
在当今大数据时代,爬虫技术被广泛应用于数据抓取和挖掘。使用爬虫能够快速、自动地从互联网中收集所需数据,并为我们提供数据分析、处理和决策支持。然而,数据抓取的一大难题是如何高效地保存爬取到的数据。
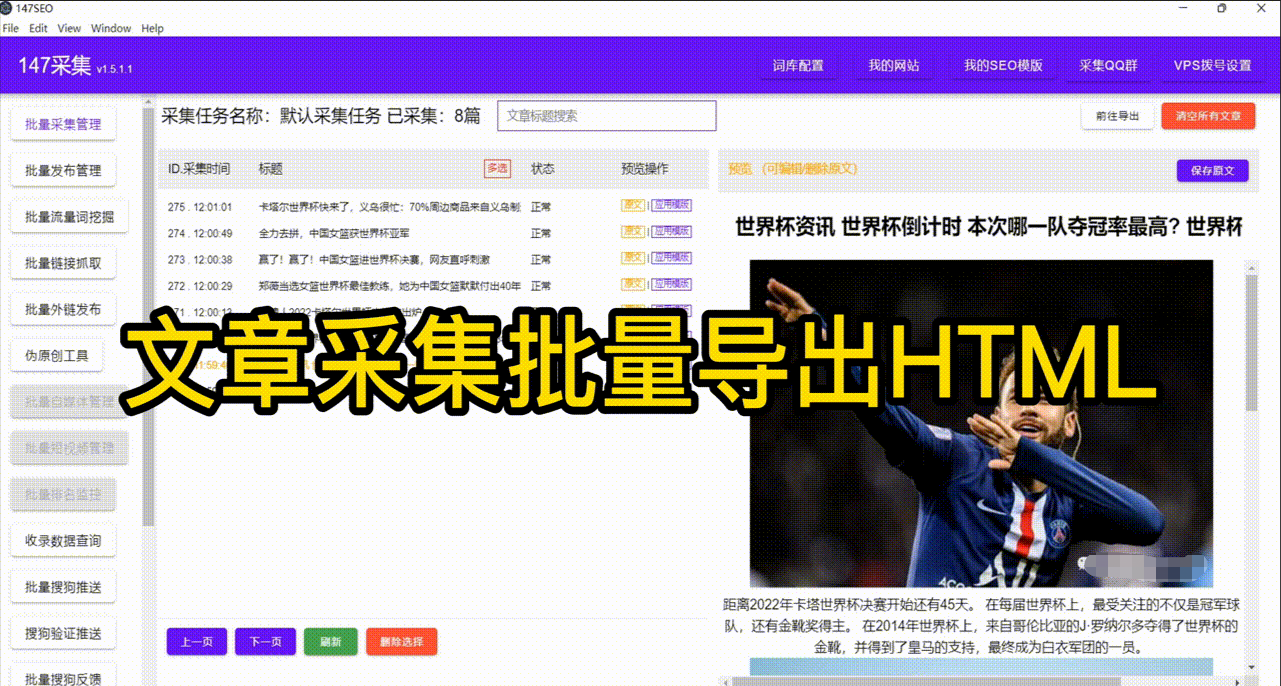
在实际应用中,我们需要考虑以下几个方面来保存爬虫爬取到的数据:
一、选择合适的数据存储方式 爬虫抓取到的数据通常是以结构化或非结构化的形式存在。常见的数据存储方式包括关系数据库、NoSQL数据库和文件储存等。根据数据的特点和使用场景,我们可以选择合适的数据存储方式。例如,对于结构化数据,可以选择关系数据库;对于非结构化数据,可以选择NoSQL数据库或文件储存。
二、数据预处理与清洗 爬虫抓取到的数据往往包含一些噪声和无效信息,需要进行数据预处理和清洗。预处理包括去除重复数据、解决数据格式问题、处理缺失数据等。清洗数据可以通过编写数据清洗脚本或使用数据清洗工具来实现,以保证数据质量和准确性。
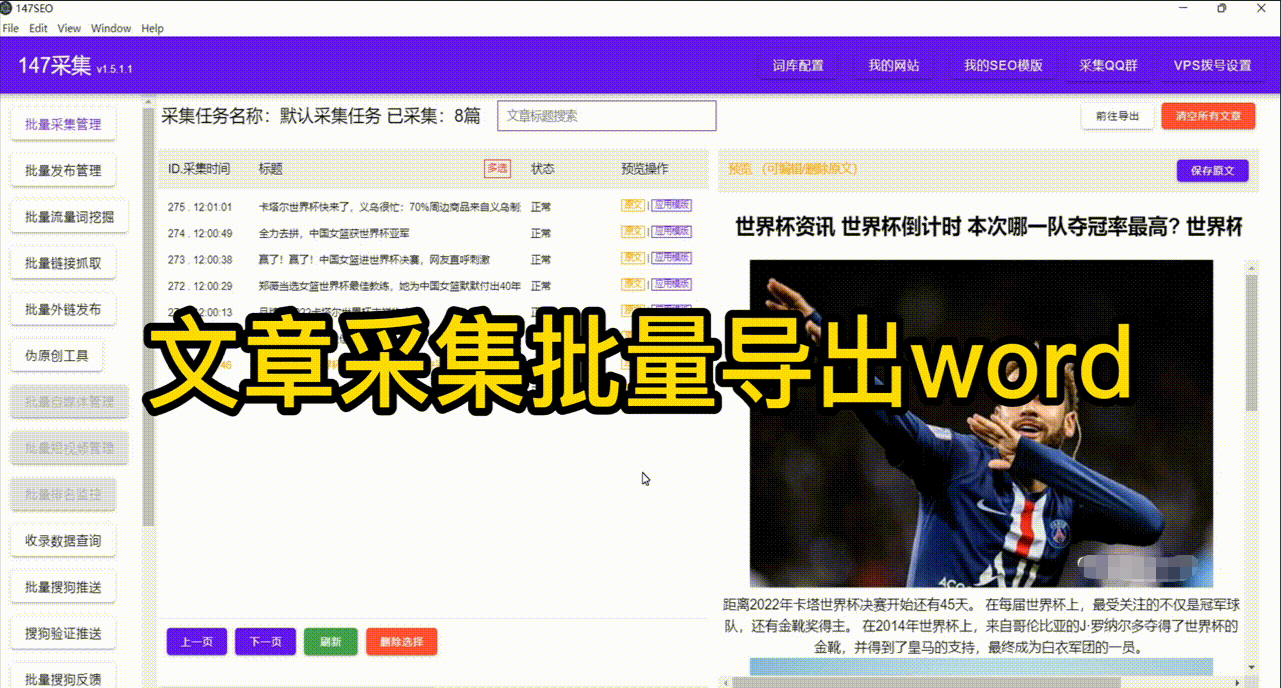
三、数据备份和恢复机制 爬虫抓取的数据是宝贵的资产,因此需要建立数据备份和恢复机制。备份数据可以防止数据丢失或损坏,恢复机制可以在系统宕机或数据丢失时恢复数据。常用的数据备份方式包括定期备份、增量备份和冷备份等。
四、数据安全和权限管理 爬虫抓取到的数据可能包含敏感信息,如个人身份信息、银行账户等。因此,数据安全和权限管理是非常重要的。可以通过数据加密、访问控制、用户认证、数据脱敏等手段来保证数据的安全性和隐私性。
五、数据索引和检索 当数据量较大时,如何快速准确地检索和查找数据也是一个关键问题。可以使用全文索引、分词技术和搜索引擎等工具来实现数据的索引和检索功能,以提高数据的查询效率和用户体验。
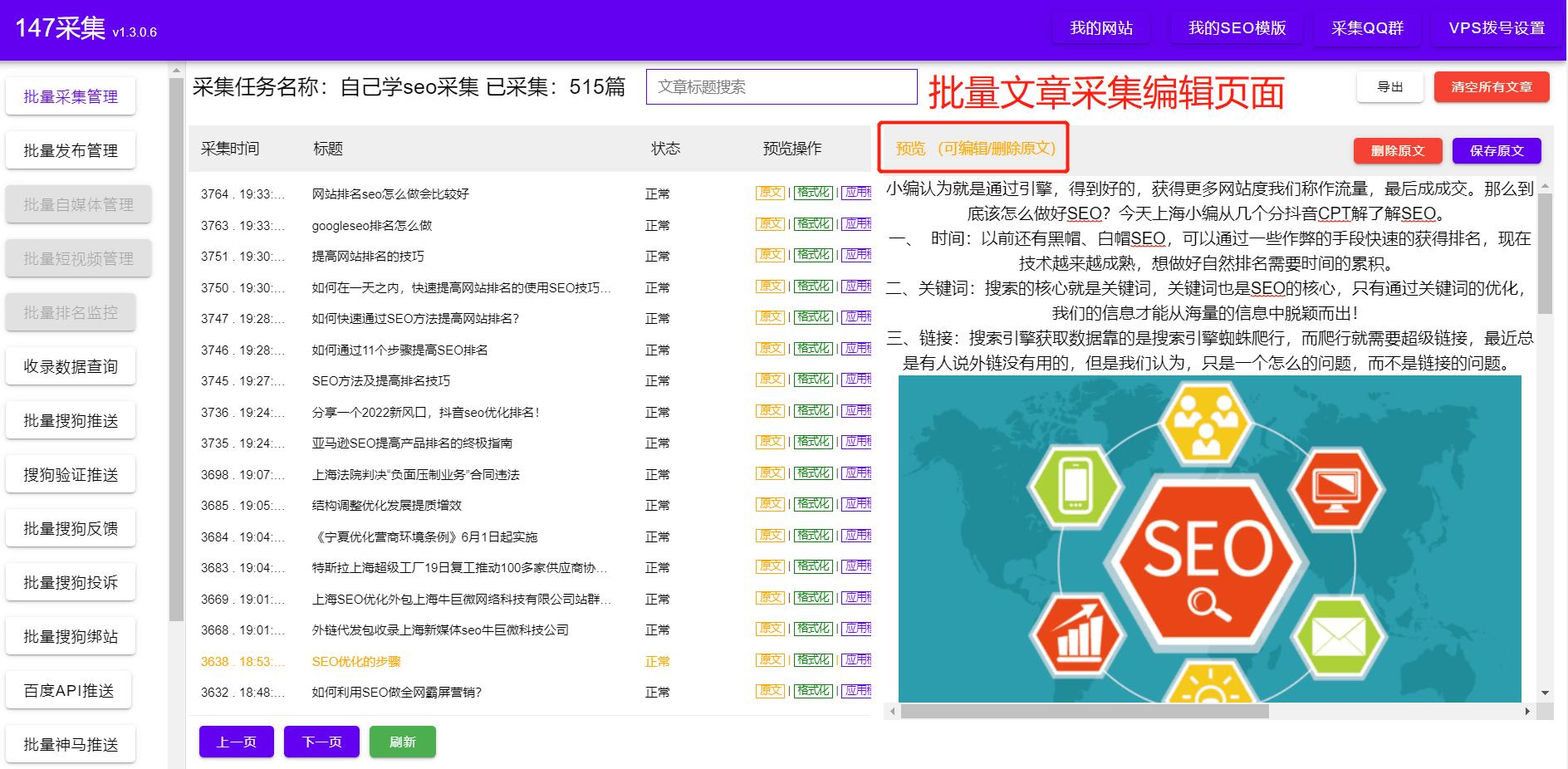
六、数据分析与应用 最终目的是将爬取到的数据应用于数据分析和决策支持。可以使用数据挖掘、机器学习和大数据分析等技术对数据进行分析,提取有价值的信息和模式。通过数据分析,可以洞察市场动态、预测趋势、优化业务流程等,为企业的发展提供引导和支持。
综上所述,保存爬虫爬取到的数据需要综合考虑数据存储方式、数据预处理、数据备份和恢复、数据安全和权限管理、数据索引和检索、数据分析和应用等方面。只有合理规划和实施这些措施,才能更好地保护和利用爬虫爬取到的数据。



