
如今,互联网上的信息日益丰富,数据爬取成为了许多行业所需的重要工具。然而,许多网站引入了各种反爬虫机制,限制了非授权用户对其数据的访问。本文将介绍一些应对网站反爬虫的策略,以确保爬取数据的效率和隐蔽性。
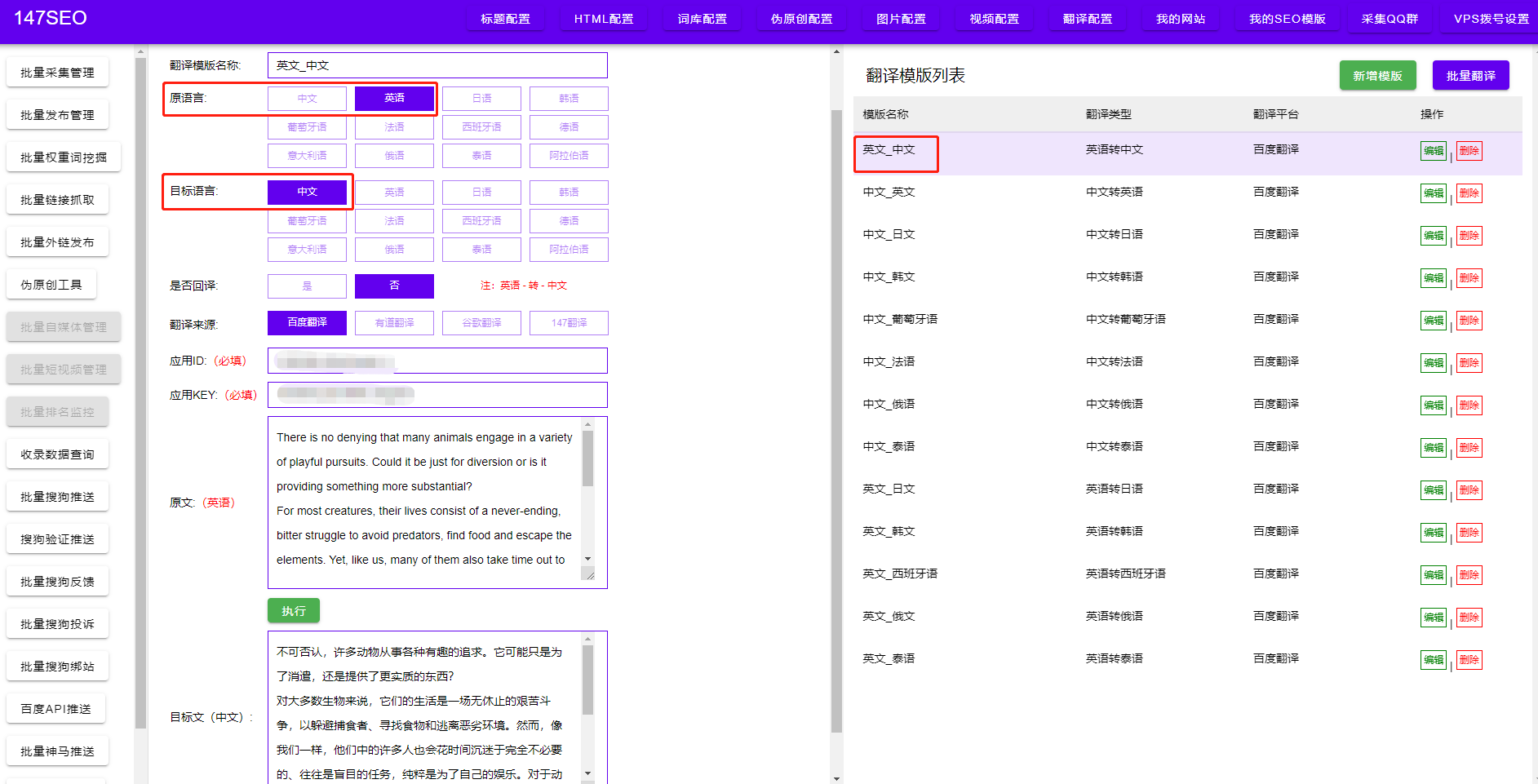
首先,可以通过模拟人类访问行为来绕过网站的反爬虫机制。例如,可以使用随机的用户代理、请求头,模拟用户在网站上的正常操作,比如点击链接、滚动页面等。这样可以降低爬虫被检测到的概率,提高爬取数据的成功率。
其次,使用IP代理可以有效地应对网站对于同一IP频繁请求的限制。通过使用不同的IP地址,可以隐藏真实的爬虫来源,防止被网站识别并限制访问。此外,还可以通过旋转IP代理的使用,避免被封禁或限速。
另外,针对一些反爬虫机制比较高级的网站,可以通过解析JavaScript代码来获取数据。许多网站会使用JavaScript动态加载数据或对数据进行加密,这给爬虫带来了一定的挑战。通过分析网页源码中的JavaScript代码,可以找到数据的SEO方法或者直接模拟JavaScript执行环境来动态加载数据。
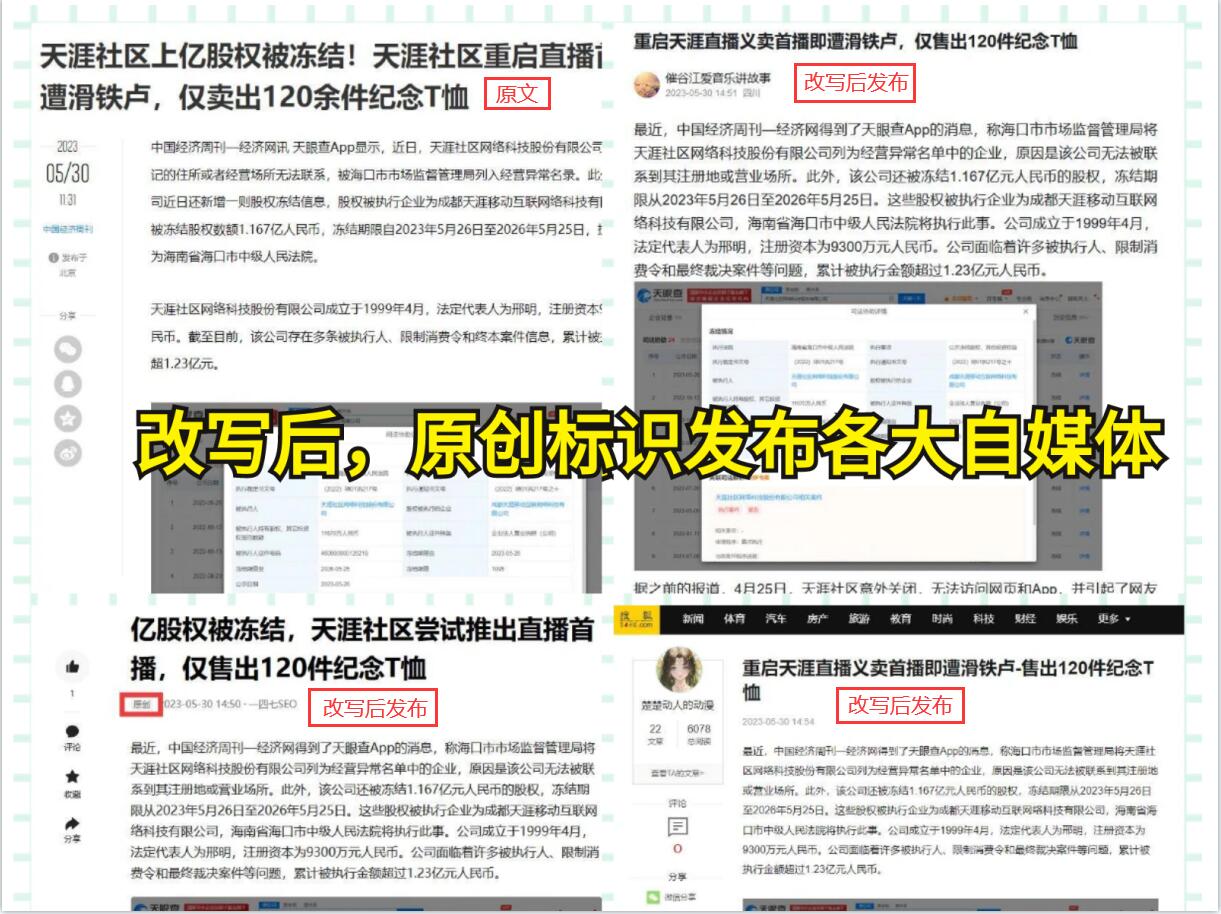
此外,对于一些需要登录权限才能获取数据的网站,可以通过自动化测试工具模拟登录操作,以获取需要的数据。这种方法可以绕过网站的登录验证,获取到更多的数据。
总之,面对网站反爬虫的挑战,我们可以采取多种策略来提高数据爬取的效率和隐蔽性。通过模拟人类访问行为、使用IP代理、解析JavaScript代码和模拟登录操作等技巧,我们可以更好地应对网站反爬虫机制,确保爬取数据的成功率和质量。同时,我们也要注意遵守相关法律法规,避免非法使用爬虫技术,保护网络安全和个人隐私。
转载请说明出处
147SEO » 轻松应对网站反爬虫,确保爬取数据效率与隐蔽性
147SEO » 轻松应对网站反爬虫,确保爬取数据效率与隐蔽性




