
在日常工作中,处理大量数据变得越来越普遍。然而,手动收集和整理这些数据不仅费时费力,还容易出错。为了解决这个问题,许多人开始使用爬虫工具来自动化数据抓取,并将数据保存到Excel中。
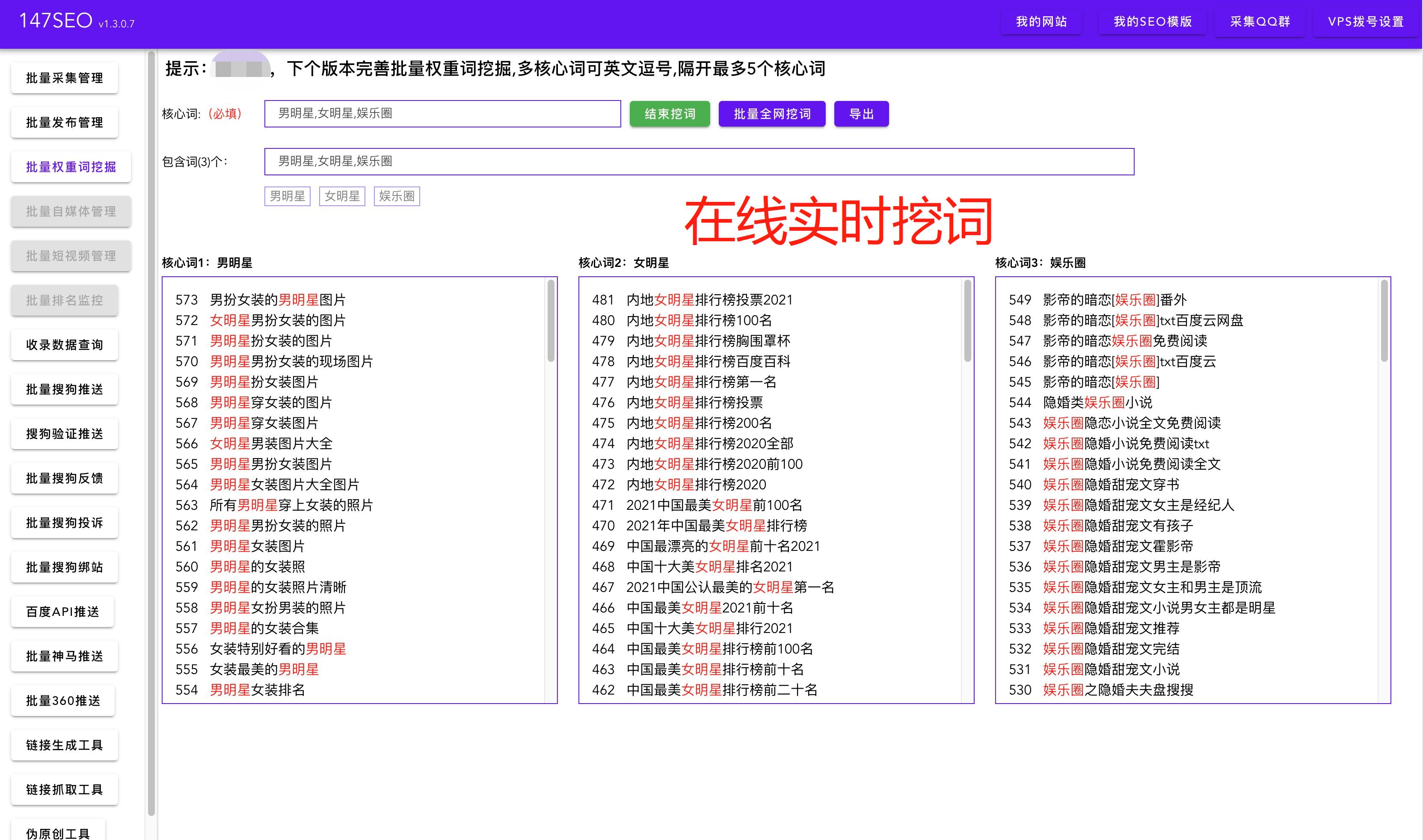
使用爬虫工具抓取数据是一种快速高效的方法。它可以自动化地访问网页,并提取所需的数据。一旦数据被提取出来,我们可以使用Python等编程语言将数据保存到Excel文件中。
首先,我们需要选择合适的爬虫工具。市面上有许多成熟的爬虫框架,如Scrapy、BeautifulSoup等,它们都提供了强大的数据抓取功能。选择适合自己需求的工具,可以大大提高工作效率。
接下来,我们需要设计爬取的规则。通常,我们会通过分析网页的结构和标签,确定需要抓取的数据所在的位置。然后,使用爬虫工具的选择器功能,根据这些规则来提取数据。这些规则可以是CSS选择器、Xpath或正则表达式等。
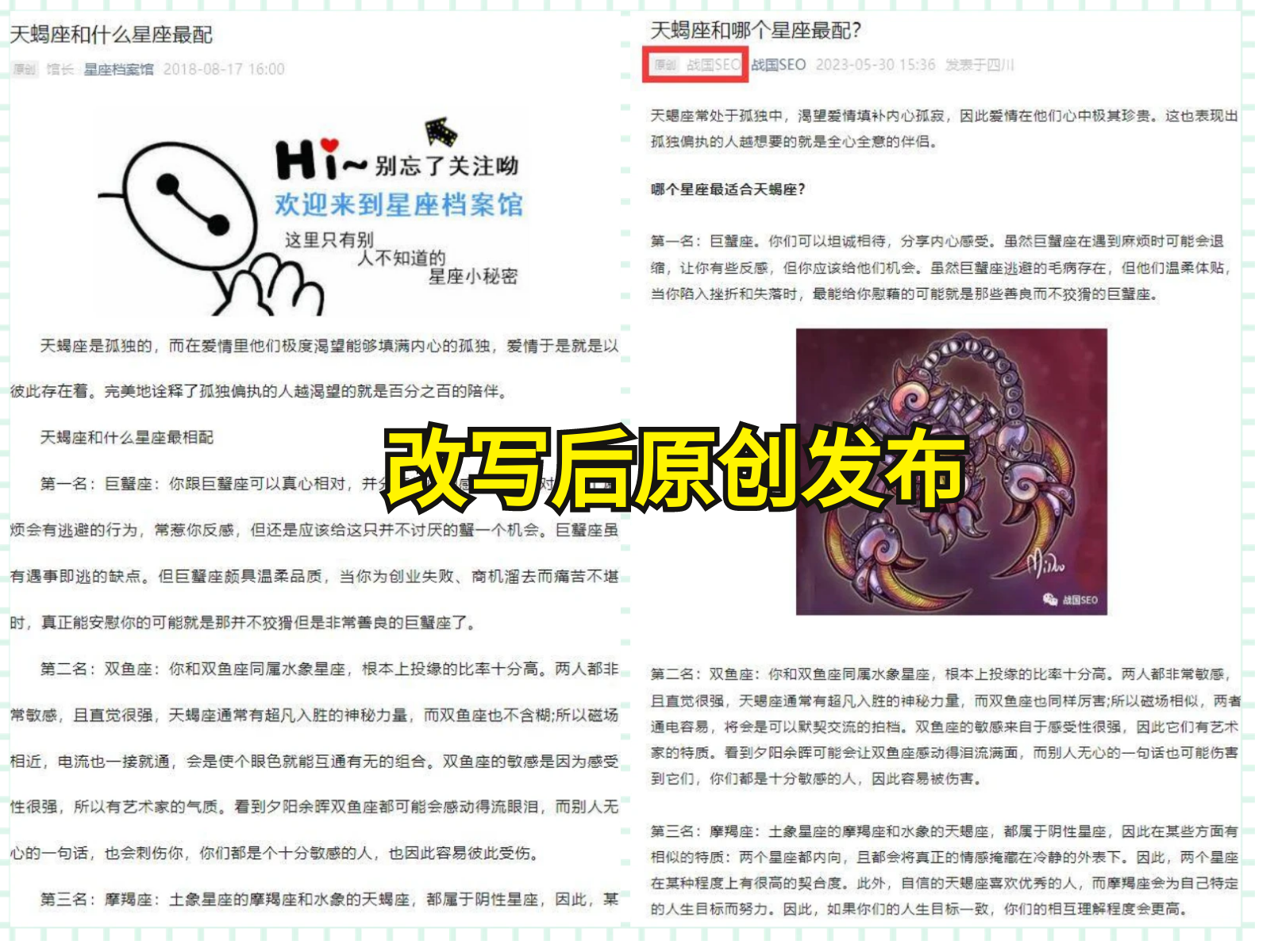
当数据被提取出来后,我们可以通过将其保存为JSON或CSV文件来备份和分析。然而,对于需要进行进一步处理和整理的数据,保存为Excel文件是一个更好的选择。Excel提供了强大的数据处理和分析功能,可以帮助我们更好地管理和可视化数据。
将数据保存到Excel文件中的方法也很简单。Python的pandas库提供了许多用于读写Excel文件的函数和方法。我们可以使用这些函数将数据保存到Excel文件的不同表单和工作簿中。此外,我们还可以设置表头、数据格式、筛选条件等。
通过将数据保存到Excel文件中,我们可以轻松地进行数据清洗、过滤和分析。我们可以使用Excel的排序、筛选、公式、图表等功能,更好地理解和利用数据。此外,我们还可以将Excel文件与其他软件集成,如PowerPoint和Word,以制作演示文稿和报告。
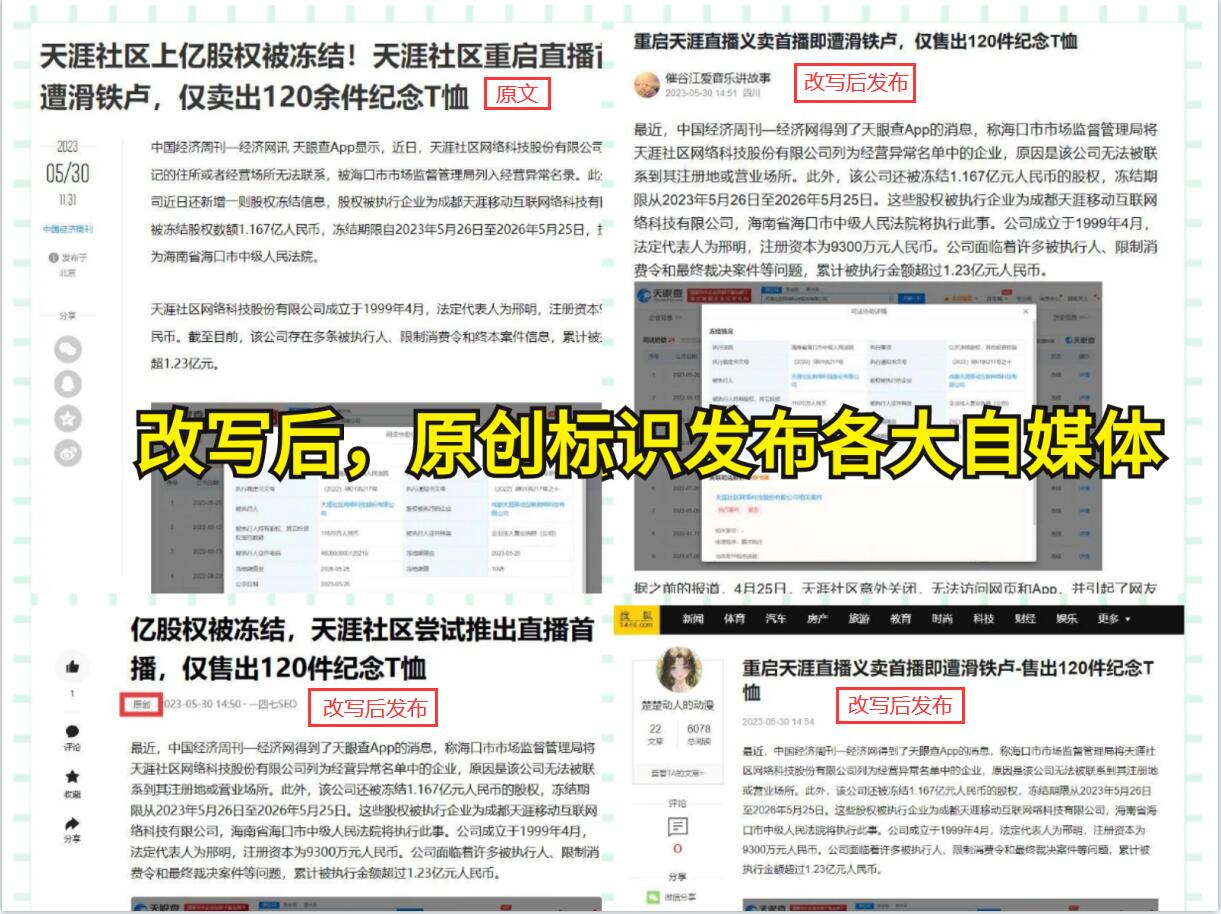
总之,爬虫工具是一个强大的数据抓取工具,可以帮助我们快速、准确地收集大量数据。将数据保存到Excel文件中可以帮助我们更好地管理和分析数据,提高工作效率。如果你还在为处理海量数据而烦恼,不妨尝试使用爬虫工具将数据保存到Excel中,你会发现它是一个利器。



