真小说到最后恐怖小说依次对应本站,如果分类出入太大的,可自行在后台建分类再对应,最大页码为1.
规则列表页码这个很好理解,比如1|1|200的意思就是从第一页开始到200页,每次增加1页。
ygbook采集无缩略图标志一般为nocover,如果不是你看下源站是什么自行改即可。
列表页:链接CSS选择器和列表页:标题CSS选择器
这个怎么选,我们打开首页看到最近更新列表,选取大区域:#newscontent 再去一个区域 .l 区别于下方最新入库的的.r ,最后我们再去我们真正要去的区域.s2 a结束,组合就是#newscontent .l .s2 a,很多人喜欢这个样子写,ygbook采集就跟提示差不多 #newscontent li a 有些站是可以的,但是要分清楚。
文章页的各个选项,如果是有360结构化的站那么以下是通用的
标题CSS选择器 :meta[property=og:novel:book_name]|content
作者CSS选择器 meta[property=og:novel:author]|content
缩略图CSS选择器 meta[property=og:image]|content
内容CSS选择器一般为#intro
因为源站简介源码一般为,如果不是 自行修改intro即可,ygbook采集完结标志不用多说了。
章节目录页:区域CSS选择器一般为:#list
自行查看源码就知道了
章节目录页:采集规则也看源码如biquge.com为,那么写成即可。
如果有这样子的: 你写成,把不要的用[string]代替掉即可。
最后章节内容页:内容CSS选择器一般为#content 为什么上面也提到过 ygbook采集自行查看源码就明白了。
通用替换 {filter replace='hostloc'}笔趣阁{/filter} 如果不替换只删除的话删除hostloc即可。
多栏目以:为例 这就不用解释那么多了,累。。。
规则列表页面为: [cate]/.html[cate]

ygbook采集对应情况以网址为准如:sort1 sort2 sort3 对应玄幻 修真 都市 页码自己填
列表页:链接CSS选择器列表页:标题CSS选择器为#newscontent .l .s2 a
ygbook采集此站没有360结构化 所以文章页:标题CSS选择器为 h1 一般都是这个
文章页:作者CSS选择器为.infotitle i 并在文章页:源码预过滤规则填入{filter replace=''}作者:{/filter},多栏目无需写分类。
ygbook采集文章页:内容CSS选择器为 .intro 这有个问题我没解决 .introygbook采集虽然可获取 但是获取的值太多 后面的东西是不想要的 提示也说了可用|分割过滤 但没搞懂。
文章页:缩略图CSS选择器为#fmimg img|src fmimg为值 img|src为图片


