
静态网站爬取数据是一种常见的数据采集技术,通过获取网站上的信息并将其保存为结构化的数据,从而让手中的信息在指尖舞动。那么,为什么需要爬取静态网站数据?如何进行静态网站数据爬取呢?
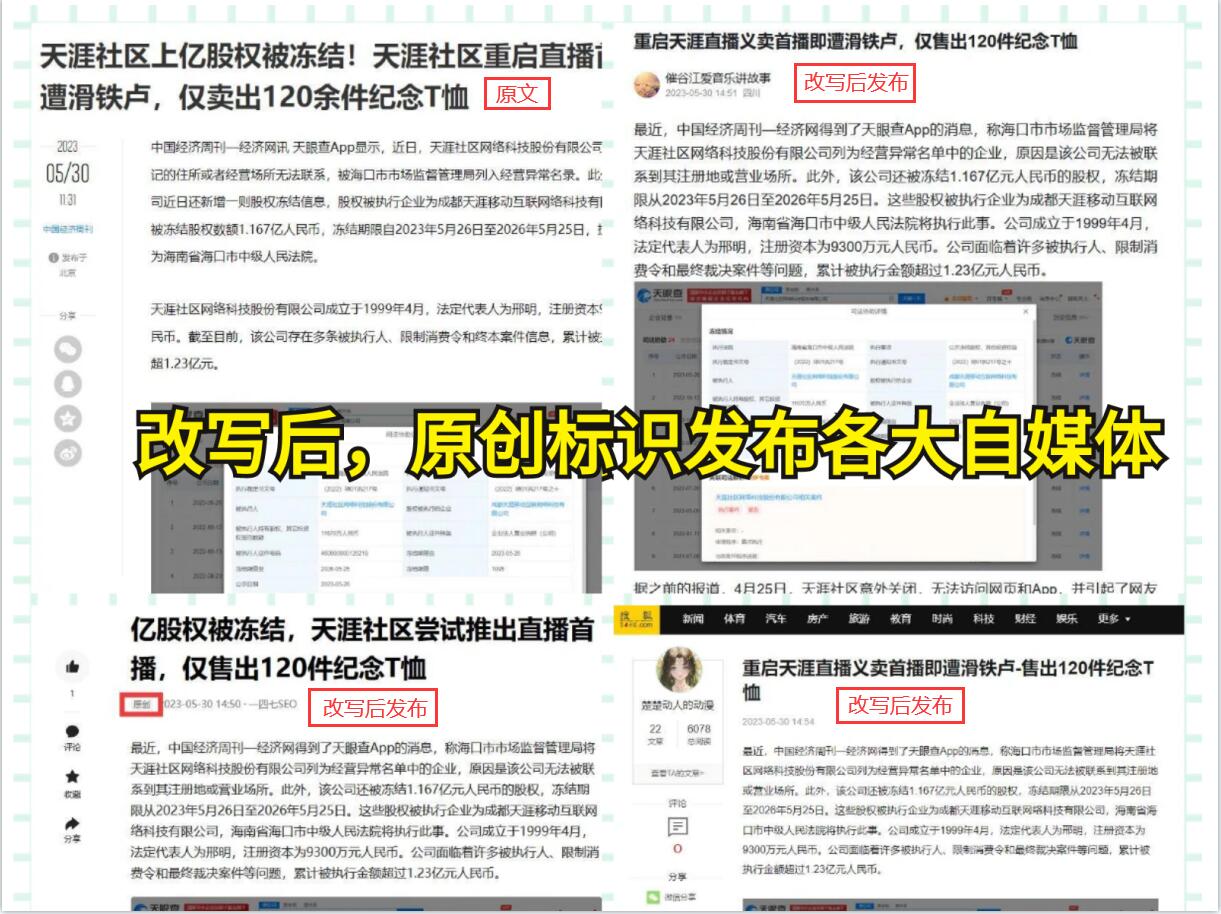
首先,让我们了解一下为什么会有静态网站数据爬取的需求。随着互联网的发展,网站中蕴含着大量的有价值的信息,如新闻、商务数据、科研数据等。然而,这些信息往往被封存在网站中,不易获取和利用。如果能够将这些信息提取出来,并保存为结构化的数据,就可以进行进一步的分析和应用。而静态网站数据爬取正是解决这一需求的有效技术手段之一。
针对静态网站数据的爬取,通常可以分为以下几个步骤。首先,需要选择适合的爬虫工具或编写自定义的爬虫程序。常用的爬虫工具有Scrapy、BeautifulSoup等,可以根据需求选择合适的工具。其次,需要确定目标网站,并分析该网站的结构和数据位置。了解目标网站的结构可以帮助我们编写相应的筛选规则,提高数据爬取的效率和准确性。然后,根据网站的结构和筛选规则,编写相应的爬虫程序。程序可以通过HTTP请求获取网页HTML,并解析HTML结构,提取出所需的数据。最后,根据爬取到的数据,进行数据清洗和处理,将其保存为结构化的数据文件,如CSV、JSON格式。这样,就完成了静态网站数据的爬取过程。
静态网站数据爬取在很多领域都有着广泛的应用。比如,新闻媒体可以通过爬取各大新闻网站的数据,进行舆情分析和新闻事件跟踪;电商pingtai可以爬取竞争对手的产品信息,进行价格监测和市场分析;科研人员可以通过爬取文献数据库的数据,进行学术研究和数据挖掘。通过静态网站数据爬取,可以大大提高数据的获取效率和质量,为决策和应用提供有效的支持。
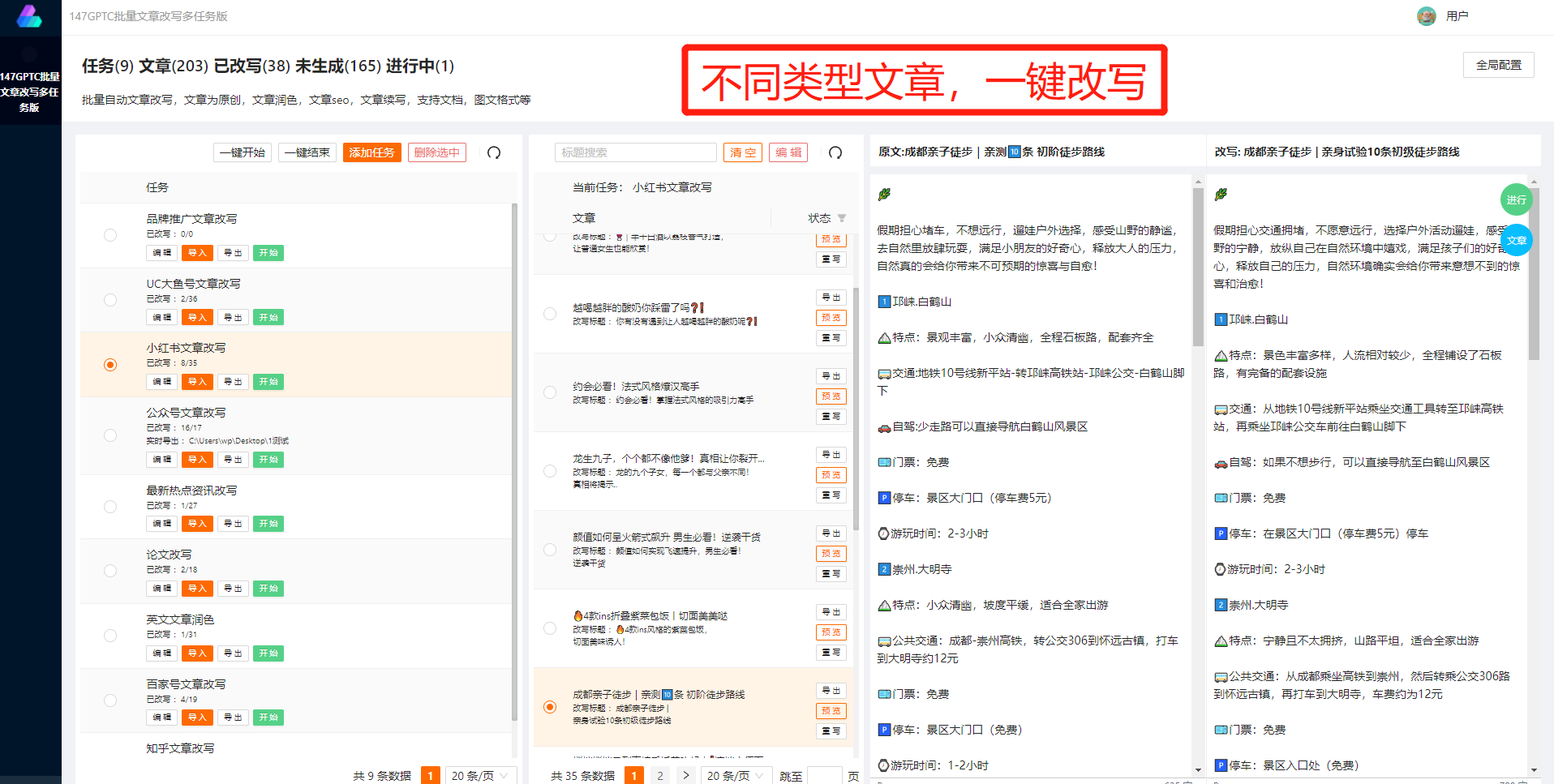
总之,静态网站数据爬取是一种重要的数据采集技术,可以让手中的信息在指尖舞动。通过选择合适的爬虫工具,编写爬虫程序,并进行数据清洗和处理,我们可以轻松地获取到网站中有价值的数据。这些数据可以帮助我们进行舆情分析、市场调研等工作,为决策和应用提供有力支持。希望本文对大家了解静态网站数据爬取有所帮助,欢迎大家积极尝试并应用该技术,让你的手中信息更有价值!
147SEO » 静态网站爬取数据:让手中信息在指尖舞动




