
数据爬虫是一个广泛应用于互联网领域的技术。它可以帮助我们从各种网络来源中收集和提取数据,并在大数据分析、市场调研、舆情监测等领域发挥重要作用。本文将介绍数据爬虫的基本流程,帮助读者了解和掌握这一强大的技术。
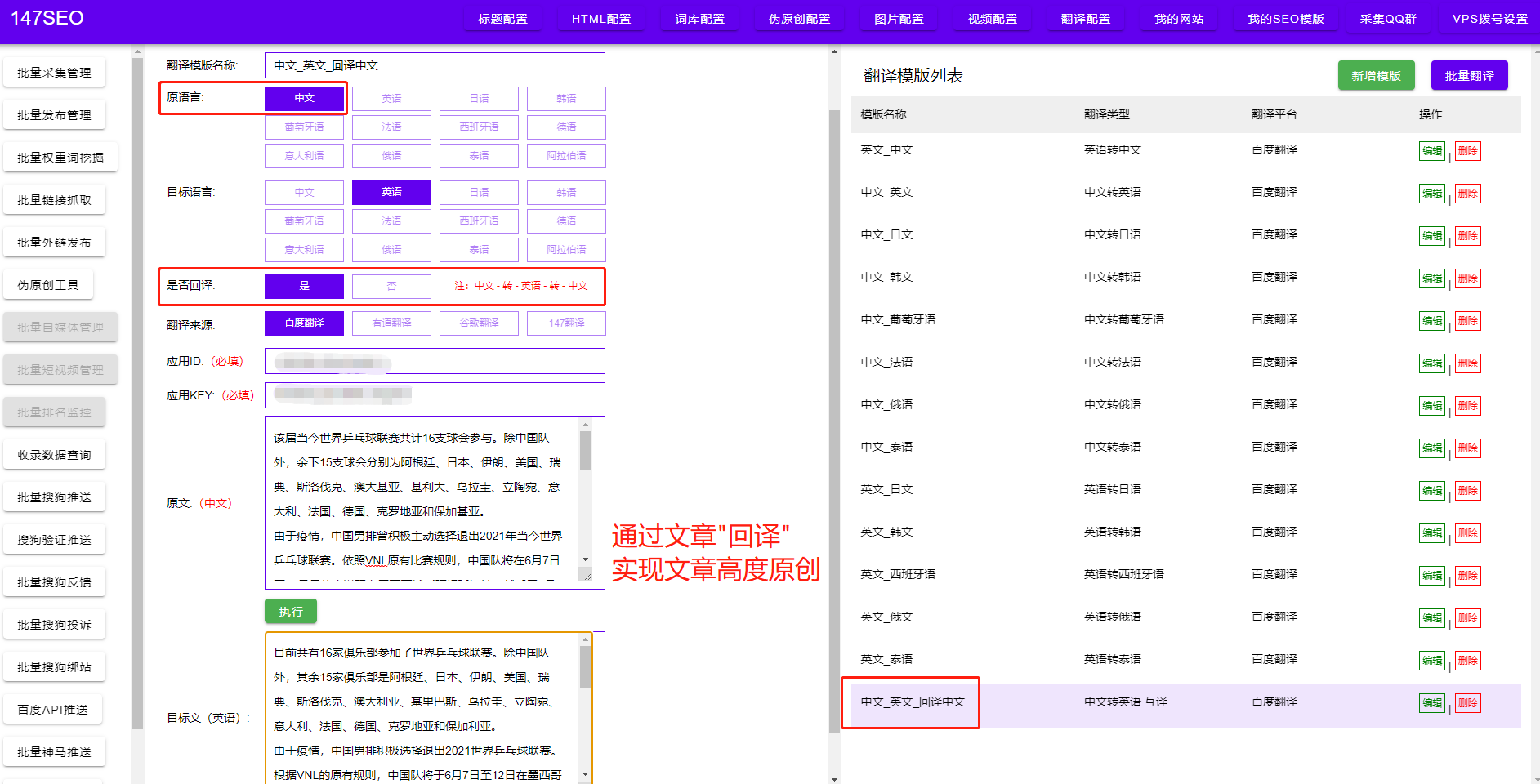
第一步是确定要爬取的目标。在使用数据爬虫之前,我们需要明确我们所需要的数据类型和来源。这可以是一个网站、一个luntan、一个社交媒体pingtai,或者任何其他提供数据的网络ZY。我们需要分析目标的网站结构和页面布局,确定我们要提取的数据位置和内容。
第二步是编写爬虫代码。数据爬虫通常使用编程语言来实现。最常用的语言包括Python、Java和Ruby等。通过编写代码,我们可以告诉爬虫如何浏览目标网站,从中提取数据。我们可以使用各种编程库和工具来帮助我们进行数据抓取和解析。
第三步是发送网络请求并获取数据。爬虫通过模拟网络请求,访问目标网站的页面,并获取页面的HTML源代码。通过分析HTML源代码,我们可以提取我们所需的数据。在这一步中,我们需要处理页面加载延迟、验证码验证等常见的网络访问问题。
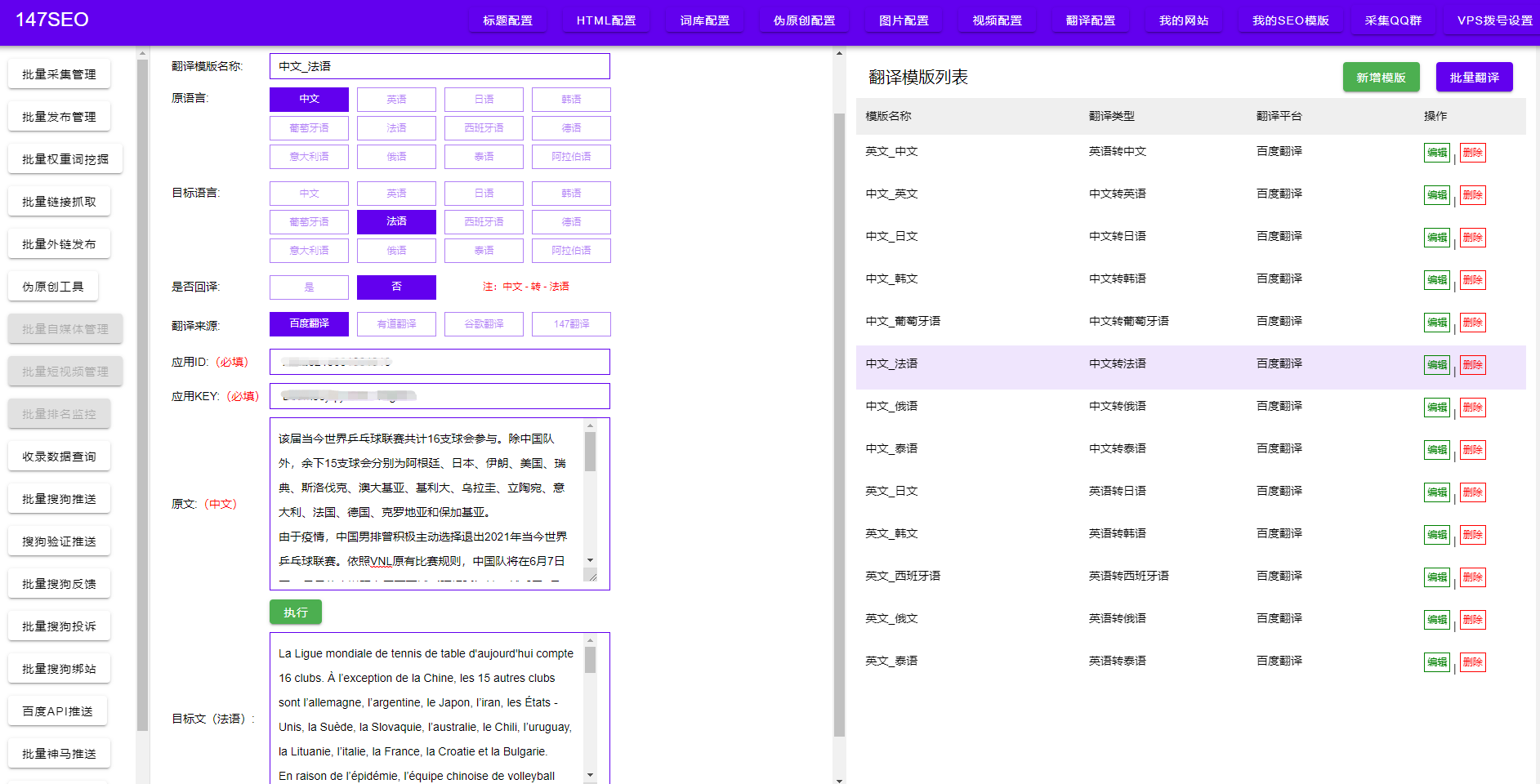
第四步是解析和清洗数据。在获取到页面的HTML源代码后,接下来我们需要将其进行解析和清洗,以提取出我们所需的数据。我们可以使用HTML解析器来解析页面结构,并使用正则表达式或其他方法来清洗数据。在这一步中,我们需要确保数据的准确性和一致性。
第五步是存储和分析数据。获取到的数据可以存储在数据库中,以供后续的数据分析和使用。我们可以将数据保存为结构化的格式,如CSV、JSON或XML等。存储和管理大量数据需要考虑到数据的安全性和可扩展性。
数据爬虫技术在当今信息爆炸的时代具有重要的意义。它可以帮助我们从庞大的数据中获取有用的信息,进行深入的分析和研究。数据爬虫在市场调研、竞争情报、舆情分析等领域有着广泛的应用。通过掌握数据爬虫的基本流程,我们可以更好地利用这一强大的工具,为各种领域的决策提供支持。
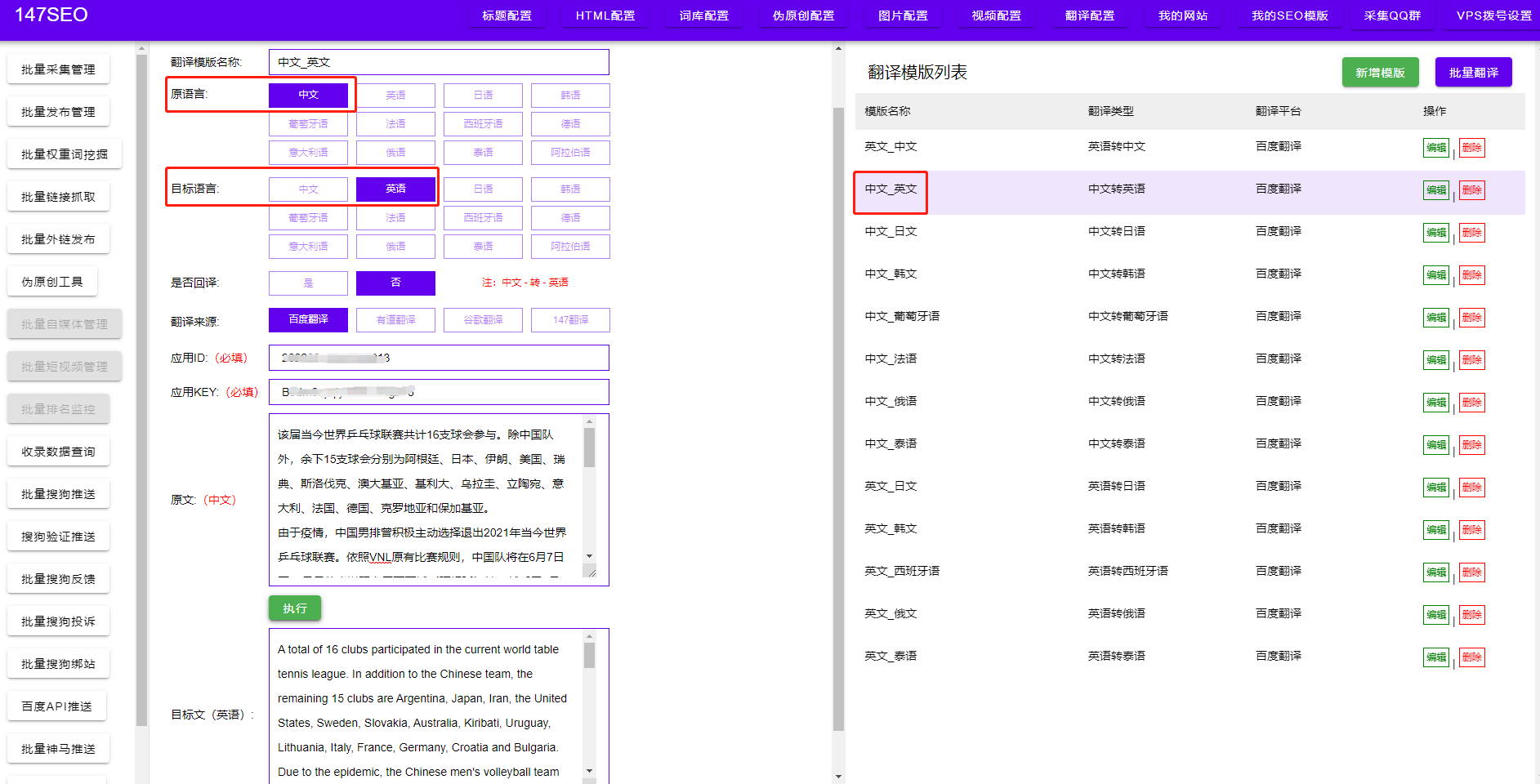
总结起来,数据爬虫是一项具有广泛应用前景的技术。通过掌握数据爬虫的基本流程,我们可以获取大量的网络数据,并进行有效的分析和利用。数据爬虫在信息收集、市场调研和舆情监测中发挥着重要作用。希望本文能帮助读者了解和掌握数据爬虫技术,为未来的数据获取和分析工作提供帮助。



